Elasticsearch 的开源分析可视化工具,与存储在 Elasticsearch 中的数据进行交互。
Kibana 是一款免费且开放的前端应用程序,其基础是 Elastic Stack,可以为 Elasticsearch 中索引的数据提供搜索和数据可视化功能。尽管人们通常将 Kibana 视作 Elastic Stack(之前称作 ELK Stack,分别表示 Elasticsearch、Logstash 和 Kibana)的制图工具,但也可将 Kibana 作为用户界面来监测和管理 Elastic Stack 集群并确保集群安全性,还可将其作为基于 Elastic Stack 所开发内置解决方案的汇集中心。Elasticsearch 社区于 2013 年开发出了 Kibana,现在 Kibana 已发展成为 Elastic Stack 的窗口,是用户和公司的一个门户。
Kibana 与 Elasticsearch 和更广意义上的 Elastic Stack 紧密集成,这一点使其成为支持下列场景的理想之选:
Elasticsearch 下载的版本是 7.6.1,这里我们选择同样的 7.6.1版本
注意:Kibana 的版本和 Elasticsearch 的版本必须一致。
下载地址:https://www.elastic.co/cn/downloads/past-releases#kibana
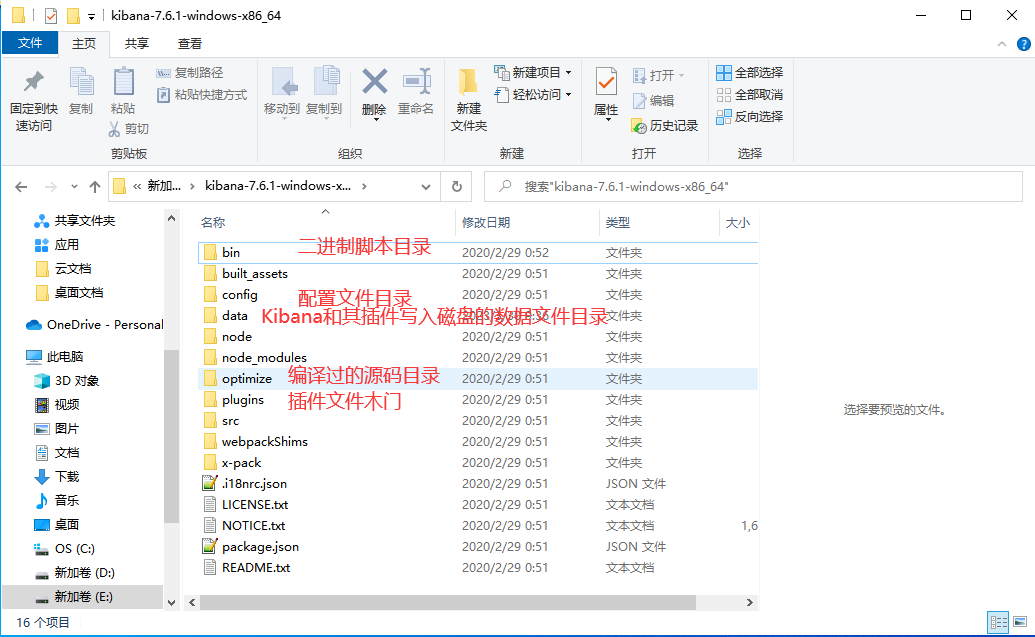
类似与tomcat,直接解压即可。其目录结构如下:
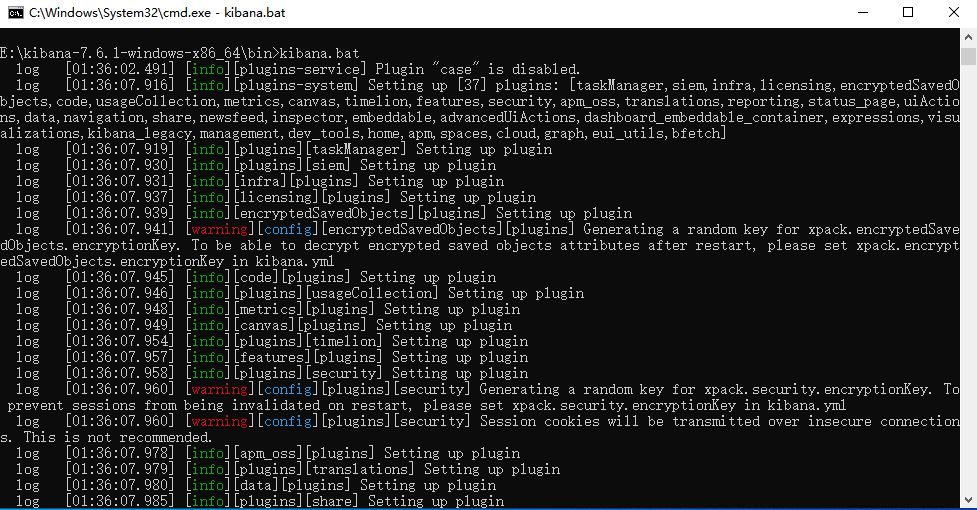
