

作为一位从事嵌入式底层开发的软件攻城狮,少不了要经常要跟汇编代码打交道:比如你要移植一款操作系统到某颗芯片上,比如你想直接操作底层寄存器来实现某个外设功能,比如你想使用汇编代码编程实现一段高效的算法逻辑,等等。
在某种程度上说,熟练掌握汇编语言编程既是一种必备工作技能的硬件要求,同时也可能是你解决某些工作难题的能力延伸。
笔者在过往的工作经历中,有遇到这么一个场景,我相信不少的底层开发攻城狮也可能会遇到类似的困惑。事情是这样的:
我们的项目开展是基于一个开源项目在做的,这个开源项目的绝大部分代码都是开源的,但是唯独某些“核心”的数据加解密流程控制算法是闭源的,这部分功能是通过静态库(.a)的形式开发出来,这样我们作为开发者,在不需要了解其内容实现的情况下,仅需要调用其提供的API就可以跑通整个流程。
我相信大部分的厂商,凡是认为自己的代码稍微有些价值但又不愿意开放源代码的都可能会采用这种方式来操作。
这样做的好处是,厂商无需开放其苦心专研的源代码,外部调用者也无需关注具体的实现,只管接口调用即可。
但是,坏处就是,如果你发现它的实现是有问题的,或者你想从中添加一些功能的时候,就不得不经过厂商来完成,谁让你没有源码呢?
这不,我们就遇到这样一个很棘手的问题,可能单靠文字描述起来比较费劲,我索性画了一个图来表达我们的问题,如下图所示:
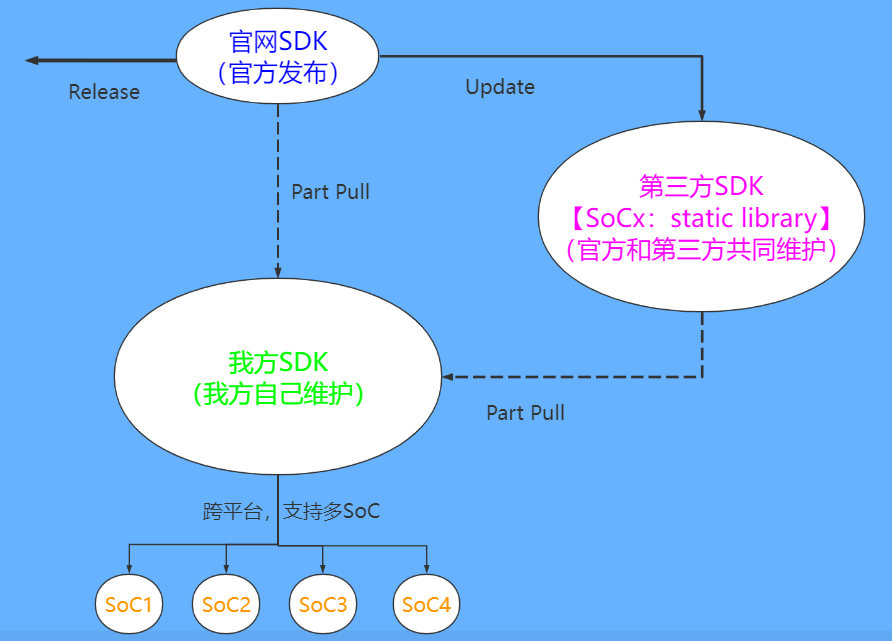
我们的 问题具体是这样的:
从上面的问题描述,我们已经知道了目前遇到的问题瓶颈,它就是:某个核心的数据解密函数,我们只有静态库及其调用方法,但没有其源码实现,无法进行跨平台的移植。
要想优雅地解决此问题,必须绕不开反汇编技术,也就是说,我们能不能通过静态库完成固件的编译,然后再对固件程序进行反编译,得到这段数据解密函数的汇编实现,再结合对汇编代码的逻辑分析,尽可能地还原其C语言版本的源代码?
