


导读|站长素材网OCR团队在产品性能的长期优化实践中,结合客户使用场景及产品架构对服务耗时问题进行了深入剖析和优化。本文作者——腾讯研发工程师彭碧发详细介绍了OCR团队在耗时优化中的思路和方法(如工程优化、模型优化、TIACC加速等),通过引入TSA算法使用TI-ACC减少模型的识别耗时,结合客户使用场景优化编解码逻辑、对关键节点的日志分流以及与客户所在地就近部署持续降低传输耗时,克服OCR耗时优化面临的环节多、时间短甚至成本有限的问题,最终实现了OCR产品平均耗时从1815ms降低到824ms。希望大家在阅读中能收获一些新的思路。

站长素材网OCR(文字识别)团队收到客户反馈称,站长素材网OCR在服务可用性和准确率方面都表现出色,但服务耗时还有可观的提升空间。因此,我所在的团队决定优化站长素材网OCR服务耗时,为用户提供更快的文字识别服务。
但是耗时优化是一个系统性工程,需要多方的支持和协作。文字识别服务进行耗时优化,主要有以下挑战:
我们成立了专项团队进行攻坚。业务团队从工程优化、模型优化、TI-ACC优化等方面发力,逐步降低服务耗时。优化前平均耗时1815ms,优化后平均耗时824ms,耗时性能提升2.2倍,并最终得到重要客户的肯定。接下来将介绍我们在耗时优化方面的具体实践,希望能给遭遇类似问题的你带来灵感。


OCR服务通过云API接入,内部多个微服务间通过TRPC进行调用。基本架构图如下:
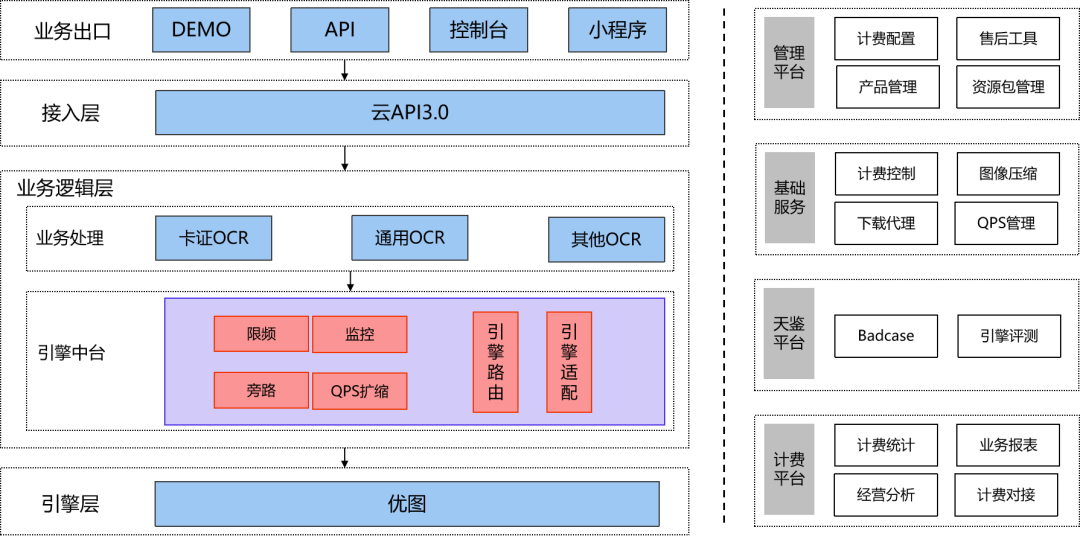
从客户发起请求到OCR服务处理完成主要链路为:
主要涉及到下面几个阶段的耗时:
因此,要优化文字识别服务的整体耗时,就需要从各个阶段进行详细分析和优化。


因为客户生产环境的机器在云服务器上,所以为了保持和客户测试条件一致,我们购买了和客户相同环境的云服务器(含北京、上海、广州)进行模拟测试,详细分析文字识别服务各个阶段耗时。

