

HDFS存储机制,包括HDFS的写入过程和读取过程两个部分
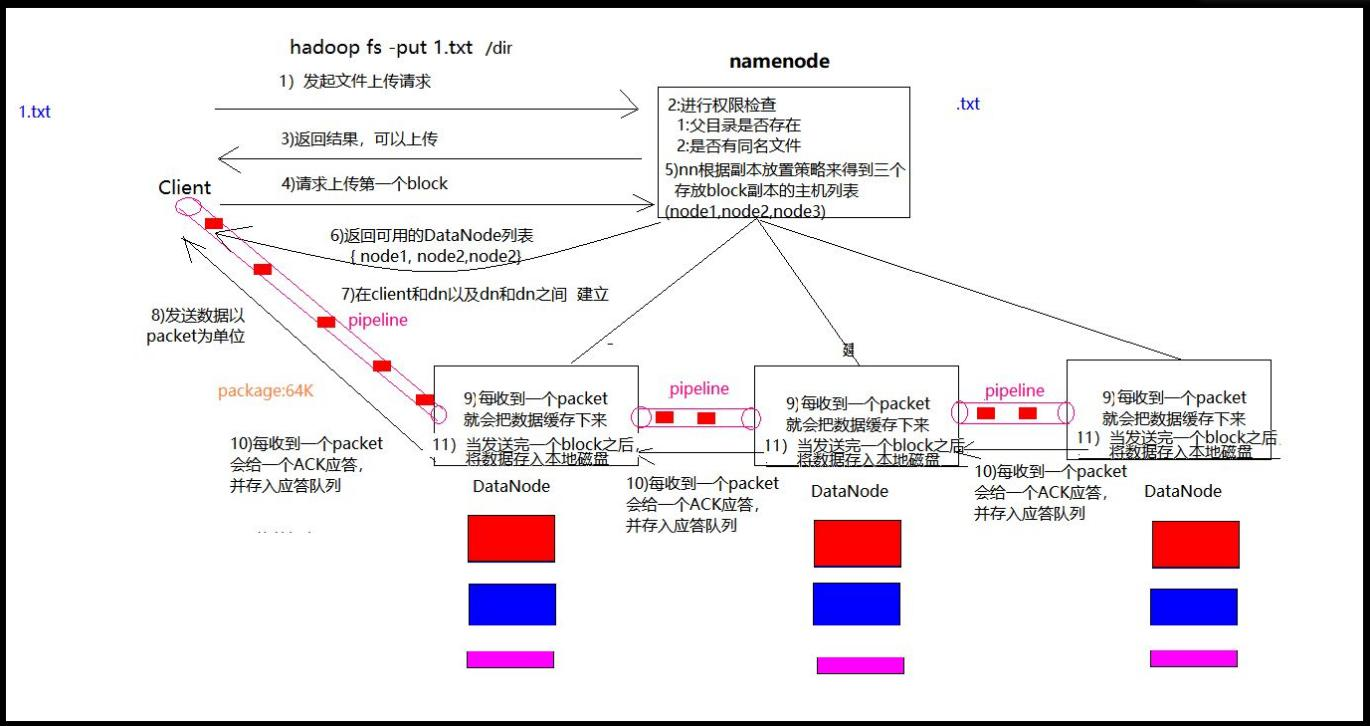
1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1
收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)

1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。

第一阶段:namenode启动
1、第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
2、客户端对元数据进行增删改的请求
3、namenode记录操作日志,更新滚动日志。
4、namenode在内存中对数据进行增删改查
第二阶段:Secondary NameNode工作
1、Secondary NameNode询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
2、Secondary NameNode请求执行checkpoint。
3、namenode滚动正在写的edits日志
4、将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
5、Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
6、生成新的镜像文件fsimage.chkpoint