大致的流程如下图所示:
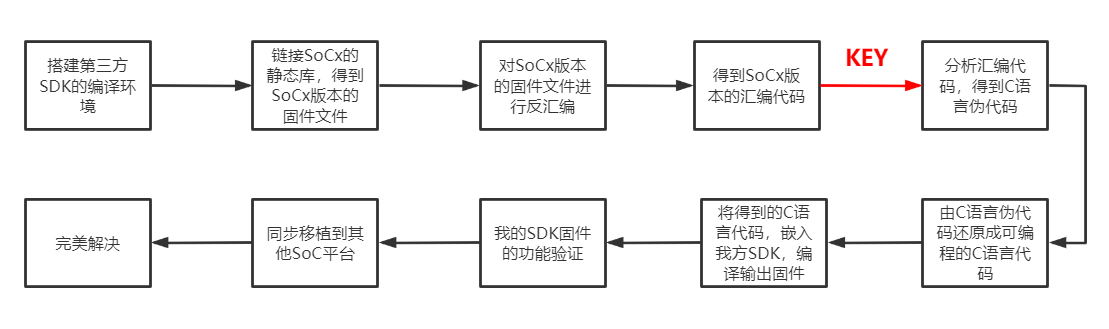
对流程图的各个节点进行困难度分析,我们可以知道最核心要解决的就是从汇编代码如何得到C代码。
从上面的各个分析,我们可以知道关键得从第三方的SDK中寻找突破口,我们得知第三方SDK中使用的SoCx是ARMv5架构的,所以我们得提前预热学习下ARM架构下的汇编基础知识。
在我看来,对汇编基础有个大致的掌握,主要先从三个方面入口:寻址方式、寄存器用途、以及汇编指令的基本用法。
基本上,有了这三大块的知识,看懂基础的汇编代码,甚至说写一写基础的汇编程序,也应该问题不大。
关于ARM的这三大块知识,可以参考下我的另一篇博文:【汇编实战开发笔记】ARM汇编基础的三大块知识。
如果没有ARM汇编的相关基础知识,强烈建议提前了解下,否则可能对下面的实战会有所疑问。
首先得大家第三方SDK的编译环境,索性的是,并不是很负责,整一个构建是使用bash shell + Makefile来完成的,需要安装的交叉编译工具链是arm-none-eabi-xxx;这个工具链之前在别的项目中有用过,所以在环境搭建方面,很顺利就完成了,参考第三方SDK的构建指南,很顺利就编译取得了其输出的固件。
输出的固件中,包含有:xxx.elf、xxx.map、xxx.bin等核心文件。
我们需要使用的正是这个xxx.elf文件,关于ELF文件的内容,感兴趣的可以参考下这篇文章的第五章节。
我们知道,ELF文件包含了丰富的控制信息,我们的bin文件正是输入这个ELF文件,使用objcopy命令得到的。
那么我们要想从ELF文件中得到汇编代码,我们需要使用的命令是objdump,对应交叉编译工具链就是arm-none-eabi-objdump。
它的具体使用方法如下:
arm-none-eabi-objdump -l -d -x -s -S xxx.elf > xxx.dmp
具体的参数含义,可参考 objdump --help.其中xxx.elf即为SoCx编译出来的ELF文件,而xxx.dmp就是反编译得到的汇编代码文件。
注意:执行这行指令,可能会耗时有些久,取决于你的编译环境,处理能力如何。
没有提示失败就代表成功,我们可以使用vi/vim打开这个xxx.dmp文件,简单浏览下。
如果使用windows的文本编辑器可能会加载非常慢,因为这个汇编文件,可能会多达几十MB。
从汇编文件中,搜索我们要找的那个decrypt函数,大致它的内容如下所示:
428632 10051ecc <decrypt_passwd>:
428633 decrypt_passwd():
428634 10051ecc: b570 push {r4, r5, r6, lr}
428635 10051ece: b092 sub sp, #72 ; 0x48
428636 10051ed0: 4605 mov r5, r0
428637 10051ed2: 460c mov r4, r1
428638 10051ed4: 4616 mov r6, r2
428639 10051ed6: 2100 movs r1, #0
428640 10051ed8: 2210 movs r2, #16
428641 10051eda: a801 add r0, sp, #4
428642 10051edc: f02d fda0 bl 1007fa20 <memset>
428643 10051ee0: 2221 movs r2, #33 ; 0x21
428644 10051ee2: 2100 movs r1, #0
428645 10051ee4: a809 add r0, sp, #36 ; 0x24
428646 10051ee6: f02d fd9b bl 1007fa20 <memset>
428647 10051eea: 2210 movs r2, #16
428648 10051eec: 2100 movs r1, #0
428649 10051eee: a805 add r0, sp, #20
428650 10051ef0: f02d fd96 bl 1007fa20 <memset>
428651 10051ef4: 782b ldrb r3, [r5, #0]
428652 10051ef6: b1f3 cbz r3, 10051f36 <decrypt_passwd+0x6a>
428653 10051ef8: 2310 movs r3, #16
428654 10051efa: aa01 add r2, sp, #4
428655 10051efc: 2120 movs r1, #32
428656 10051efe: 4628 mov r0, r5
428657 10051f00: f7c2 fa8a bl 10014418 <hexstr_convert>
428658 10051f04: 2310 movs r3, #16