1.直接cmd打开bin目录,并启动kibana:kibana.bat 或者双击 kibana.bat ,如下图所示:
访问网址:127.0.0.1:5601或者localhost:5601 ,如下图所示:
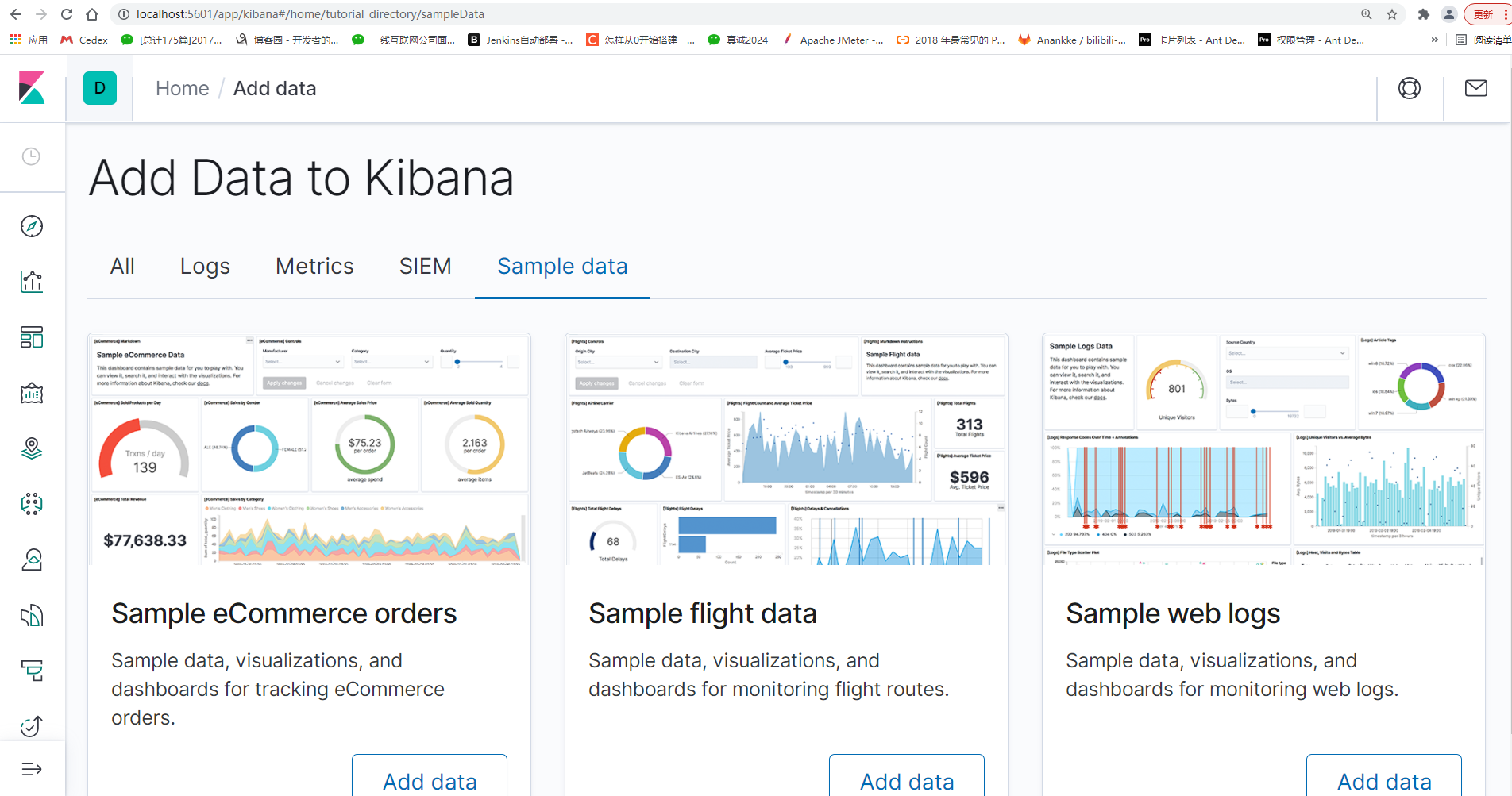
1.进入Kibana的配置文件夹config/kibana.yml 打开修改为:
i18n.locale: "zh-CN"2.保存重启Kibana,再次访问Kibana,界面都变成中文了,如下图所示:
1.进入Kibana的配置文件夹config/kibana.yml 打开修改为:
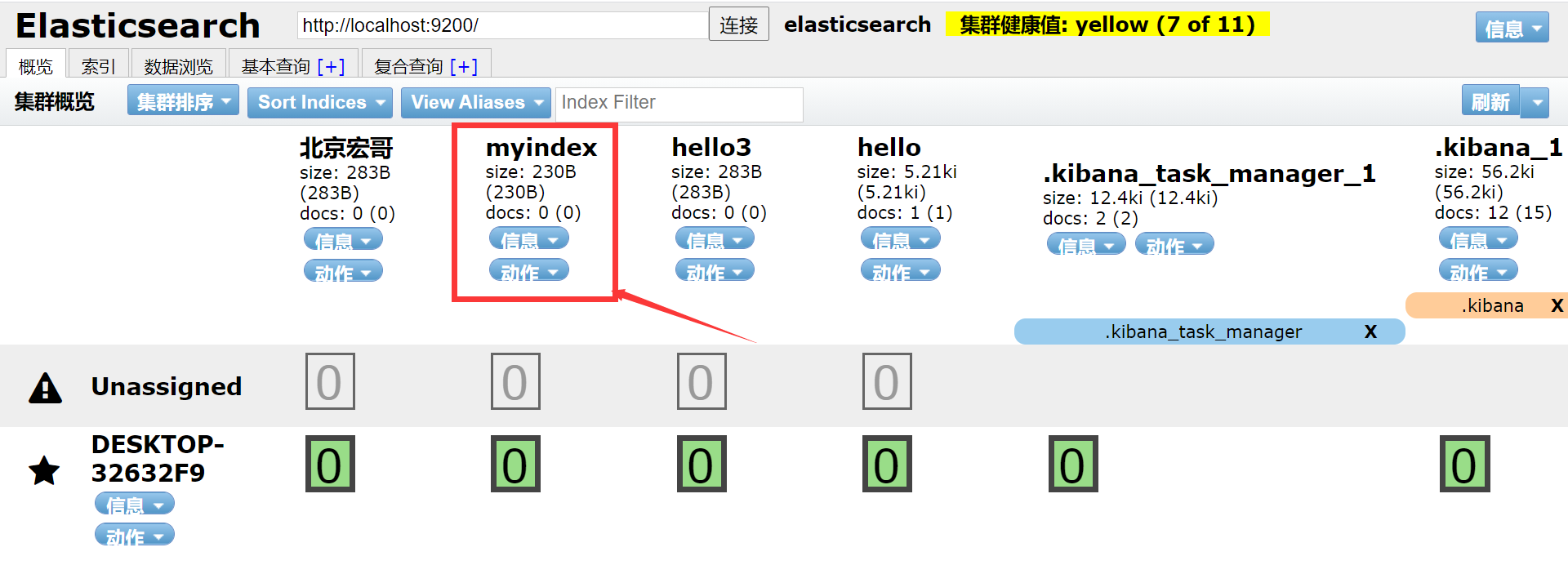
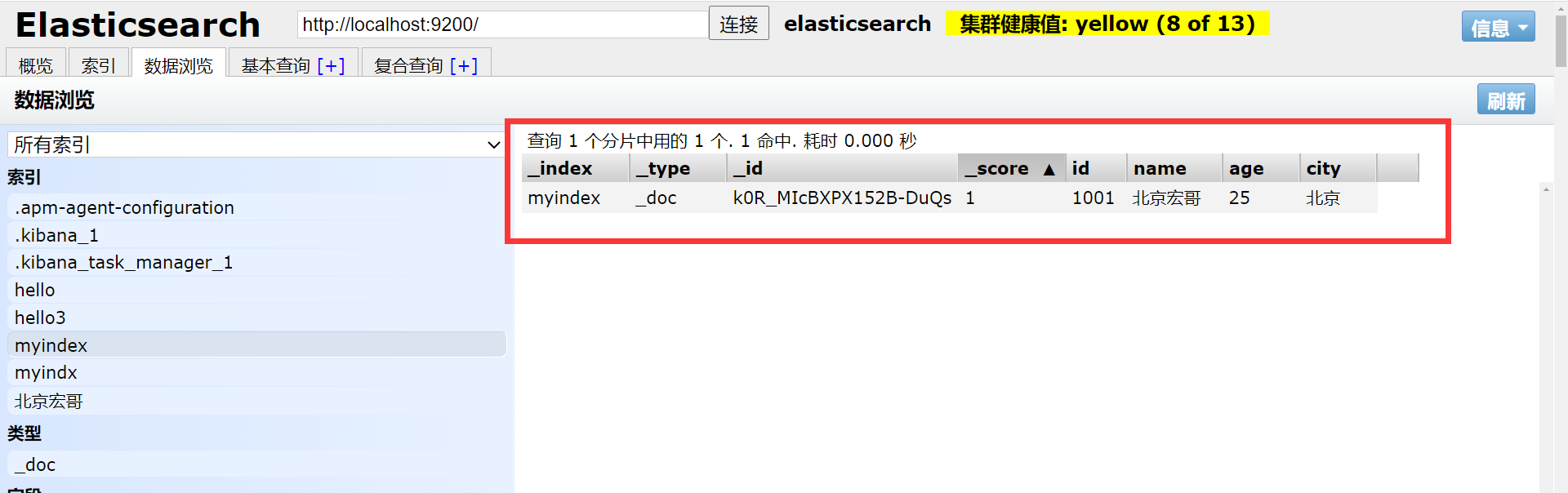
elasticsearch.hosts: ["http://localhost:9200"]2.保存,重启es和Kibana,测试连接状态,在Kibana创建索引:北京宏哥,如下图所示:
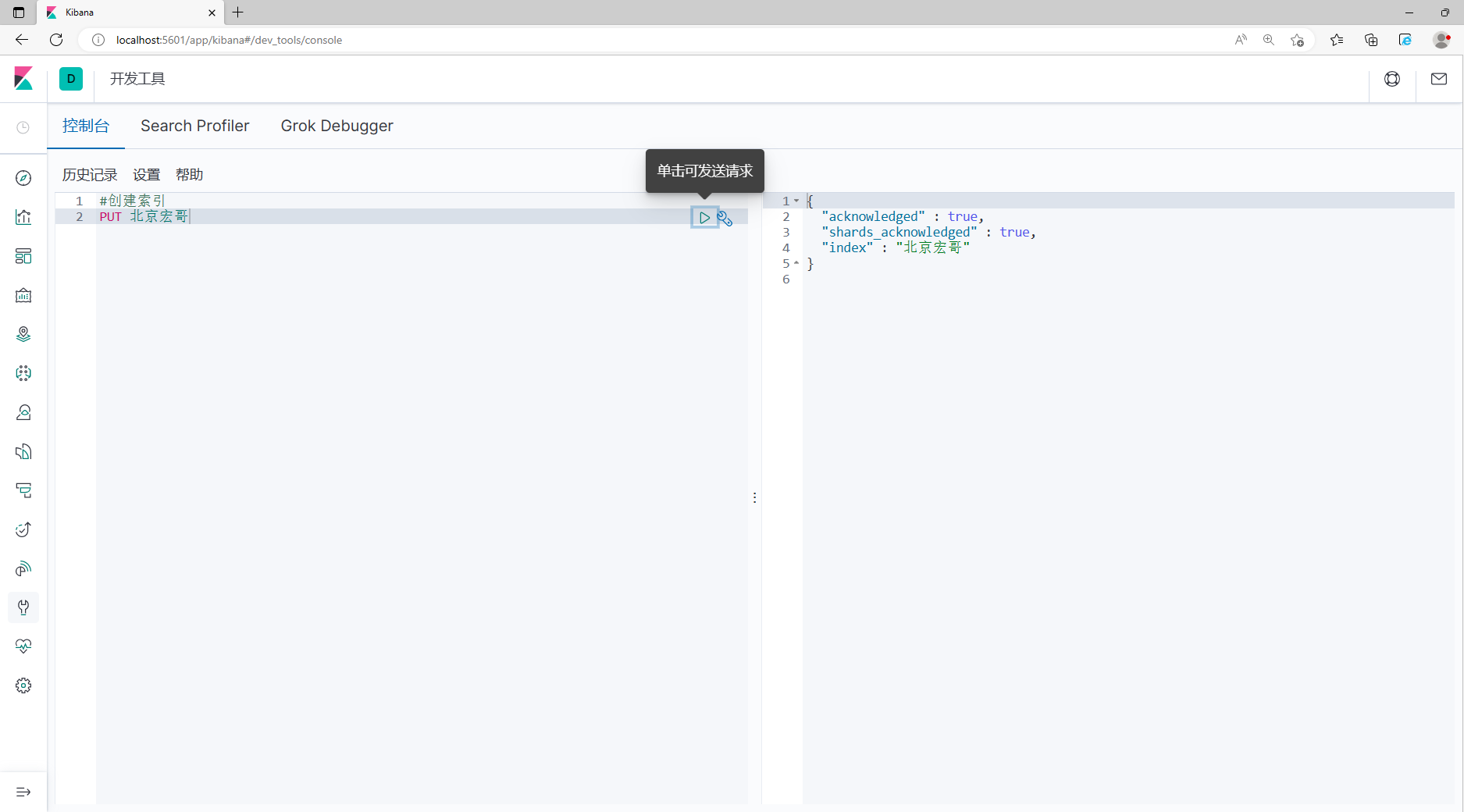
3.在ES中查看是否成功,如下图所示:

1.在主页找到控制台,如下图所示:
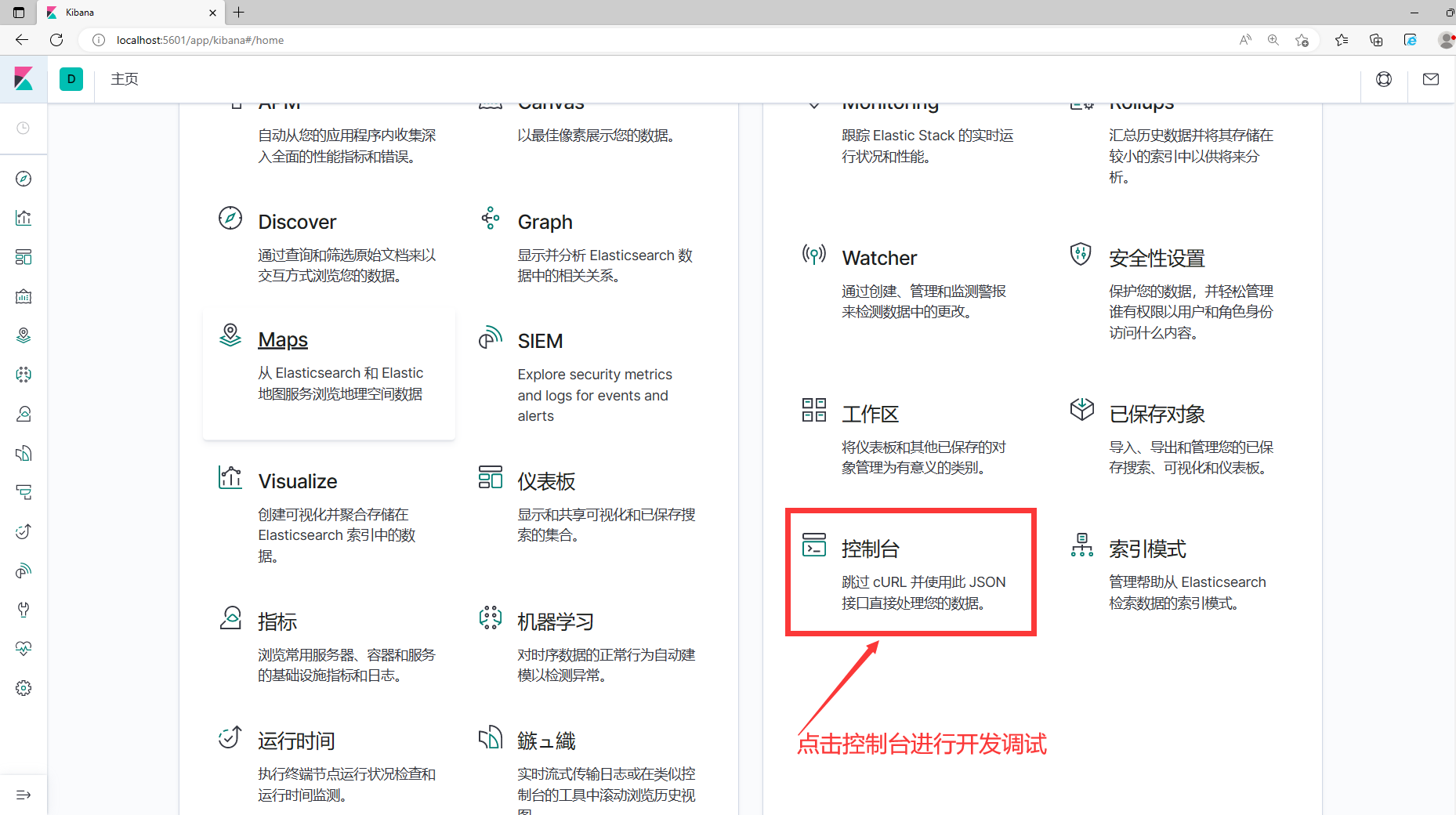
2.进入控制台就可以调试使用了,如下图所示:
1.ES 软件的索引可以类比为 MySQL 中表的概念,创建一个索引,类似于创建一个表。 查询完成后,Kibana 右侧会返回响应结果及请求状态
#创建索引
PUT myindex
