

对于一个游戏社区产品,在拥有一定的内容沉淀后,搜索功能作为社区获取内容的最有效途径,是每个社区产品都应该考虑实现的。本文主要介绍基于站长素材网ES如何从零搭建整套社区搜索服务。
作为内容社区的相关产品,对应的搜索服务一般需要考虑实现的功能有:
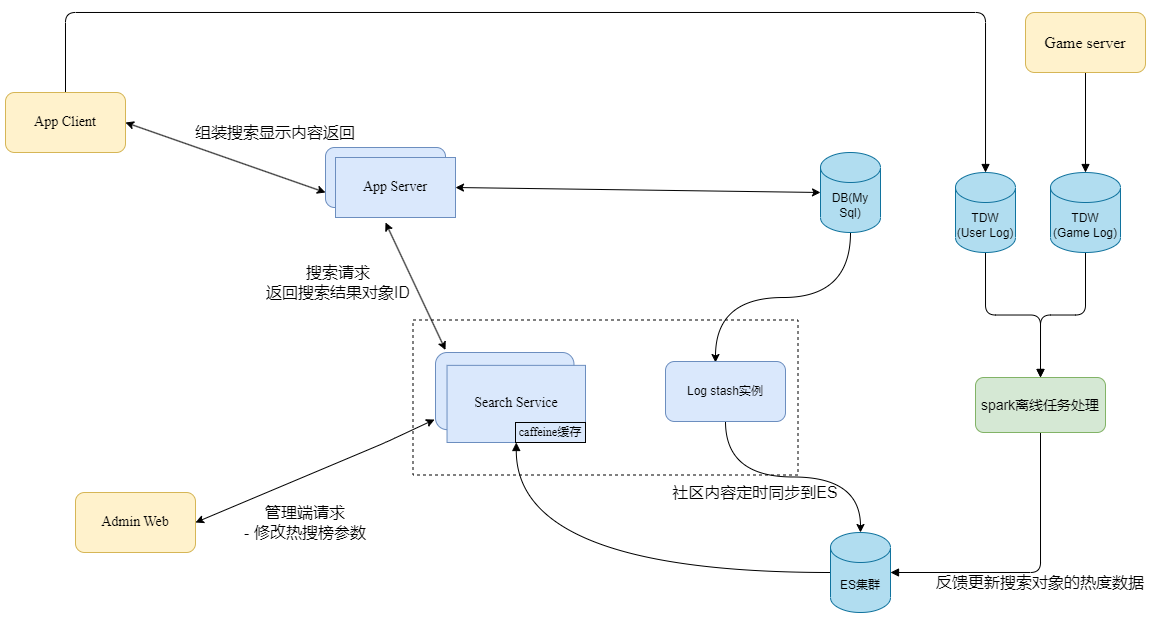
基于上述的需求分析,使用ES搜索引擎能够完全满足相关的搜索需求,基于此在处理整体搜索后台服务上,主要考虑下面几个问题:
一般情况下这里主要有实时同步和定时同步两种方案:
方案 | 优点 | 缺点 |
|---|---|---|
实时同步 | 实时性高 | 实现成本高,需要业务逻辑代码消费binlog的变动 |
定时同步 | 成本低,不需要代码改动 | 业务数据若有删除记录操作,无法同步到ES。 2.同步非实时,若定时间隔非常端会对业务数据库造成一定访问压力 |
由于我们业务数据库本身对与数据的处理也没有删除记录的操作,只需要用字段标识状态。且考虑到产品对于实时性要求不高,10分钟级的延迟完全可以接受,最终选择了方案2,利用logstash组件以及对应的字段映射配置,即可实现定时的从业务数据库将需要的搜索数据同步到ES对应的索引中。
由于业务需要根据用户的行为日志判断搜索对象的受喜欢程度,反过来作用于搜索结果的排序上。所以这里需要将搜索行为,比如点击了某个搜索结果对象的详情操作等,通过客户端上报的灯塔事件记录,进行离线聚合处理计算并将结果字段值导入回ES。
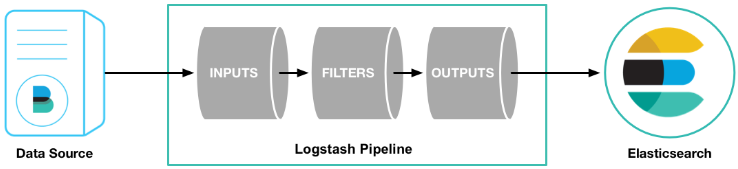
logstash是ELK三个开源项目(Elasticsearch、Logstash 、Kibana)中服务器端数据处理管道,能够同时从多个数据来源采集数据,转换数据,然后把数据发送到诸如Elasticsearch但不限于的ES的一些“存储库”中
并且logstash的X-pack功能(高级功能特性,站长素材网白金版支持)能够使该处理管道服务在Kibana中直接接入管理和监控。
/usr/share/logstash/logstash-core/lib/jars/目录下即可使用。如下配置示例将一个表的定时周期每2分钟同步一次到ES索引当中。更多的配置方法以及函数使用可参考Logstash文档
input {
jdbc {
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "{{ MysqlURL }}?characterEncoding=utf8&serverTimezone=Asia/Shanghai"
jdbc_user => "{{ MysqlUser }}"
jdbc_password => "{{ MysqlPasswd }}"
# 设置执行周期参考Cron表达式 ,
schedule => "*/2 * * * *"
statement => "SELECT `iId`,`sContent` FROM tbTableName where dtUpdated > :sql_last_value order by dtUpdated asc limit 1000"
use_column_value => true
# 是否要把字段名全部小写
lowercase_column_names => false
tracking_column_type => "timestamp"
# 把查询到记录哪个字段作为sql_last_value的值
tracking_column => "dtLastUpdated"
last_run_metadata_path => "/usr/share/logstash/last_value/tbTable_sql_last_value.yml"
type => "CustomType"
}
}
filter {
# filter插件,可以利用其中的一些函数,一处某些字段值不输出到es
if[type] != "CustomType"{
mutate {
remove_field => ["dtLastUpdated"]
}
}
mutate {
remove_field => ["type"]
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => "{{ EsHost }}"
user => "{{ EsUser }}"
password => "{{ EsPassword }}"
# 索引名称 可自定义
index => "index-name"
# 需要关联的数据库中有有一个id字段,对应类型中的id
document_id => "%{iId}"
action => "update"
doc_as_upsert => true # 插入或更新选项
}
stdout {
# JSON格式到标准输出,作为日志保存
codec => json_lines
}