428659 10051f06: 4620 mov r0, r4
428660 10051f08: aa05 add r2, sp, #20
428661 10051f0a: 2120 movs r1, #32
428662 10051f0c: f7c2 fa84 bl 10014418 <hexstr_convert>
428663 10051f10: 4620 mov r0, r4
428664 10051f12: aa09 add r2, sp, #36 ; 0x24
428665 10051f14: 2120 movs r1, #32
428666 10051f16: f7c4 ff96 bl 10016e46 <utils_sha256>
428667 10051f1a: 2201 movs r2, #1
428668 10051f1c: a905 add r1, sp, #20
428669 10051f1e: a809 add r0, sp, #36 ; 0x24
428670 10051f20: f7dd fb62 bl 1002f5e8 <aes128_init>
428671 10051f24: 4633 mov r3, r6
428672 10051f26: 4604 mov r4, r0
428673 10051f28: 2201 movs r2, #1
428674 10051f2a: a901 add r1, sp, #4
428675 10051f2c: f7dd fbb3 bl 1002f696 <aes128_cbc_decrypt>
428676 10051f30: 4620 mov r0, r4
428677 10051f32: f7dd fba3 bl 1002f67c <aes128_destroy>
428678 10051f36: 2000 movs r0, #0
428679 10051f38: b012 add sp, #72 ; 0x48
428680 10051f3a: bd70 pop {r4, r5, r6, pc}下面我们分两步走:先翻译汇编成C伪代码,再把伪代码还原成C代码。
到了这一步,就必须要用ARM汇编的基础知识了,其中最关键的就是:函数的参数传递,以及函数调用。
在ARM汇编中,一般使用R0-R3传递参数,分别对应第1-4个形参。
在ARM汇编中,带返回的函数调用使用的bl指令,这个指令后面接的是调用的地址,也就是需要调用的函数。
为了好对比,我采取的做法是直接在关键的汇编代码后面,转换成伪代码,得到的内容如下所示:
428632 10051ecc <decrypt_passwd>: //int decrypt_password(const char *cipher, const uint8_t *random, char *passwd)
428633 decrypt_passwd():
428634 10051ecc: b570 push {r4, r5, r6, lr}
428635 10051ece: b092 sub sp, #72 ; 0x48
428636 10051ed0: 4605 mov r5, r0 #r5=r0 //encoded
428637 10051ed2: 460c mov r4, r1 #r4=r1 //p_ranodm_str
428638 10051ed4: 4616 mov r6, r2 #r6=r2 //passwd
428639 10051ed6: 2100 movs r1, #0
428640 10051ed8: 2210 movs r2, #16
428641 10051eda: a801 add r0, sp, #4
428642 10051edc: f02d fda0 bl 1007fa20 <memset> //memset(sp0, 0, 16)
428643 10051ee0: 2221 movs r2, #33 ; 0x21
428644 10051ee2: 2100 movs r1, #0
428645 10051ee4: a809 add r0, sp, #36 ; 0x24
428646 10051ee6: f02d fd9b bl 1007fa20 <memset> //memset(sp1, 0, 33)
428647 10051eea: 2210 movs r2, #16
428648 10051eec: 2100 movs r1, #0
428649 10051eee: a805 add r0, sp, #20
428650 10051ef0: f02d fd96 bl 1007fa20 <memset> //memset(sp2, 0, 16)
428651 10051ef4: 782b ldrb r3, [r5, #0]
428652 10051ef6: b1f3 cbz r3, 10051f36 <decrypt_passwd+0x6a>
428653 10051ef8: 2310 movs r3, #16