2.重复创建索引时,Kibana 右侧会返回响应结果,其中包含错误信息。
#创建重复索引
PUT myindex
1.根据索引名称查询指定索引,如果查询到,会返回索引的详细信息
#查询指定索引
GET myindex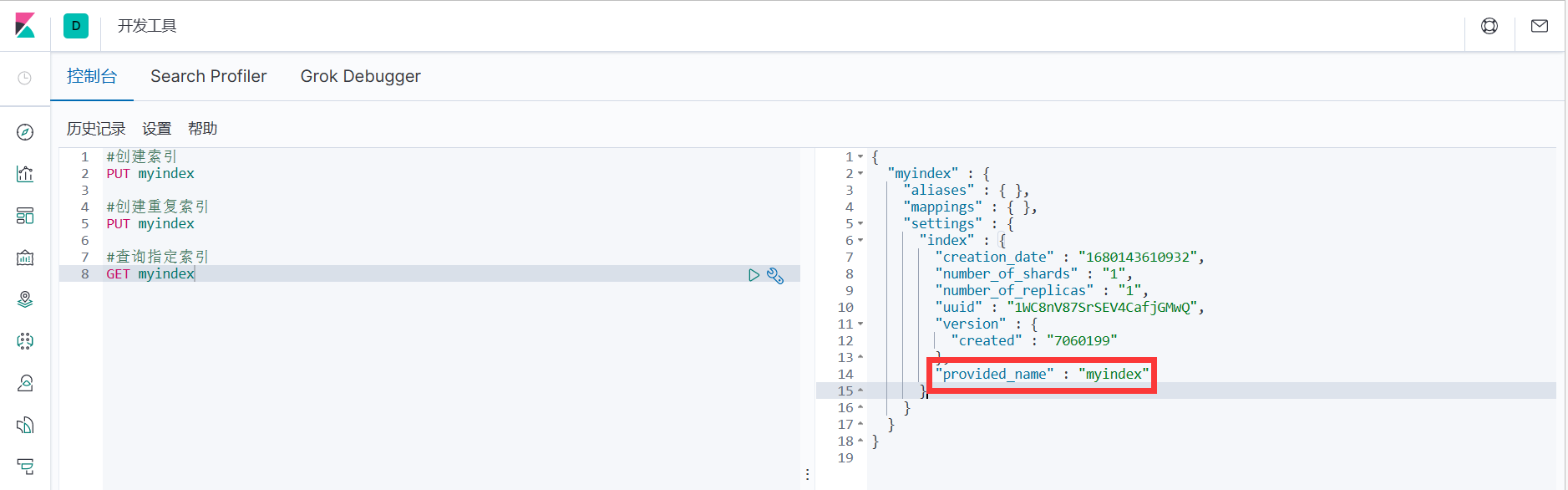
2.如果查询的索引不存在,会返回错误信息
#查询索引不存在
GET myindex
1.为了方便,可以查询当前所有索引数据。这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES 服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉
#查询当前所有索引数据
GET _cat/indices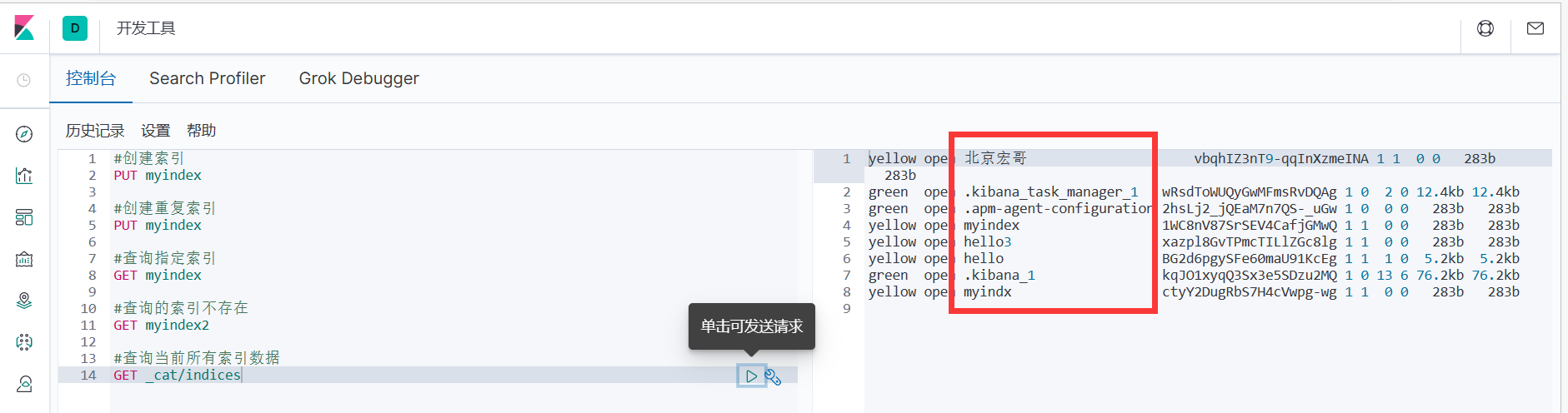
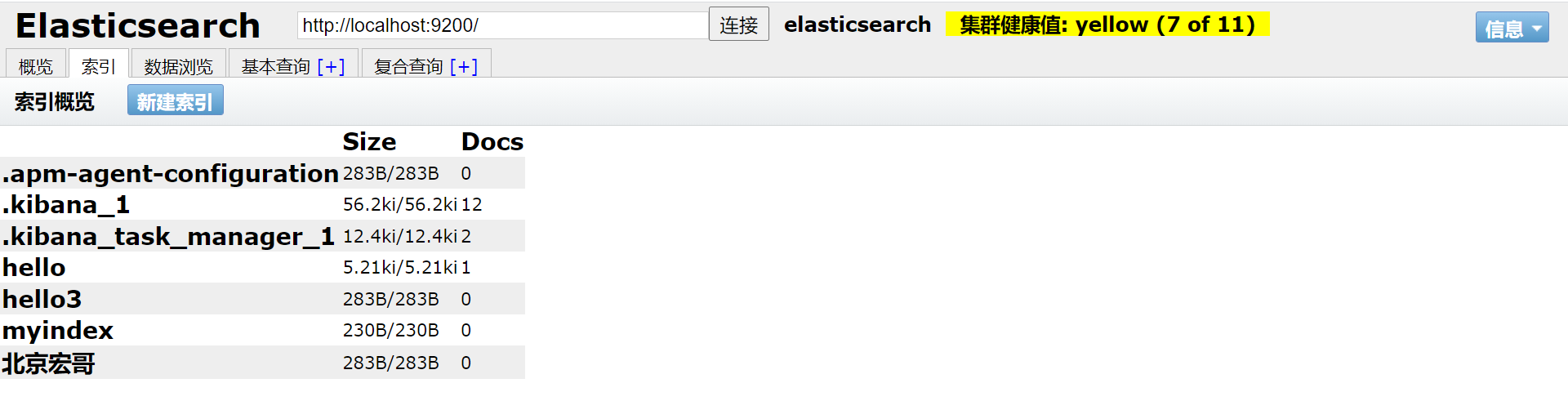
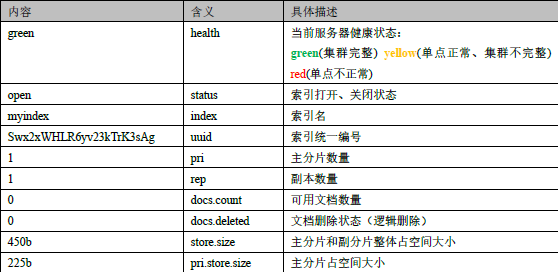
2.这里的查询结果表示索引的状态信息,按顺序数据表示结果如下:
1.删除指定已存在的索引
#删除指定已存在的索引
DELETE myindex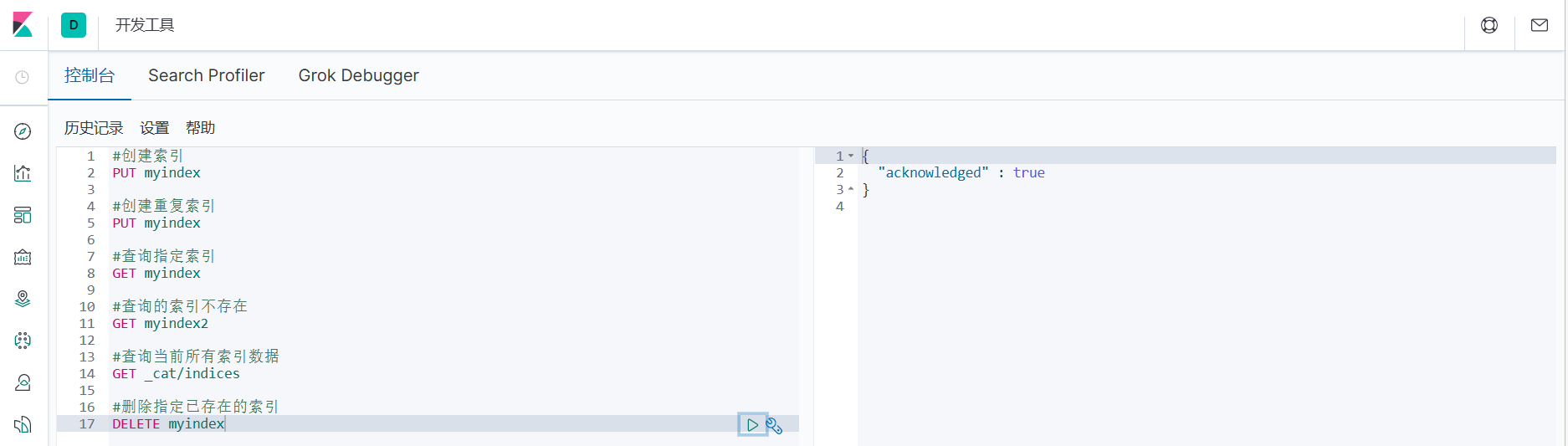
2.如果删除一个不存在的索引,那么会返回错误信息
#删除指定不存在的索引
DELETE myindex3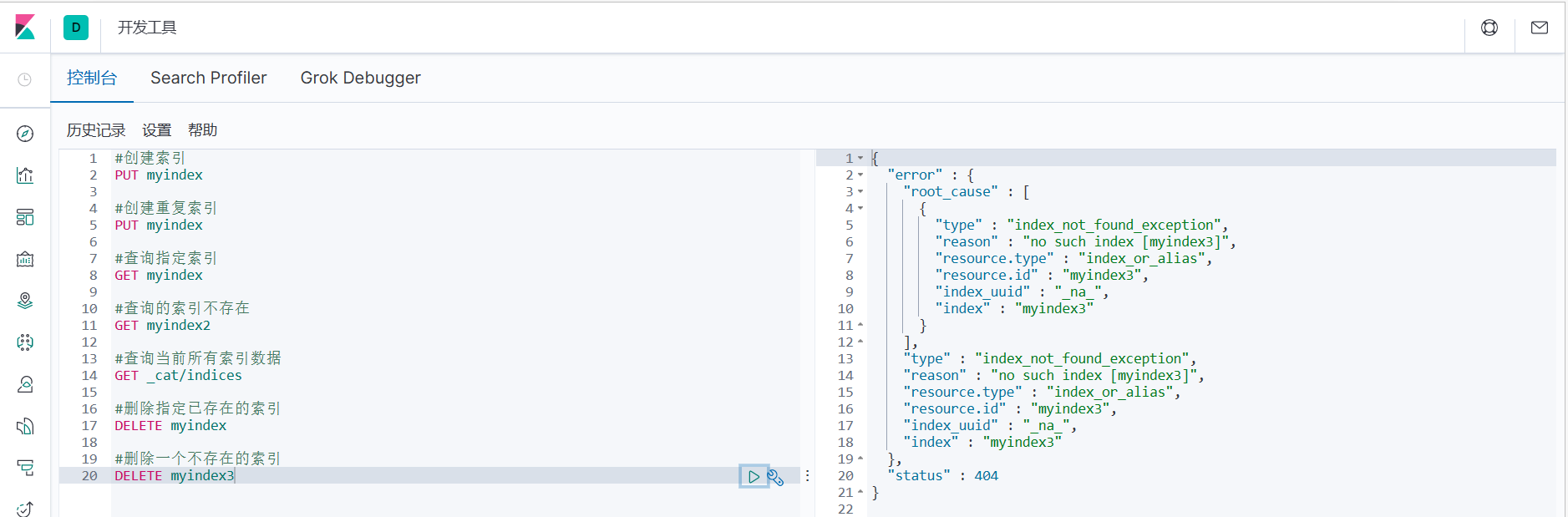