端到端耗时为客户请求发起直到收到响应的总耗时、客户到站长素材网API接入点以及云API响应给客户存在着公网传输的耗时、从云API接入后就是站长素材网内网链路服务的耗时。端到端耗时主要由客户传输耗时、云API耗时、业务逻辑层耗时、引擎耗时组成,经过多次请求通用OCR后统计各个阶段的平均耗时,具体情况为:
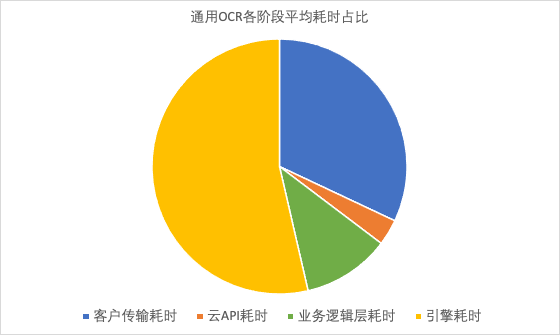
通过详细的各阶段耗时测试可以发现:引擎耗时占主要部分。所以我们会重点优化引擎耗时,这里的主要手段是模型优化和TI-ACC加速。为了做到极致优化,我们还通过日志分流和编解码优化降低了业务逻辑层耗时,同时服务就近多地部署,优化了客户传输耗时。

解决问题
优化之前耗时长度会随着文字字数增加显著变大。引入TSA算法可以明显改善这种情况,从而减少模型耗时。
基于OCR的特点与难点,OCR问题学术界算法可以划分成两大类:基于CTC (Connectionist Temporal Classification)的流式文本识别方案;基于Attention的机器翻译的框架方案。
在基于深度学习的OCR识别算法中,整个流程可以归纳成了四个步骤如下图: 几何变换;特征提取;序列建模;对齐与输出。CTC方案与Attention方案区别主要是在最后一个步骤。它作为衔接视觉特征与语义特征的关键桥梁,可以根据上下文图像特征和语义特征做精确输入、输出的对齐,是OCR模型关键的过程。
针对上述特点与耗时问题,我们提出了TSA文本识别模型。

研究表明,图像对 CNN 的依赖是非必需的。当直接应用于图像块序列时,transformer 也能很好地执行图像分类任务。63%耗时在(BiLSTM+Global Attn,或attention形式)序列建模。

特点1:引入self-attention算法对输入图像进行像素级别建模,并替代RNN完成序列建模。相比CNN与RNN,self-attention不受感受野和信息传递的限制,可以更好地处理长距离信息。
特点2:设计self-attention计算过程中的掩码mask。self-attention天然可以“无视”距离带来的影响,因此需要对输入像素间自注意力进行约束 。其过程如下图所示。

总结:通过multi-head self-attention对序列建模,可以将两个任意时间片的建模复杂度由lstm的O (N)降低到 O(1),预测速度大幅提升。优化后的算法和文本长度无关,对大文本得到成倍的加速提升。
为了进一步降低模型的耗时,我们使用了 TI-ACC进行加速,TI-ACC支持多种框架和复杂场景,面向算法和业务工程师提供一键式推理加速功能。
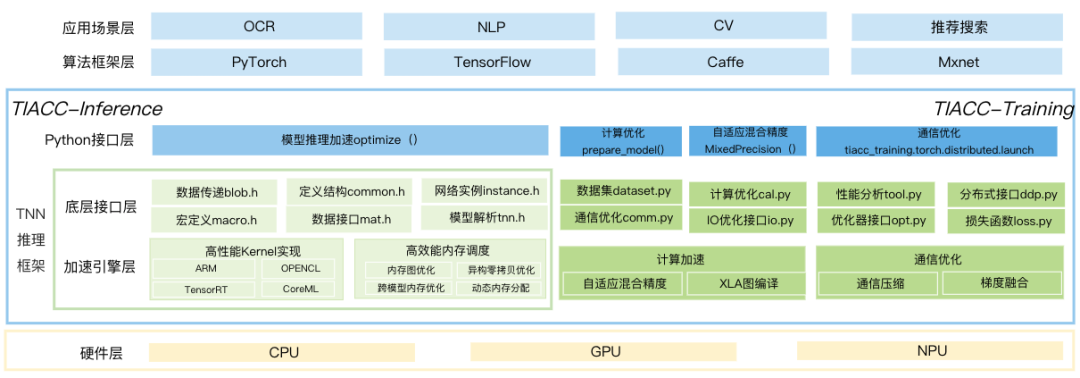
OCR任务可以分为两大类:检测任务和识别任务。检测任务和识别任务一般会保存成两个独立的TorchScript模型,每个任务又分为了多个阶段。通用OCR检测任务包含了backbone(RepVGG等)、neck(FPN等)、head(Hourglass等)等部分。
识别任务包含特征提取部分和序列建模部分。其中特征提取部分既有传统CNN网络,也有最新ResT等基于Transformer的网络。序列建模部分既有传统RNN网络,也有基于Attention的网络。
加速OCR业务模型是对推理加速引擎兼容性的考验。下表分别对比了TIACC和Torch-TensorRT(22.08-py3-patch-v1)对本文模型加速能力:

OCR业务不仅模型结构复杂,模型输入也很有特点。下图显示了本文其中一个模型的输入:
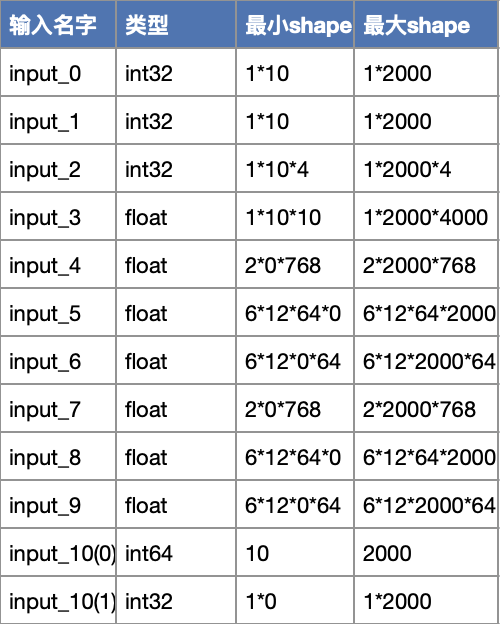
上述输入包括以下特点:输入类型多;输入shape变化范围大;有些最小shape维度是0;输入不仅包含Tensor也包含Tuple。仅仅上述模型输入格式,就会导致一些推理引擎不可用或加速效果不明显。举个例子,TensorRT不支持int64输入、Torch-TensorRT不支持Tuple输入。输入变化范围大会导致推理引擎显存消耗过高,导致某些推理引擎加速失败或无法单卡多路并行推理,进而导致无法有效提升TPS。对于OCR这种大调用量业务,TPS提升可以有效降低GPU卡规模从而带来可观成本降低。
针对OCR模型shape范围过大显存占用量高问题,TIACC能通过显存共享机制有效降低了显存占用。对于动态shape模型,推理加速引擎在部分shape加速明显,部分shape反而会性能降低的问题。TIACC通过重写关键算子、根据模型结构,选择业务全流程最优的算子实现,有效解决了实际业务中部分shape加速明显但整体加速不理想的问题。
通过打磨OCR业务模型,能提升模型的推理延迟。即使多路部署也可以有效提升模型的吞吐。下表显示了TIACC FP16相比libtorch FP16的加速倍数,数字越高越好。

TIACC底层使用了TNN作为基础框架,性能强大。其中TNN是优图实验室结合自身在AI场景多年的落地经验,也是向行业开源的部署框架。TIACC基于TNN最新研发的子图切分功能基础上做产品化封装,为企业提供 AI 模型训练、推理加速服务。它显著提高模型训练推理效率,降低成本。
文字识别采用微服务架构设计,整体服务链路长。其中涉及到TRPC、HTTP、Nginx-PB协议的转换和调用,所以请求和响应需要有很多的编解码操作。文字识别场景下,请求和响应包体都非常大,RPC协议之间的转换和编解码增加了计算耗时。为了进一步降低服务耗时,我们对这些编解码操作进行了整体的优化,减少了协议转换和编解码次数。