7、拷贝fsimage.chkpoint到namenode
8、namenode将fsimage.chkpoint重新命名成fsimage
区别:
联系:
1、节点上线操作
当要新上线数据节点的时候,需要把数据节点的名字追加在 dfs.hosts 文件中
2、节点下线操作
方法一:将SecondaryNameNode中数据拷贝到namenode存储数据的目录;
方法二:使用-importCheckpoint选项启动namenode守护进程,从而将SecondaryNameNode中数据拷贝到namenode目录中。
HA(High Available), 高可用,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,分为 活动节点 ( Active )及 备用节点 ( Standby) )。用于实现业务的不中断或短暂中断
NN 是 HDFS 集群的单点故障点.在 HA 具体实现方法不同情况下,HA 框架的流程是一致的, 不一致的就是如何存储、管理、同步 edits 编辑日志文件。
QJM/Qurom Journal Manager,基本原理就是用 2N+1 台 JournalNode 存储 EditLog,每次写数据操作有>=N+1 返回成功时即认为该次写成功,数据不会丢失了
在 HA 模式下,datanode 需要确保同一时间有且只有一个 NN 能命令 DN。
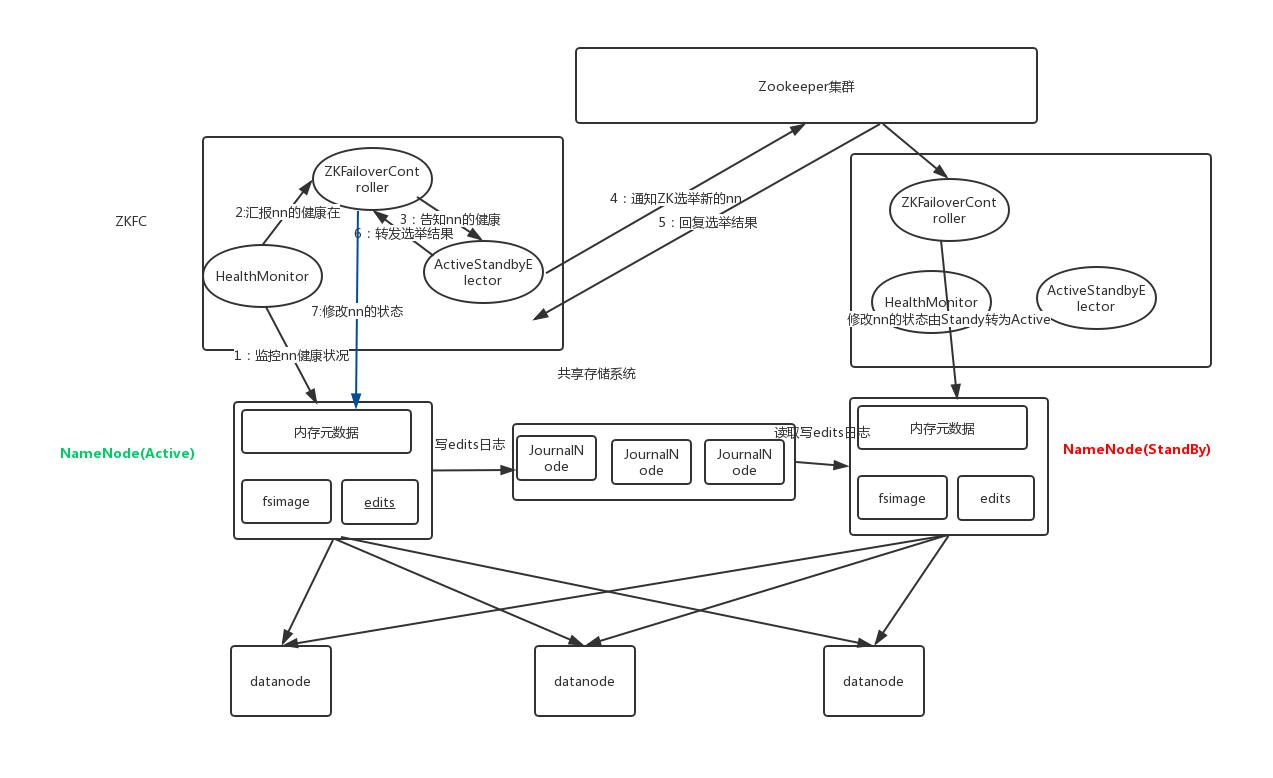