文档是 ES 软件搜索数据的最小单位, 不依赖预先定义的模式,所以可以将文档类比为表的 一行JSON类型的数据。我们知道关系型数据库中,要提前定义字段才能使用,在Elasticsearch 中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
1.索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数 据库中的表数据,添加的数据格式为 JSON 格式
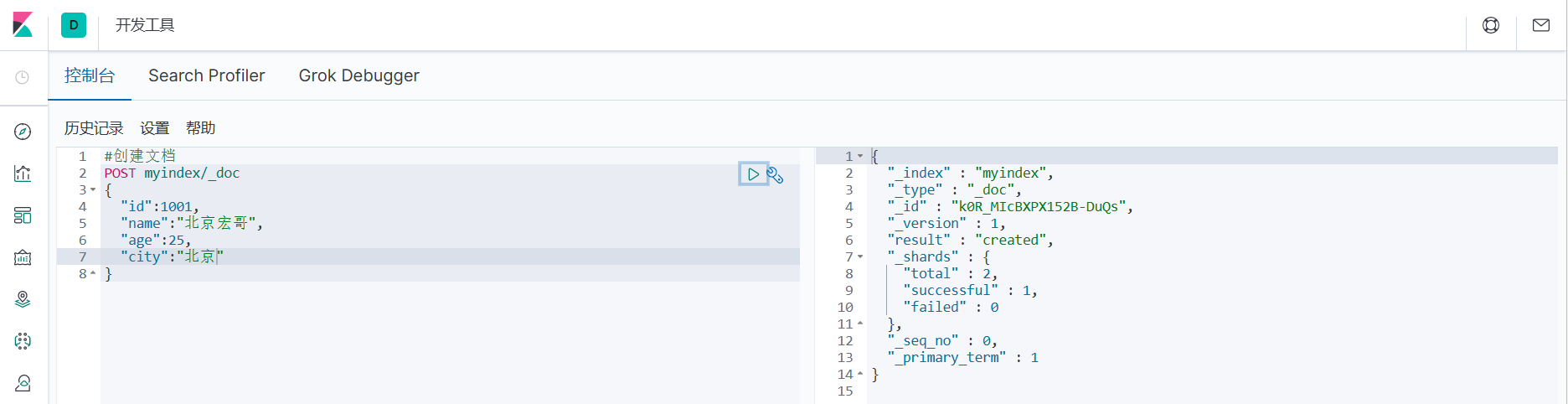
#创建文档
POST myindex/_doc
{
"id":1001,
"name":"北京宏哥",
"age":25,
"city":"北京"
}
2.此处因为没有指定数据唯一性标识,所以无法使用PUT 请求,只能使用 POST 请求,且对数据会生成随机的唯一性标识。否则会返回错误信息
#创建文档
PUT myindex/_doc
{
"id":1001,
"name":"北京宏哥",
"age":25,
"city":"北京"
}
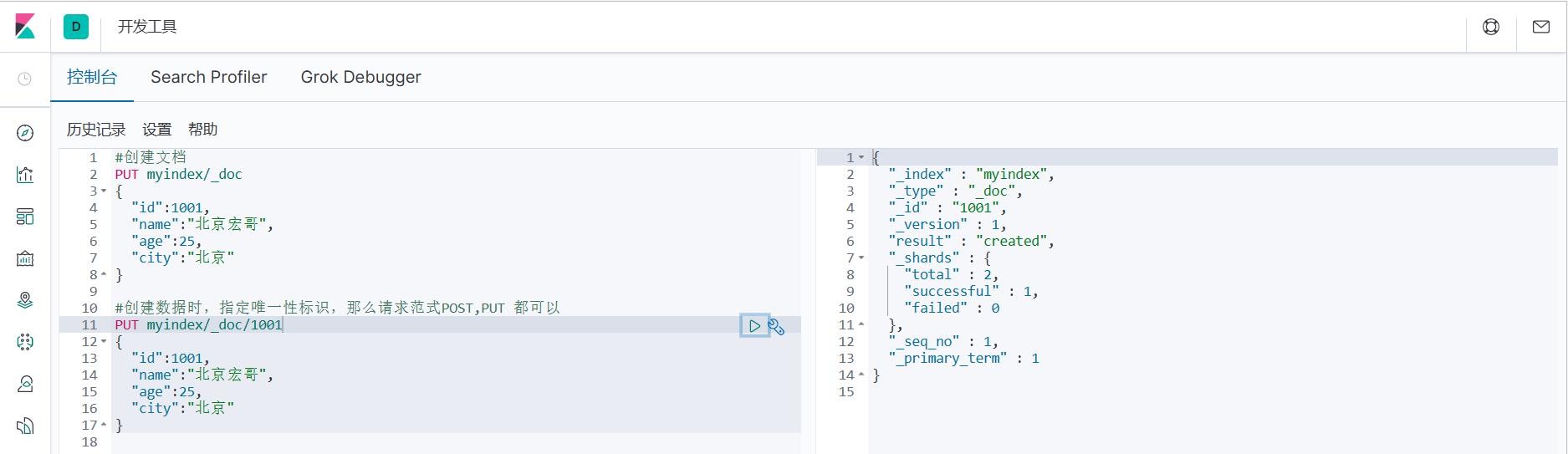
3.如果在创建数据时,指定唯一性标识,那么请求范式POST,PUT 都可以
#创建数据时,指定唯一性标识,那么请求范式POST,PUT 都可以
PUT myindex/_doc/1001
{
"id":1001,
"name":"北京宏哥",
"age":25,
"city":"北京"
}
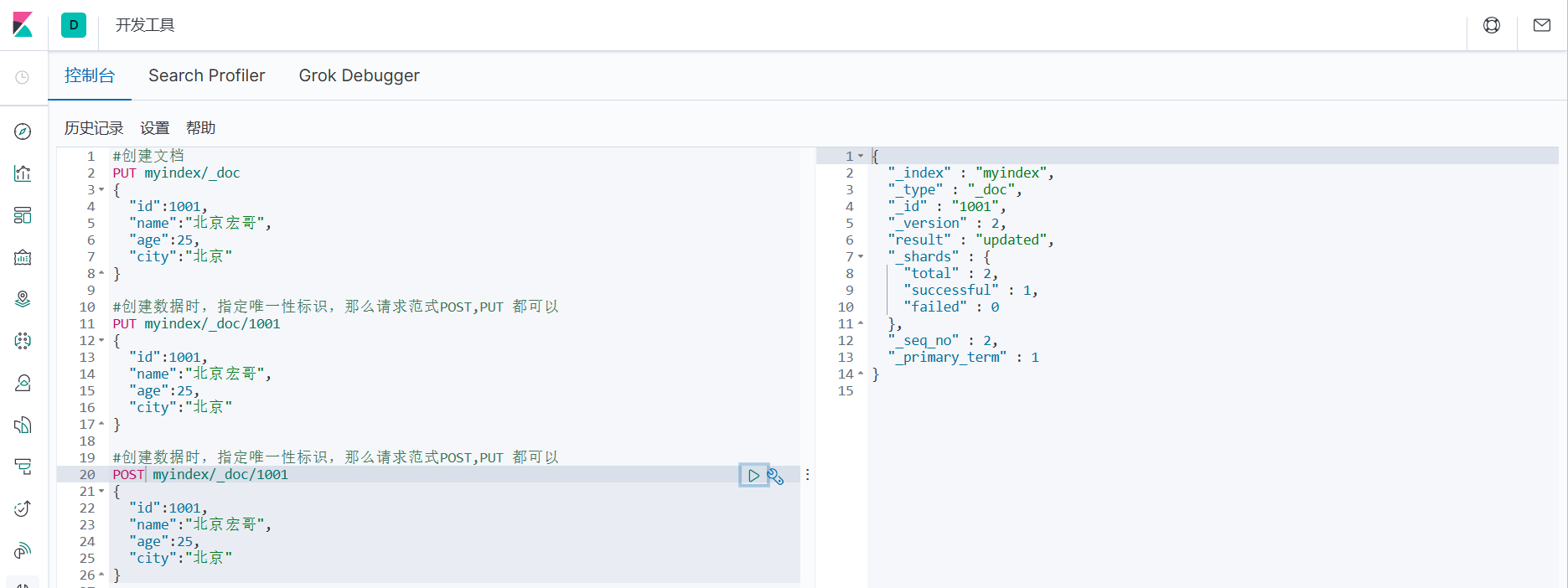