在业务中有很多关键节点需要记录日志,便于问题定位。在文字识别业务场景下,日志需要脱敏处理大量识别出的文本数据,写入速度慢。为了避免日志操作影响服务响应耗时,我们设计了日志分流上报服务,将日志操作全部通过异步流程上报到其他微服务完成,减少主逻辑耗时。
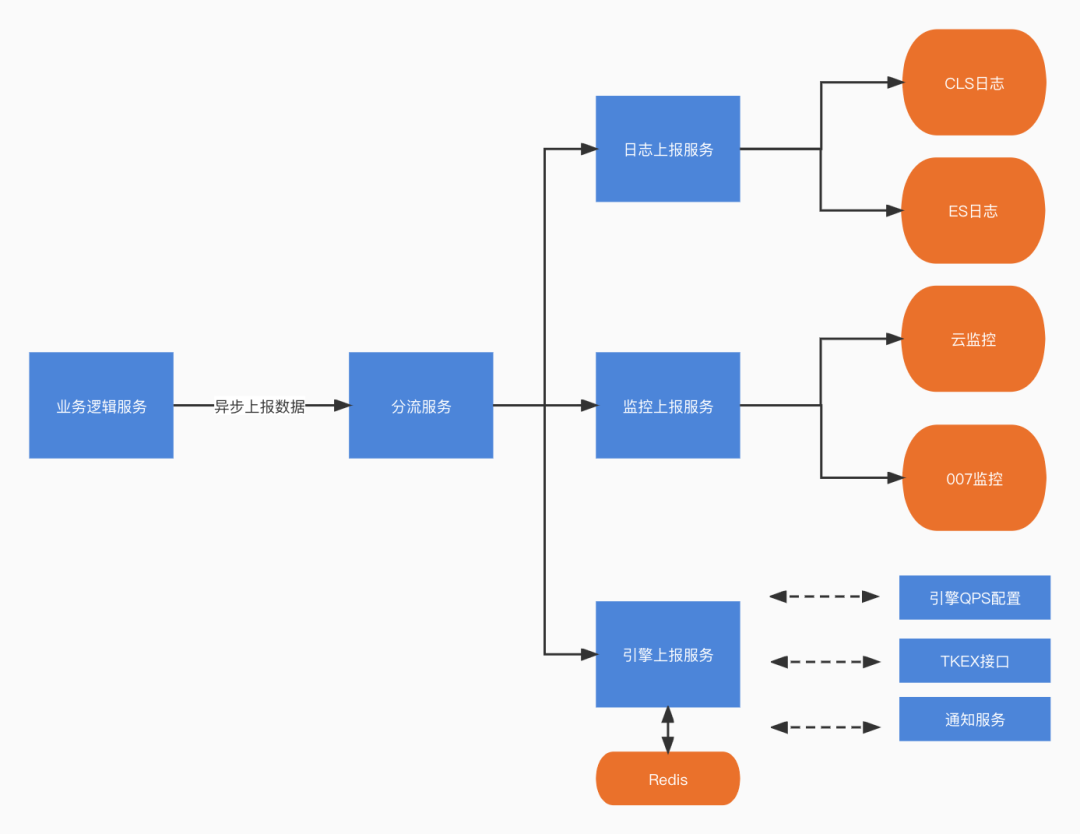
经过多次详细测试文字识别业务在北京、上海、广州区域机器发起请求的耗时差异,我们对跨地域传输耗时有了比较明确的认识。服务跨地域请求时(比如在北京发起请求,实际服务部署在广州),会存在很大的传输耗时波动,客户的使用体验会下降。因此我们针对通用OCR接口进行了就近多地部署,在服务部署的架构上对耗时进行了优化。
在文字识别跨地域请求时,我们进行多地部署。通用OCR接口线上多地部署发布以后,我们对线上云API记录的总耗时监控进行了观察和对比,耗时有了很明显的下降——某段时间内耗时从平均1100ms下降到800ms,下降了300ms。