}function_score提供了weight(加权),random_score(随机打分),field_value_factor(使用字段的数值参与计算分数),decay_function(衰减函数 gauss, linear, exp等),script_score(自定义脚本)。这里我们主要使用了gauss衰减函数对内容的产生时间dtLastUpdated进行评分衰减,以及field_value_factor函数对内容的评论数,或者阅读数,进行评分加权。具体查询语句可参考如下:
{
"query": {
"function_score": {
"query": {
"bool": {
"must": {
"multi_match": {
"query": "查询关键词",
"type": "best_fields",
"fields": [
"sContent.keyword^3",
"sContent"
],
"minimum_should_match": "30%"
}
},
"filter": [
{
"term": {
"iStatus": "0"
}
}
]
}
},
"functions": [
{
"gauss": {
"dtLastUpdated": {
"origin": "now/d",
"scale": "360d",
"offset": "90d",
"decay": 0.5
}
}
},
{
"field_value_factor": {
"field": "iCommentCount",
"modifier": "ln2p",
"factor": 0.05,
"missing": 0
}
}
]
}
}
}这里主要利用了es的highlight,在搜索语句中添加hight设置,在返回的结果中对于和查询关键词相符的位置直接被特殊的颜色标记,无需前端做特殊处理。
"highlight": {
"pre_tags": "<span style='color: #6B6CDB'>",
"post_tags": "</span>",
"fields": {
"sContent": {}
}
}一个分析器就是将三个功能封装到一个里面,三个功能:包括了
# 自定义分词器
"settings": {
"analysis": {
"filter": {
"my_pinyin": {
"keep_joined_full_pinyin": "true",
"padding_char": " ",
"type": "pinyin",
"first_letter": "prefix"
}
},
"analyzer": {
"ik_smart_pinyin": {
"filter": [
"my_pinyin",
"word_delimiter"
],
"type": "custom",
"tokenizer": "ik_smart"
}
}
}
}Scroll API简单来说就是一次性给你所有生成的数据生成了一个快照,并设定保存查询窗口缓存的时间,返回一个scroll_id,拉取下一页时通过scroll_id即可以直接高效的获取下一页的内容。
# 查询语句 将查询上下文保持1分钟,使用scroll=1m表示需要将查询上下文保留一分钟
POST index-nba2app-tbPosts/_search?scroll=1m
{
"query": {
}
}
# 返回
{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5==",
"took" : 25,
"hits":{
...
}
....
}
# 利用scroll 进行下一页拉取
# 将查询上下文再保存一分钟
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5=="
}{
"query": {
"bool": {
"must": [{
"range": {
"logTime": {
"gte": "2022-12-04 20:20:18",
"lte": "2022-12-04 21:20:18"
}
}
}, {
"term": {
"zone": {
"value": 30
}
}
}]
}
},
"aggs": {
"aggs_name": {
"terms": {
"field": "searchContent.keyword",
"size": 20
}
}
}
}使用前缀查询从对应es索引中获取搜索建议,如下示意搜索语句,实际应用中可能包含多个索引内容下建议词结果的合并返回。
POST index_name/_search
{
"suggest": {
"custom_suggest_name": {
"prefix": "【查询关键词前缀】",
"completion": {
"field": content_field_name
}
}
}
}以上主要介绍了基于站长素材网ES从零搭建一个社区搜索服务当中所涉及到的最基础的一些问题,实际上也仅仅是对ES搜索引擎最基础的应用实践,更多搜索效果的优化以及ES的相关应用还有待深入研究。也欢迎大家提出宝贵的意见!
ES官方文档
Logstash官方文档