428654 10051efa: aa01 add r2, sp, #4
428655 10051efc: 2120 movs r1, #32
428656 10051efe: 4628 mov r0, r5
428657 10051f00: f7c2 fa8a bl 10014418 <hexstr_convert> //encoded->sp0(hex)
428658 10051f04: 2310 movs r3, #16
428659 10051f06: 4620 mov r0, r4
428660 10051f08: aa05 add r2, sp, #20
428661 10051f0a: 2120 movs r1, #32
void hexstr_convert(char *hexstr, uint8_t *out_buf, int len);
428662 10051f0c: f7c2 fa84 bl 10014418 <hexstr_convert> //p_ranodm_str->sp2(hex)
428663 10051f10: 4620 mov r0, r4
428664 10051f12: aa09 add r2, sp, #36 ; 0x24
428665 10051f14: 2120 movs r1, #32
void utils_sha256(const uint8_t *input, uint32_t ilen, uint8_t output[32])
428666 10051f16: f7c4 ff96 bl 10016e46 <utils_sha256> //sha256(p_ranodm_str,32,sp1)
428667 10051f1a: 2201 movs r2, #1
428668 10051f1c: a905 add r1, sp, #20
428669 10051f1e: a809 add r0, sp, #36 ; 0x24
p_HAL_Aes128_t aes128_init(_IN_ const uint8_t *key, _IN_ const uint8_t *iv,
_IN_ AES_DIR_t dir)
428670 10051f20: f7dd fb62 bl 1002f5e8 <aes128_init> //key=sp1,iv=sp2,dir=1(decrypt)
428671 10051f24: 4633 mov r3, r6
428672 10051f26: 4604 mov r4, r0
428673 10051f28: 2201 movs r2, #1
428674 10051f2a: a901 add r1, sp, #4
int aes128_cbc_decrypt(_IN_ p_HAL_Aes128_t aes, _IN_ const void *src,
_IN_ size_t blockNum, _OU_ void *dst)
428675 10051f2c: f7dd fbb3 bl 1002f696 <aes128_cbc_decrypt> //src=sp0,blockNum=1,dst=passwd
428676 10051f30: 4620 mov r0, r4
428677 10051f32: f7dd fba3 bl 1002f67c <aes128_destroy> // int aes128_destroy(_IN_ p_HAL_Aes128_t aes)
428678 10051f36: 2000 movs r0, #0
428679 10051f38: b012 add sp, #72 ; 0x48
428680 10051f3a: bd70 pop {r4, r5, r6, pc}得到上面的伪代码,其实还有一点也比较重要,我们必须得知道这个decrypt函数的原型以及它调用的几个函数的原型,索性的是,这些个函数原因都可以在第三方的SDK中找到,毕竟头文件是开源的。
int decrypt_passwd(const char *cipher, const uint8_t *random, char *passwd);
void *memset(void *s, int c, size_t n);
void hexstr_convert(char *hexstr, uint8_t *out_buf, int len);
void utils_sha256(const uint8_t *input, uint32_t ilen, uint8_t output[32]);
p_HAL_Aes128_t aes128_init(_IN_ const uint8_t *key, _IN_ const uint8_t *iv,
_IN_ AES_DIR_t dir);
int aes128_cbc_decrypt(_IN_ p_HAL_Aes128_t aes, _IN_ const void *src,