POST myindex/_doc/1001
{
"id":1001,
"name":"北京宏哥",
"age":25,
"city":"北京"
}
1.根据唯一性标识可以查询对应的文档
#查询指定标识的文档
GET myindex/_doc/1001?pretty=true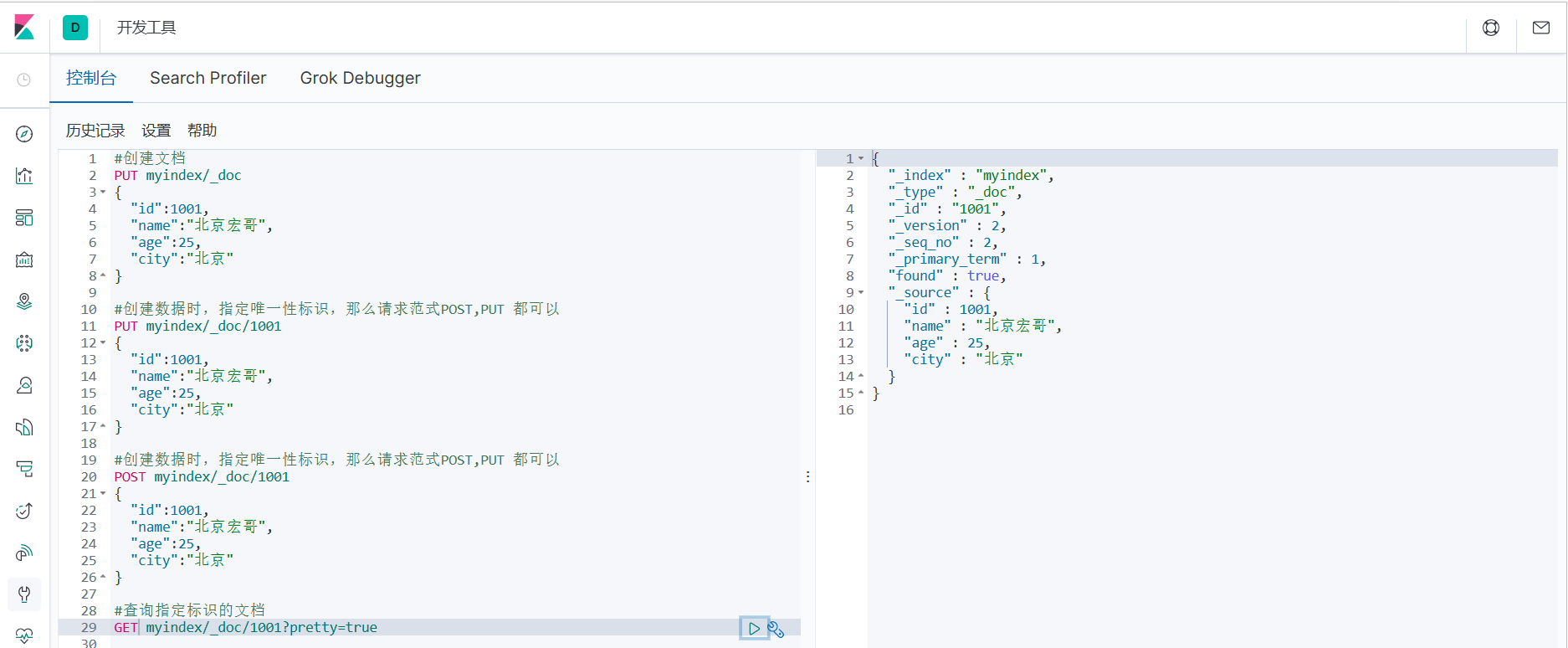
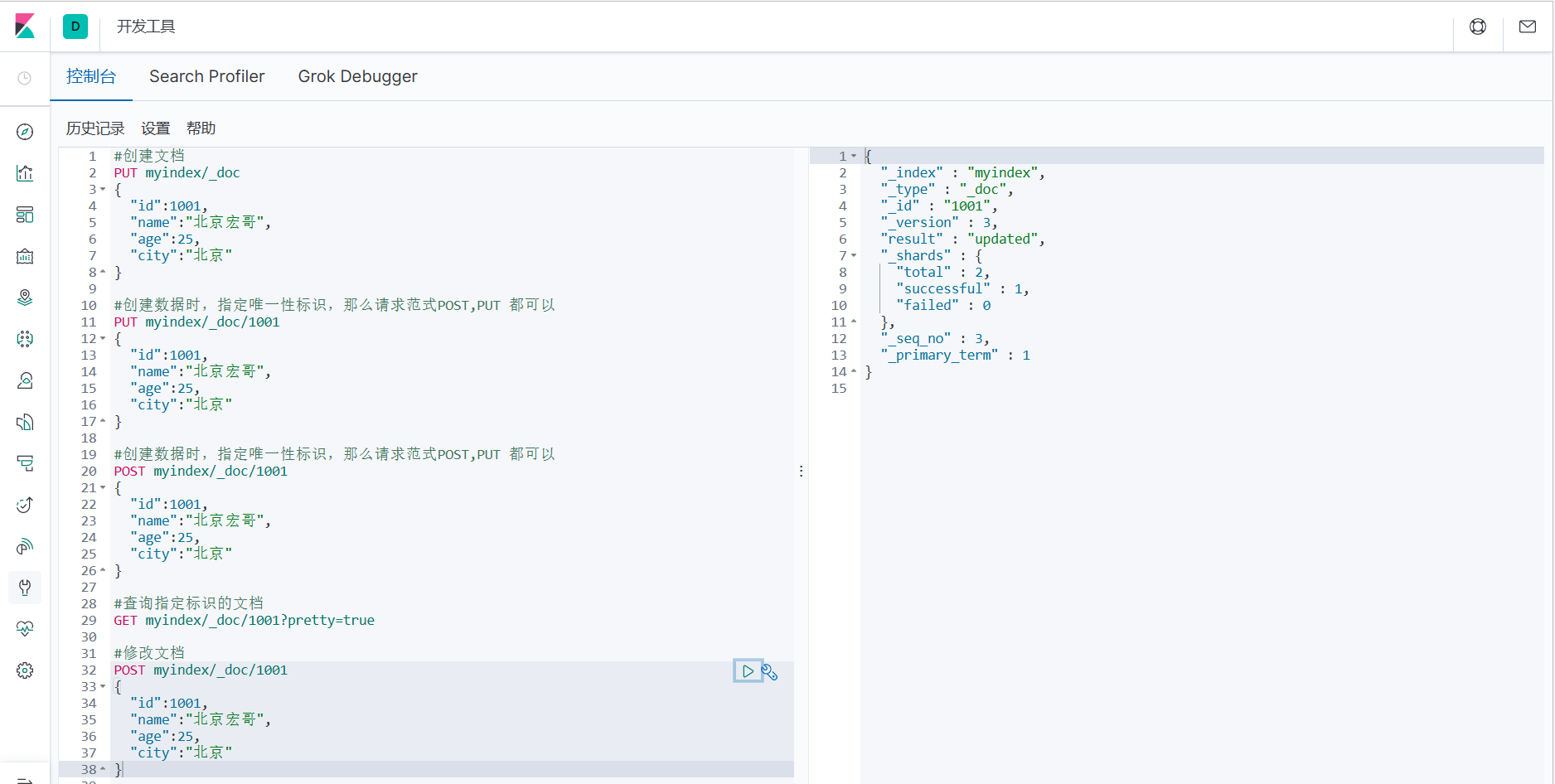
1.修改文档本质上和新增文档是一样的,如果存在就修改,如果不存在就新增
#修改文档
POST myindex/_doc/1001
{
"id":1001,
"name":"北京宏哥",
"age":25,
"city":"北京"
}
1.删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
#删除文档
DELETE myindex/_doc/1001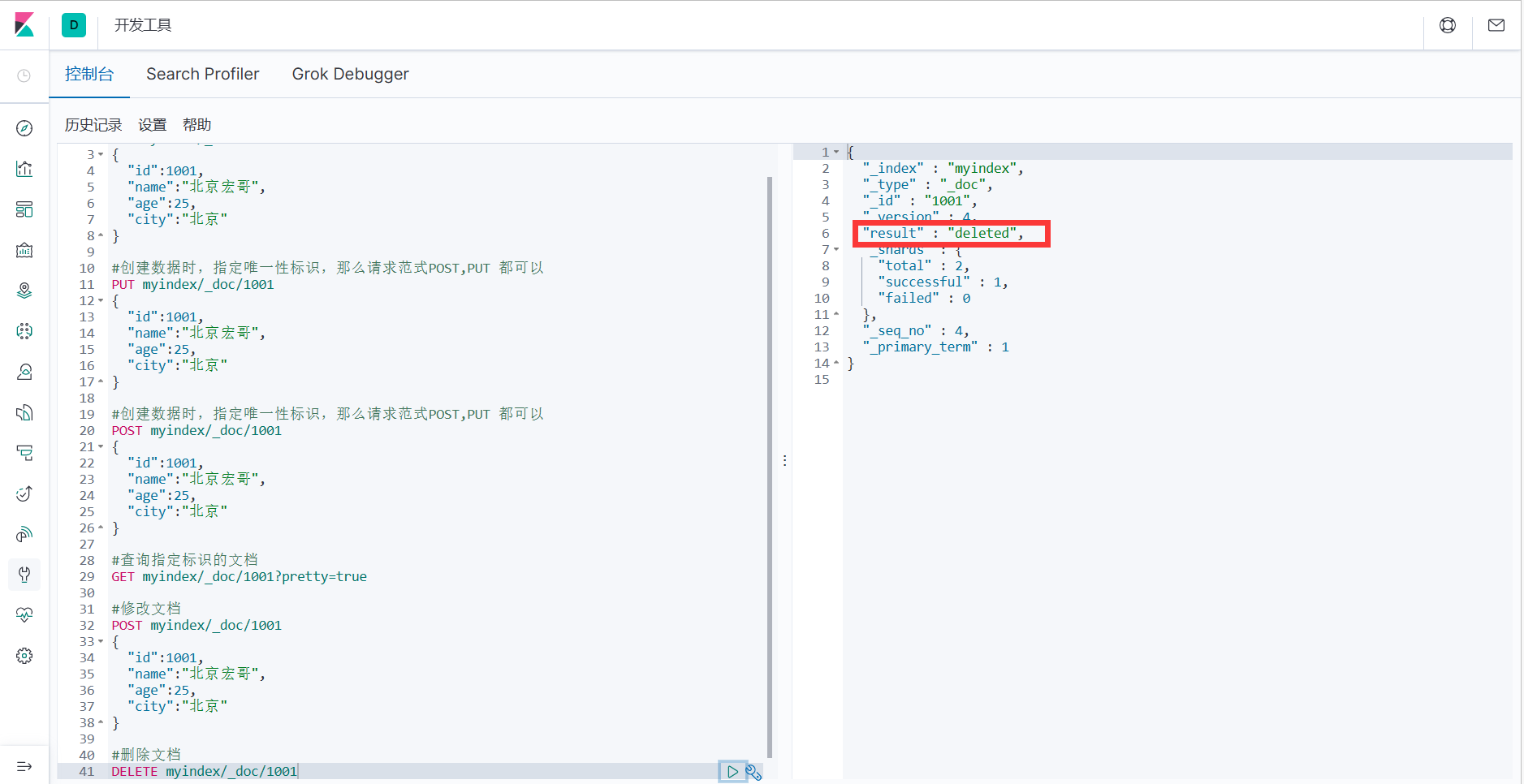
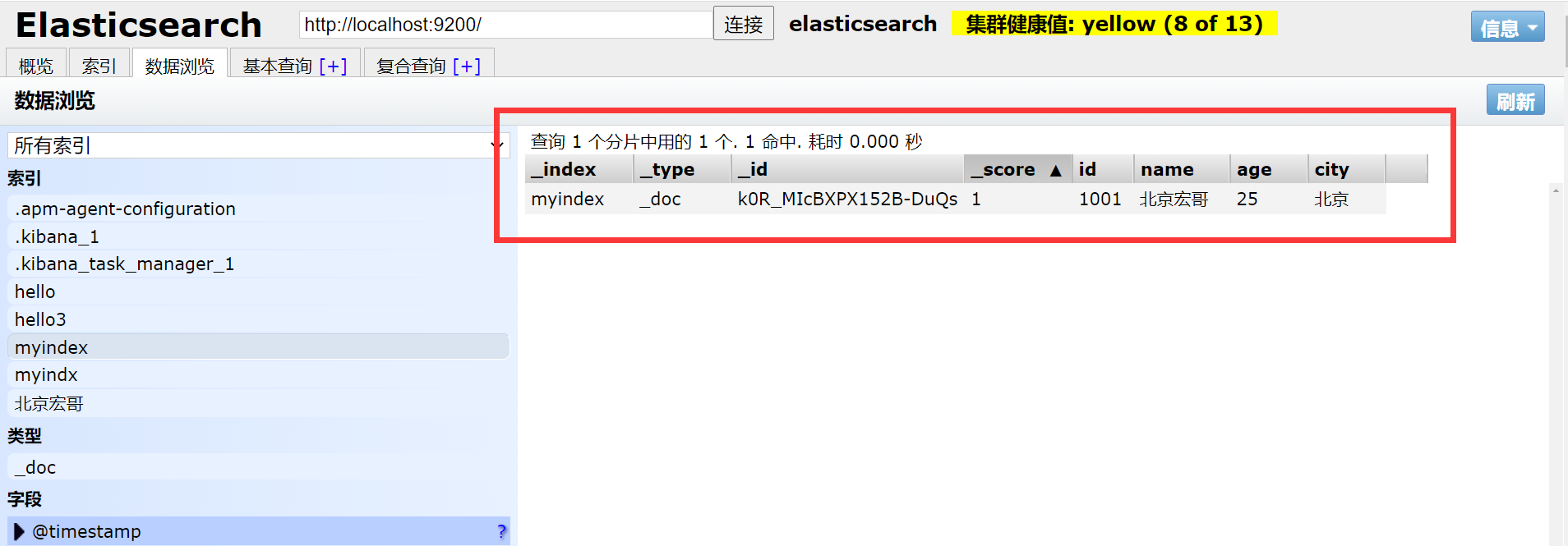
#查询所有文档
GET myindex/_search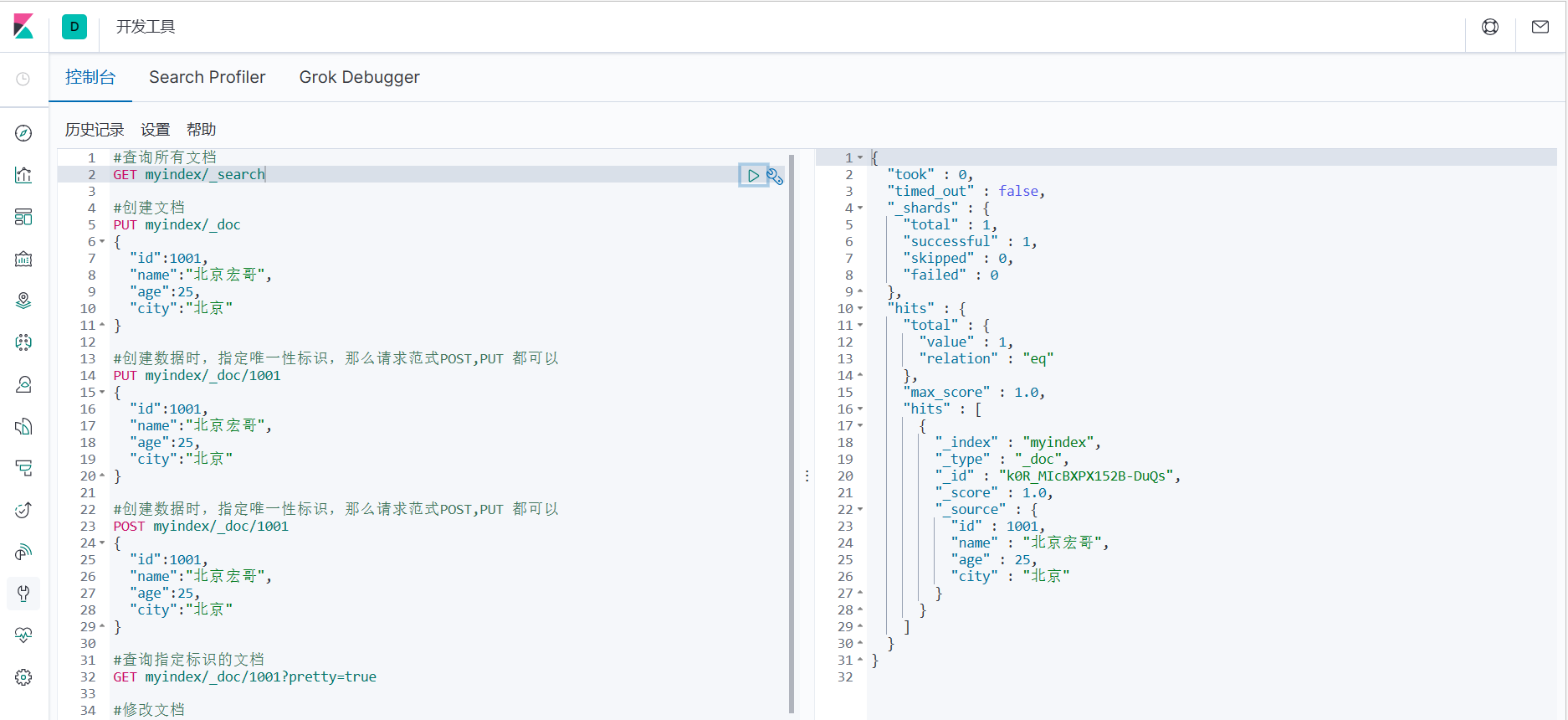
1.为了方便演示,事先准备多条数据
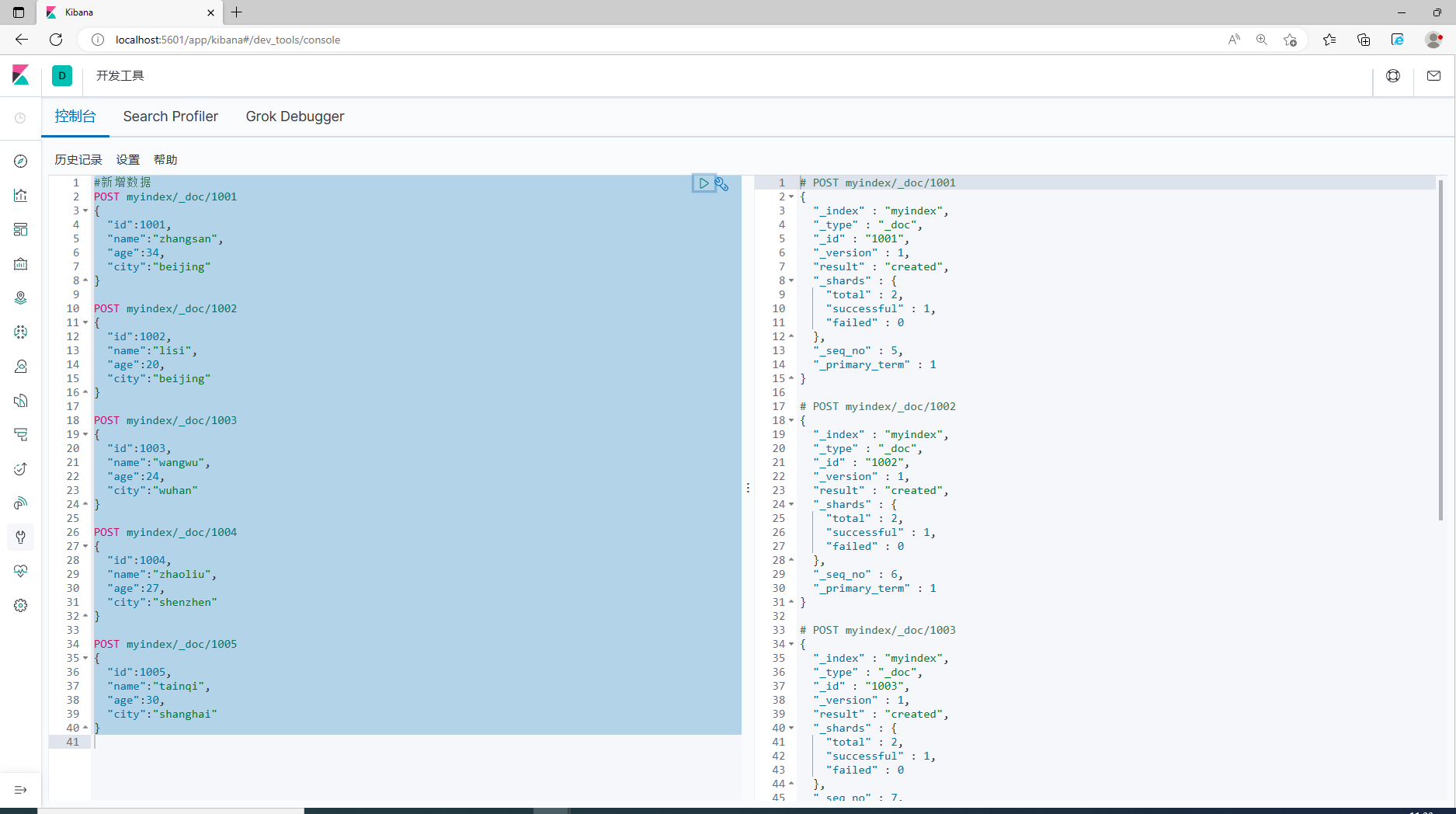
#查询所有文档
GET myindex/_search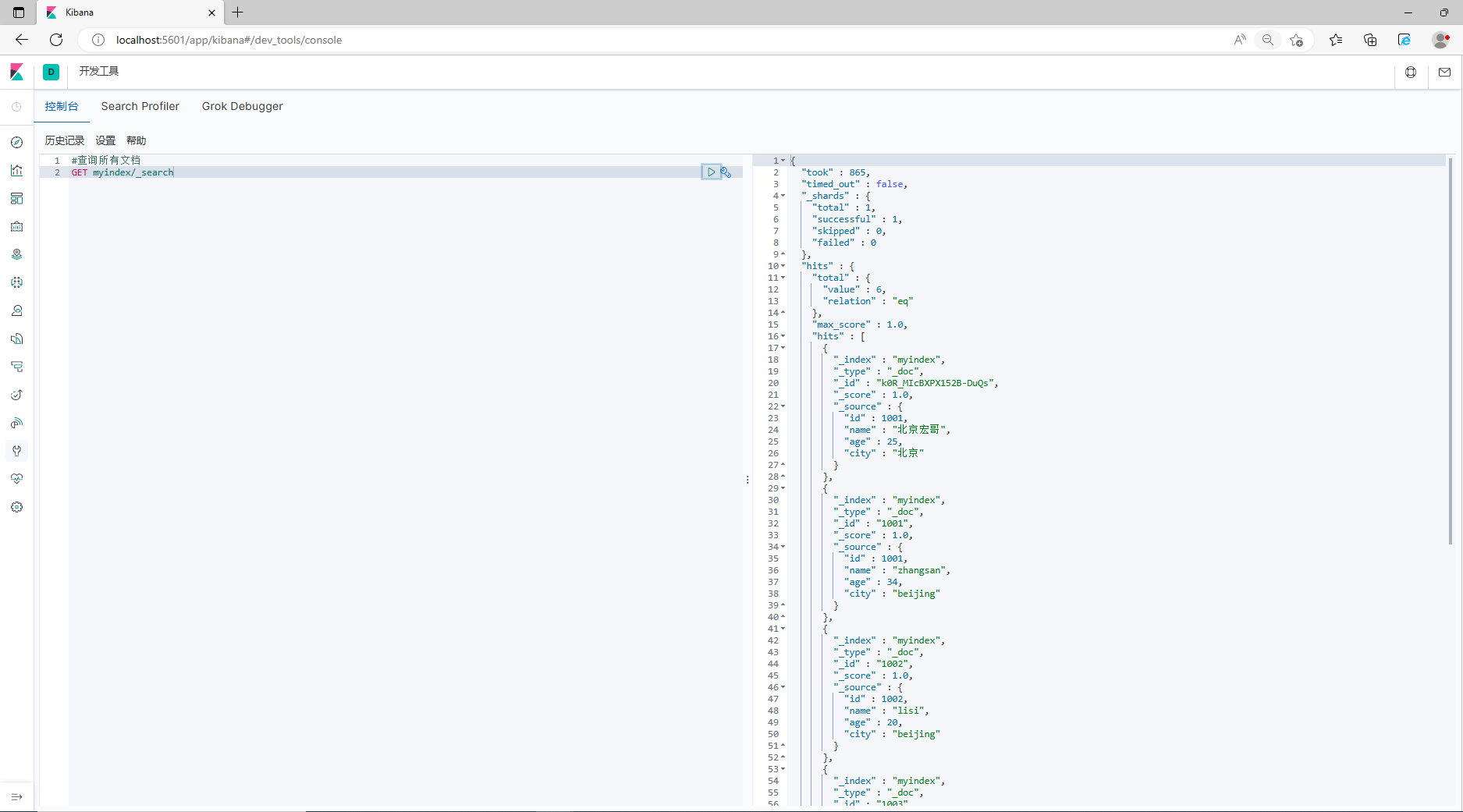