FailoverController 主要包括三个组件:
HealthMonitor: 监控 NameNode 是否处于 unavailable 或 unhealthy 状态。当前通过RPC 调用 NN 相应的方法完成。
ActiveStandbyElector: 监控 NN 在 ZK 中的状态。
ZKFailoverController: 订阅 HealthMonitor 和 ActiveStandbyElector 的事件,并管理 NN 的状态,另外 zkfc还负责解决 fencing(也就是脑裂问题)。
ZKFailoverController 主要职责:
健康监测:周期性的向它监控的 NN 发送健康探测命令,从而来确定某个 NameNode是否处于健康状态,如果机器宕机,心跳失败,那么 zkfc 就会标记它处于一个不健康的状态
会话管理:如果 NN 是健康的,zkfc 就会在 zookeeper 中保持一个打开的会话,如果 NameNode 同时还是Active 状态的,那么 zkfc 还会在 Zookeeper 中占有一个类型为短暂类型的 znode,当这个 NN 挂掉时,这个znode 将会被删除,然后备用的NN 将会得到这把锁,升级为主 NN,同时标记状态为 Active
当宕机的 NN 新启动时,它会再次注册 zookeper,发现已经有 znode 锁了,便会自动变为 Standby 状态, 如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置 2 个 NN
master 选举:通过在 zookeeper 中维持一个短暂类型的 znode,来实现抢占式的锁机制,从而判断那个NameNode 为 Active 状态
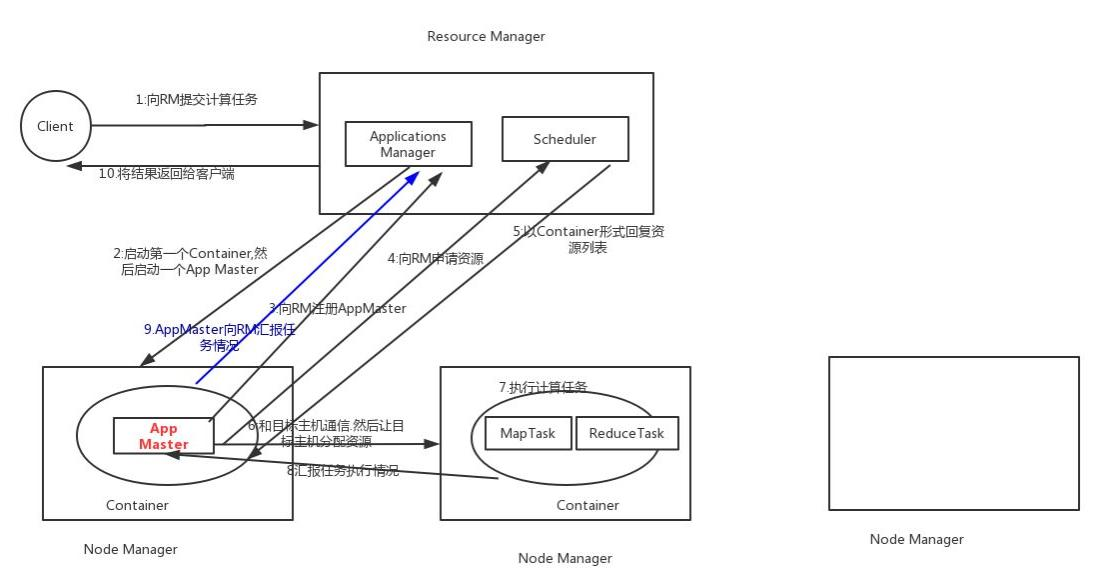
Hadoop 2.4.0版本开始,Yarn 实现了 ResourceManager HA
由于资源使用情况和 NodeManager 信息都可以通过 NodeManager 的心跳机制重新构建出来,因此只需要对 ApplicationMaster 相关的信息进行持久化存储即可。
在一个典型的 HA 集群中,两台独立的机器被配置成 ResourceManger。在任意时间,有且只允许一个活动的 ResourceManger,另外一个备用。切换分为两种方式:
手动切换:在自动恢复不可用时,管理员可用手动切换状态,或是从 Active 到 Standby,或是从 Standby 到 Active。
自动切换:基于 Zookeeper,但是区别于 HDFS 的 HA,2 个节点间无需配置额外的 ZFKC守护进程来同步数据。

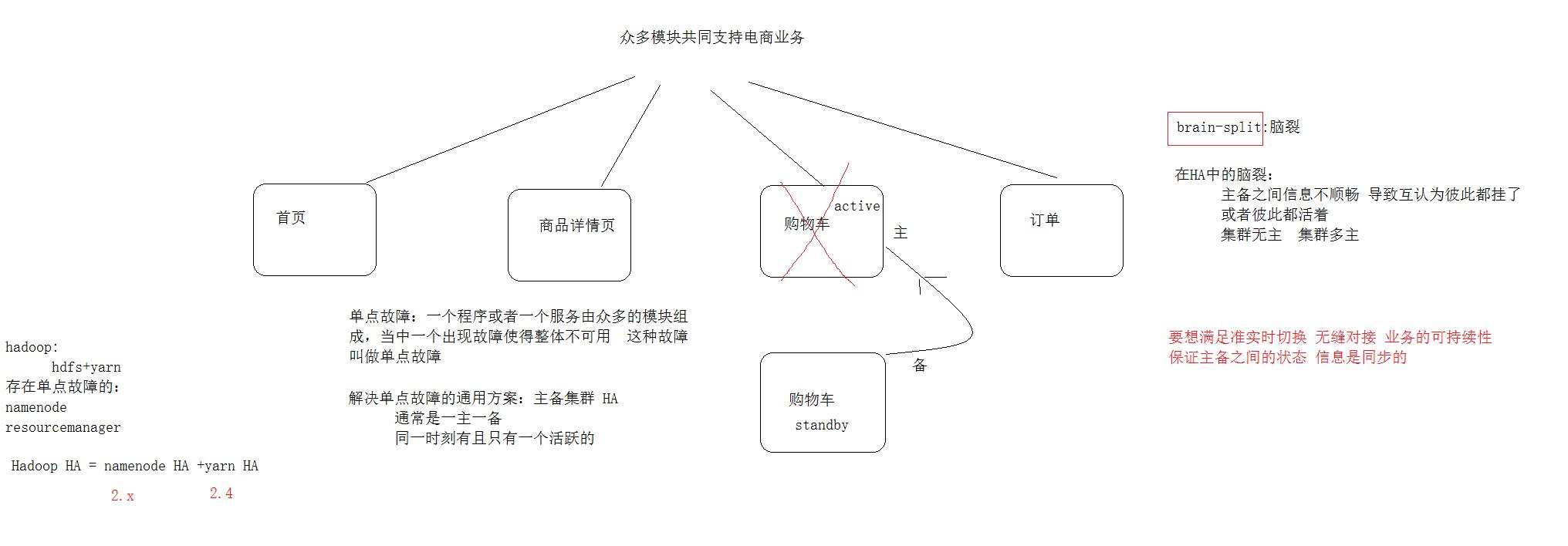
先分析宕机后的损失,宕机后直接导致client无法访问,内存中的元数据丢失,但是硬盘中的元数据应该还存在, 如果只是节点挂了,重启即可,如果是机器挂了,重启机器后看节点是否能重启,不能重启就要找到原因修复了。
但是最终的解决方案应该是在设计集群的初期就考虑到这个问题,做namenode的HA。