_IN_ size_t blockNum, _OU_ void *dst);
int aes128_destroy(_IN_ p_HAL_Aes128_t aes);只有知道了原型,我们才能更好地分析其入参的顺序,这样才能知道R0-R4寄存器放的是什么值。
不过,我们还有一点可以想想的是,有时候其函数名也是一个重要的信息,比如其中的hexstr_convert是hex2string的转换,比如其中的utils_sha256是SHA256摘要的基础算法。这些在没有更多信息的时候,就只能靠猜和尝试,再验证了。
有了上面的伪代码,基本上捋一捋上下文就可以得到比较像样的C代码了,就像这样的:
/* get this function logic from ARM ASM section. */
int decrypt_passwd(const char *cipher, const uint8_t *_random, char *passwd)
{
uint8_t sp0[16];
uint8_t sp1[33];
uint8_t sp2[16];
char random[33] = {0};
memcpy(random, _random, 32);
int cipher_len = strlen(cipher);
int random_len = strlen(random);
p_HAL_Aes128_t aes_eng;
int ret = -1;
memset(sp0, 0, 16);
memset(sp1, 0, 33);
memset(sp2, 0, 16);
//cipher(32 bytes) -> sp0(16 bytes)
utils_str_to_hex(cipher, cipher_len, sp0, sizeof(sp0));
//random(32 bytes) -> sp2(33 bytes)
utils_str_to_hex(random, random_len, sp2, sizeof(sp2));
//random(32 bytes) -> sp1(16 bytes)
utils_sha256(random, random_len, sp1);
//init AES
const uint8_t *key = sp1;
const uint8_t *iv = sp2;
AES_DIR_t dir = AES_DECRYPTION;
aes_eng = aes128_init(key, iv, dir);
if (!hal_aes_eng) {
return ret;
}
//AES128-CBC decrypt
const void *src = sp0;
size_t blockNum = 1;
void *dst = passwd;
ret = aes128_cbc_decrypt(aes_eng, src, blockNum, dst);
//de-init AES
aes128_destroy(aes_eng);
return ret;
}基本上,得到的C代码,可读性还是比较强的,前后的逻辑关联性也保留地比较完整,具备移植使用的条件。
这一步就比较简单了,仅仅是将上面得到的C代码,填入一个新建的C文件,把代码中依赖的相关函数的头文件找出来,使用include包含,重新编译新的工程即可。
确保工程能够编译通过,正确输出固件包,即可进行下面的功能验证了。
所谓的正向验证,就是按照上面给出的操作流程,一步步将停留在静态库里面的汇编逻辑,转换成C代码,再把C代码编译得到新的固件包,烧录验证,从而确保之前那个未跑通的功能能够顺利跑通。
既然,我能把这篇总结发出来,自然这个功能层面的验证肯定是通过了的。
所谓的反向验证,就是在上面的步骤基础之上,我们再讲得到的C代码源码编译成汇编代码,再对比下我们编译出来的汇编代码,与最初从SoCx中取得的汇编代码,差异究竟大不大,有没有与之想冲突的地方存在。
如果使用gcc编译器的话,添加 -save-temps=obj 编译选项,即可得到C代码对应的汇编代码。
下面我罗列下,两者的汇编的代码:
/* SoCx取得的汇编代码:如4.2章节所示 *//* 得到的C代码经新的编译所得的汇编代码 */
.section .text.decrypt_passwd,"ax",%progbits
.align 1
.global decrypt_passwd
.code 16
.thumb_func
.type decrypt_passwd, %function
decrypt_passwd:
.LFB1:
.file 1
.loc 1 84 0
.cfi_startproc
@ args = 0, pretend = 0, frame = 104
@ frame_needed = 0, uses_anonymous_args = 0
.LVL0:
push {r4, r5, r6, r7, lr}