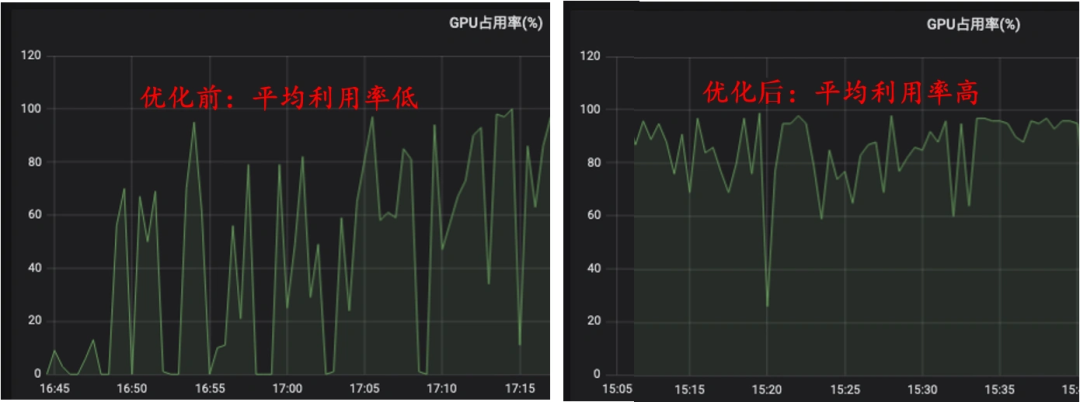
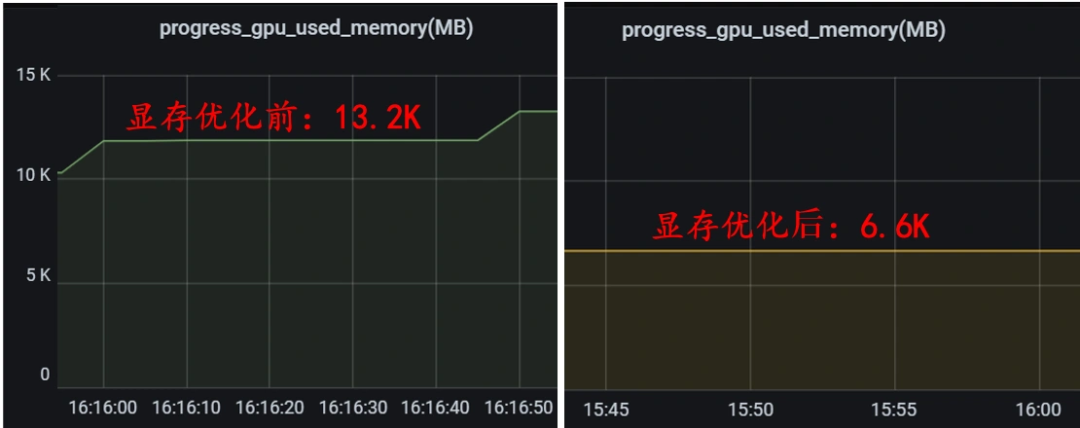
随着OCR业务功能点越来越多,业务中使用的AI模型越来越多且更复杂,所以对显存的要求也越来越大。显卡显存大小影响服务能开启并发数,而并发数影响服务的吞吐——所以显存往往成为业务吞吐量的瓶颈。

显存管理主要就是解决上述问题。其主要思想是解耦合显存占用大小跟服务并发路数之间的关系,提高并发路数不再导致显存增大,进而提升服务整体吞吐量;由服务路数实现并行方式转换为不同模型之间并行方式,提高了GPU计算的并行度,更好的充分利用GPU资源。以通用OCR为例,下图可以看使用前后GPU利用率变化和显存占用变化。