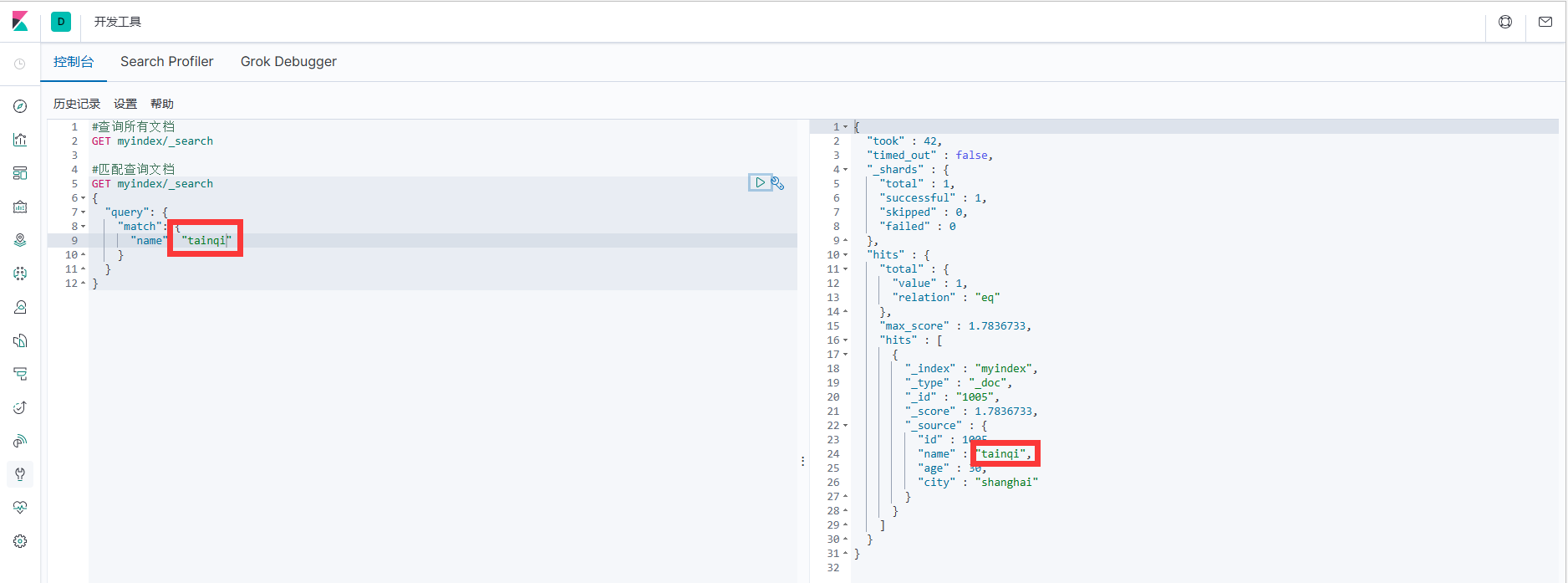
这里的查询表示文档数据中 JSON 对象数据中的 name 属性是 tianqi。
#匹配查询文档
GET myindex/_search
{
"query": {
"match": {
"name": "tainqi"
}
}
}
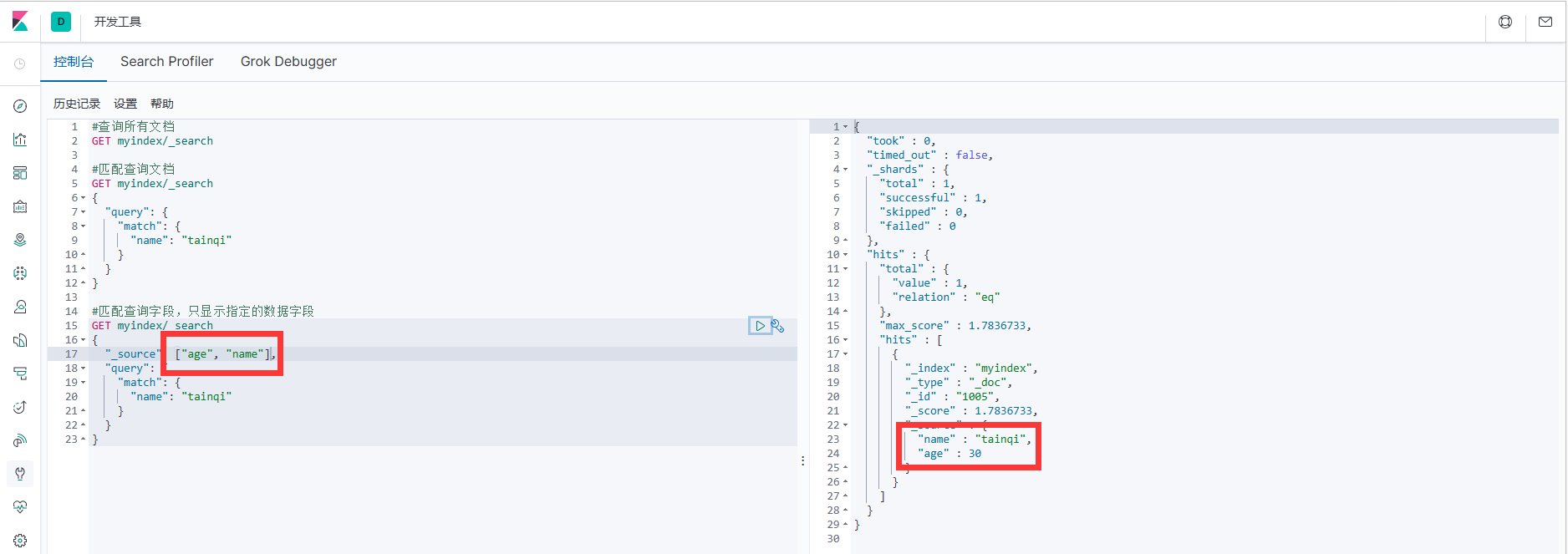
默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在_source 的所有字段都返回。 如果我们只想获取其中的部分字段,我们可以添加_source 的过滤
#匹配查询字段,只显示指定的数据字段
GET myindex/_search
{
"_source": ["age", "name"],
"query": {
"match": {
"name": "tainqi"
}
}
}
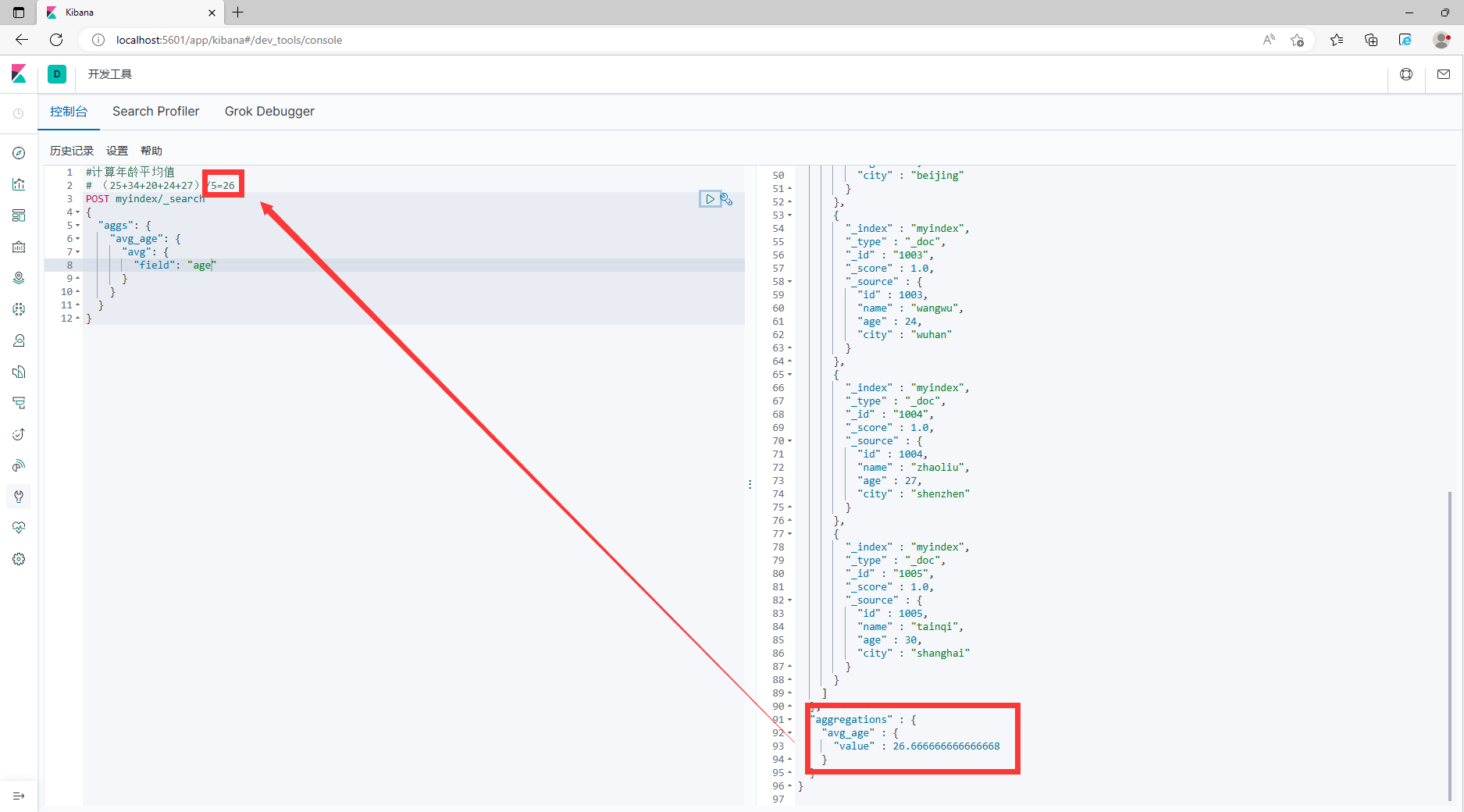
聚合允许使用者对es 文档进行统计分析,类似与关系型数据库中的 group by ,当然还有很多其他的聚合,例如取最大值、平均值等等。
#计算年龄平均值
# (25+34+20+24+27)/5=26
POST myindex/_search
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
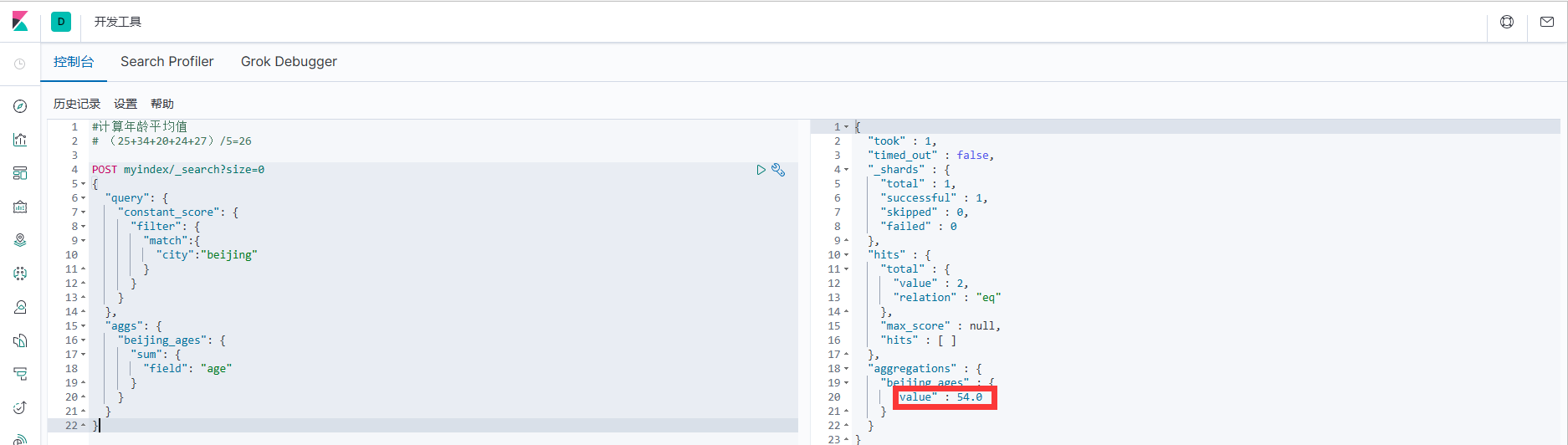
1.如首先查询出城市是:北京,然后将其的年龄相加求和。
POST myindex/_search?size=0