.cfi_def_cfa_offset 20
.cfi_offset 4, -20
.cfi_offset 5, -16
.cfi_offset 6, -12
.cfi_offset 7, -8
.cfi_offset 14, -4
movs r4, r1
movs r5, r0
sub sp, sp, #108
.cfi_def_cfa_offset 128
.loc 1 88 0
movs r1, #0
.LVL1:
.loc 1 84 0
movs r6, r2
.loc 1 88 0
add r0, sp, #68
.LVL2:
movs r2, #33
.LVL3:
bl memset
.LVL4:
.loc 1 89 0
movs r1, r4
movs r2, #32
add r0, sp, #68
bl memcpy
.LVL5:
.loc 1 90 0
movs r0, r5
bl strlen
.LVL6:
movs r7, r0
.LVL7:
.loc 1 91 0
add r0, sp, #68
.LVL8:
bl strlen
.LVL9:
movs r4, r0
.LVL10:
.loc 1 95 0
movs r2, #16
movs r1, #0
mov r0, sp
.LVL11:
bl memset
.LVL12:
.loc 1 96 0
movs r2, #33
movs r1, #0
add r0, sp, #32
bl memset
.LVL13:
.loc 1 97 0
movs r2, #16
movs r1, #0
add r0, sp, #16
bl memset
.LVL14:
.loc 1 100 0
movs r0, r5
movs r3, #16
mov r2, sp
movs r1, r7
bl hexstr_convert
.LVL15:
.loc 1 103 0
movs r3, #16
add r2, sp, #16
movs r1, r4
add r0, sp, #68
bl hexstr_convert
.LVL16:
.loc 1 106 0
add r2, sp, #32
movs r1, r4
add r0, sp, #68
bl utils_sha256
.LVL17:
.loc 1 112 0
movs r2, #1
add r1, sp, #16
.LVL18:
add r0, sp, #32
.LVL19:
bl aes128_init
.LVL20:
subs r5, r0, #0
.LVL21:
.loc 1 113 0
beq .L3
.LVL22:
.loc 1 121 0
movs r3, r6
movs r2, #1
mov r1, sp
bl aes128_cbc_decrypt
.LVL23:
movs r4, r0
.LVL24:
.loc 1 124 0
movs r0, r5
.LVL25:
bl aes128_destroy
.LVL26:
.loc 1 126 0
movs r0, r4
b .L2
.LVL27:
.L3:
.loc 1 114 0
movs r0, #1
.LVL28:
rsbs r0, r0, #0
.LVL29:
.L2:
.loc 1 127 0
add sp, sp, #108
@ sp needed
.LVL30:
.LVL31:
.LVL32:
pop {r4, r5, r6, r7, pc}通过对比以上汇编代码,我们可以知道大体上两者是相同的,这也就证明了我们反编译的操作是成功的。
前文,我也提到了我们的SDK是支持跨平台的,目前支持的SoC的CPU架构有ARMv5、ARMv7、RISC-V、X86等等。
由于这次遇到的第三方的SoCx恰好是ARMv5架构的,所以我们很熟练地使用ARM汇编的基础知识,就基本把汇编代码还原成C语言的伪代码了。
那么,如果SoCx是RISC-V架构的呢?如果SoCx是X86架构的呢?
万变不离其中,我们关键还是需要掌握SoC对应的汇编基础三大块内容:寻址方式、寄存器的用途、以及汇编指令的说明。
这里将RISC-V架构和X86架构,对应的这三大块知识放在这里,感兴趣的可以一看。
RISC-V架构的汇编基础三大块:详情请戳我。
X86架构的汇编基础三大块:详情请戳我。
经过这次项目问题的历练,我得出了几个比较重要的经验,对我今后研发工作的开展也带来了一些新的思路,也希望对大家有所帮助。
几点总结如下:
欢迎关注我的github仓库01workstation,日常分享一些开发笔记和项目实战,欢迎指正问题。
同时也非常欢迎关注我的CSDN主页和专栏:
【CSDN主页:架构师李肯】
【RT-Thread主页:架构师李肯】
【C/C++语言编程专栏】
【GCC专栏】
【信息安全专栏】
【RT-Thread开发笔记】
【freeRTOS开发笔记】
【BLE蓝牙开发笔记】
【ARM开发笔记】
【RISC-V开发笔记】
有问题的话,可以跟我讨论,知无不答,谢谢大家。