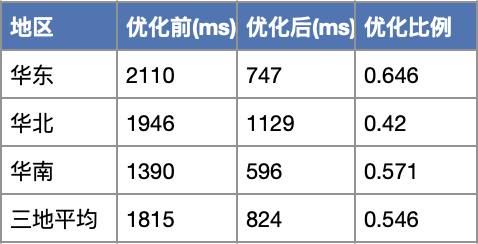
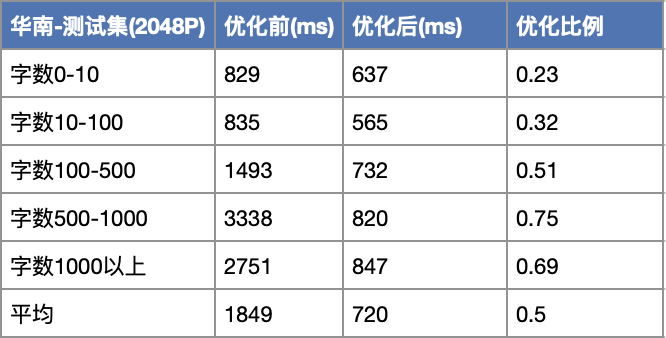
通用OCR三地的平均耗时从优化前1815ms调整到优化后824ms,优化比例54.6%。
随着图片中的字数的增多,耗时优化效果更明显。其耗时优化比例从23%到69%。在耗时优化之前,服务耗时和图片文字正相关,相关性强;优化后,相关性降低。
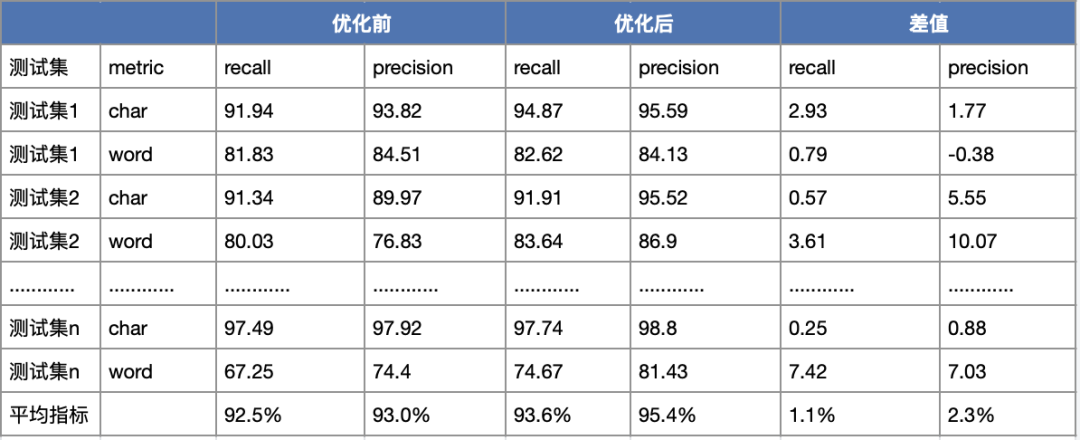
效果:优化后的版本精度有所提升。召回率提升1.1%,准确率提升2.3%。

TI-ACC、工程优化等手段,不仅满足了客户的耗时要求,还也提升了每个接口的tps——平均tps提升51.4%。由于tps的提升,每月可以节省等比例的机器成本。


通用全链路优化,整体耗时降低54.6%,GPU利用率也从平均35%优化到85%。

本次优化取得了阶段性的成果,但值得注意的是,耗时优化是一个持续不断的过程。我们的项目会持续跟踪通用OCR pipleline等环节进行持续优化。期望这篇经验分享文章能给遭遇类似问题的你带来灵感!
注:本文所述数据均为实验测试数据。
腾讯工程师技术干货直达:
1、算法工程师深度解构ChatGPT技术
2、10分钟!从架构视角读懂K8s
3、探秘微信业务优化:DDD从入门到实践
4、祖传代码重构:从25万行到5万行的血泪史