{
"query": {
"constant_score": {
"filter": {
"match":{
"city":"beijing"
}
}
}
},
"aggs": {
"beijing_ages": {
"sum": {
"field": "age"
}
}
}
}
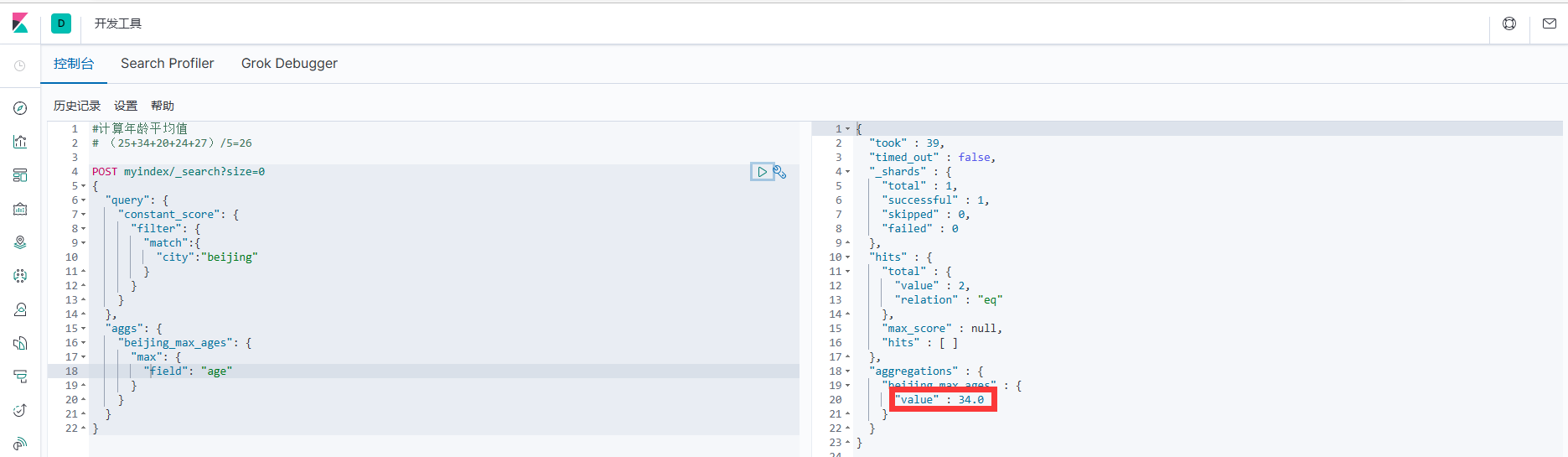
1.如首先查询出城市是:北京,然后将其的年龄对比出最大的年龄。
POST myindex/_search?size=0
{
"query": {
"constant_score": {
"filter": {
"match":{
"city":"beijing"
}
}
}
},
"aggs": {
"beijing_max_ages": {
"max": {
"field": "age"
}
}
}
}
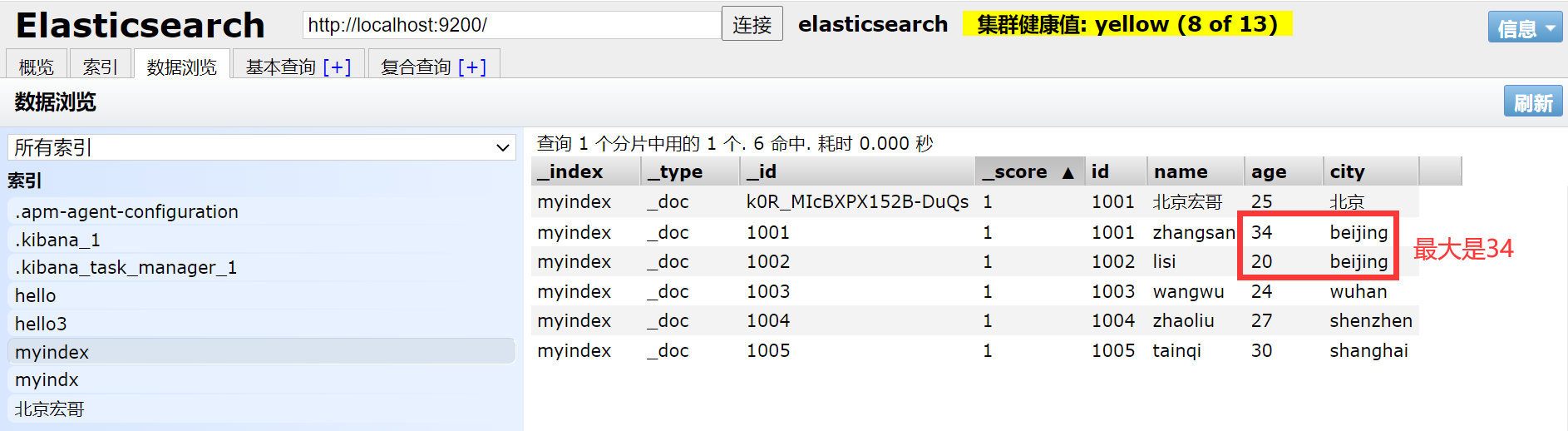
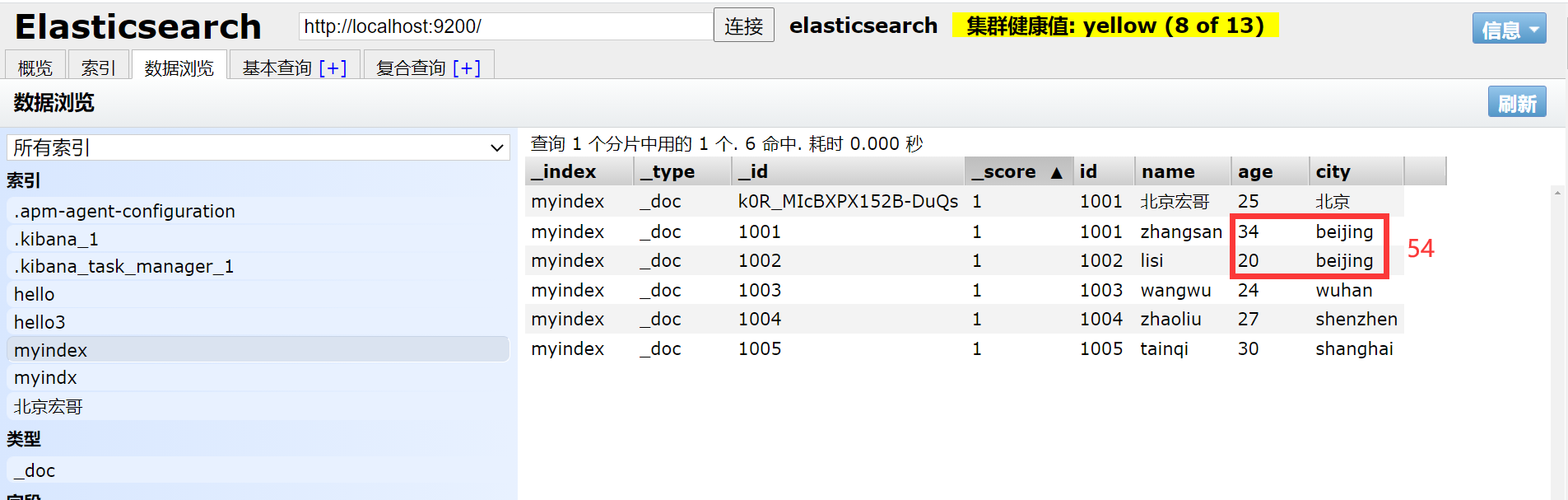
1.首先宏哥将之前的数据更新一下,方便后边的演示。
#更新数据
POST myindex/_doc/1001
{
"id":1001,
"name":"zhangsan",
"age":"21",
"city":"beijing"
}
POST myindex/_doc/1002
{
"id":1002,
"name":"lisi",
"age":"25",
"city":"shanghai",
"money":"5000"
}
POST myindex/_doc/1003
{
"id":1003,
"name":"wangwu",
"age":"26",
"city":"beijing",
"money":"6000"
}
POST myindex/_doc/1004
{
"id":1004,
"name":"zhaoliu",
"age":"27",
"city":"shenzhen",
"money":"8000"
}
POST myindex/_doc/1005
{
"id":1005,
"name":"tianqi",
"age":"29",
"city":"wuhan",
"money":"5000"
}
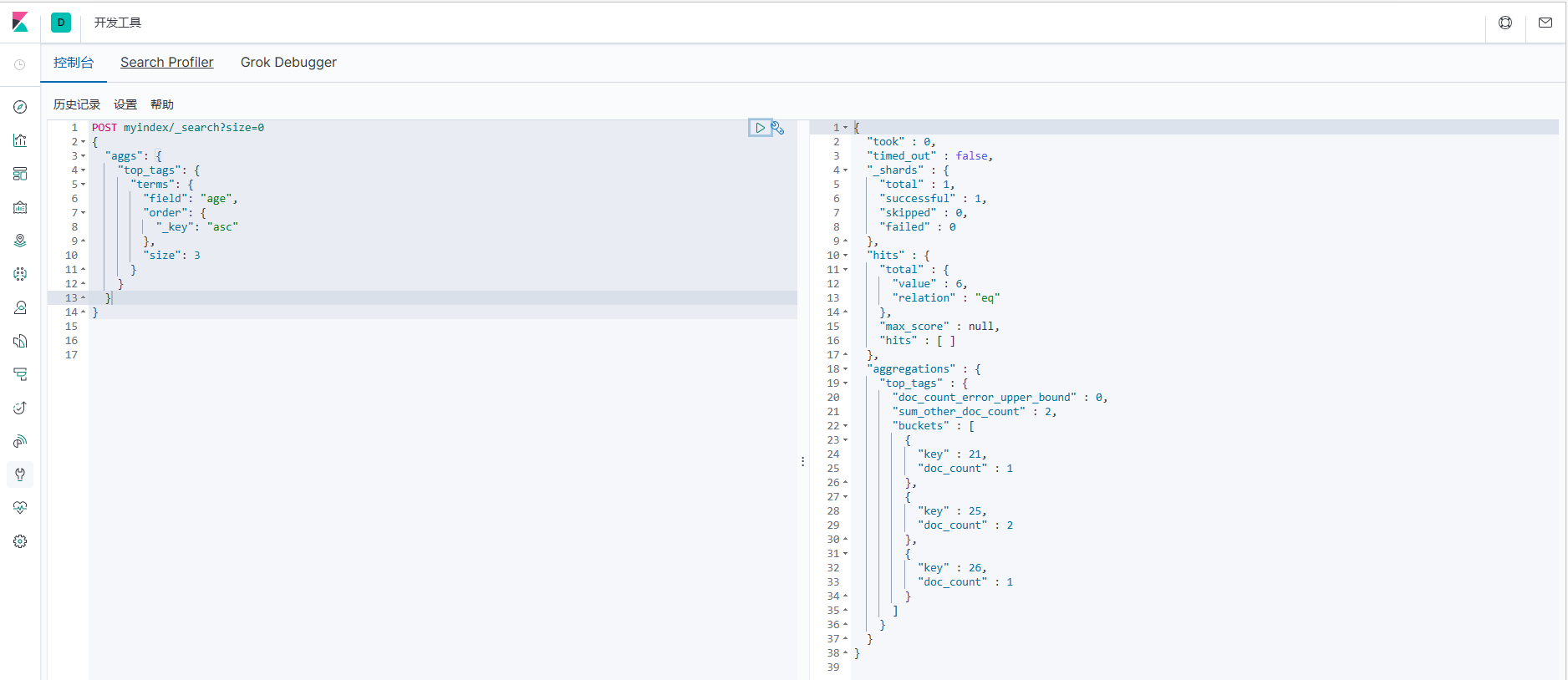
2.通过_key进行升序排列进行查询3条记录。
我们之前对索引进行一些配置信息设置,但是都是在单个索引上进行设置。在实际开发 中,我们可能需要创建不止一个索引,但是每个索引或多或少都有一些共性。比如我们在设 计关系型数据库时,一般都会为每个表结构设计一些常用的字段,比如:创建时间,更新时 间,备注信息等。elasticsearch 在创建索引的时候,就引入了模板的概念,你可以先设置一 些通用的模板,在创建索引的时候,elasticsearch 会先根据你创建的模板对索引进行设置。
elasticsearch 中提供了很多的默认设置模板,这就是为什么我们在新建文档的时候,可以为 你自动设置一些信息,做一些字段转换等。
索引可使用预定义的模板进行创建,这个模板称作 Index templates。模板设置包括 settings 和 mappings
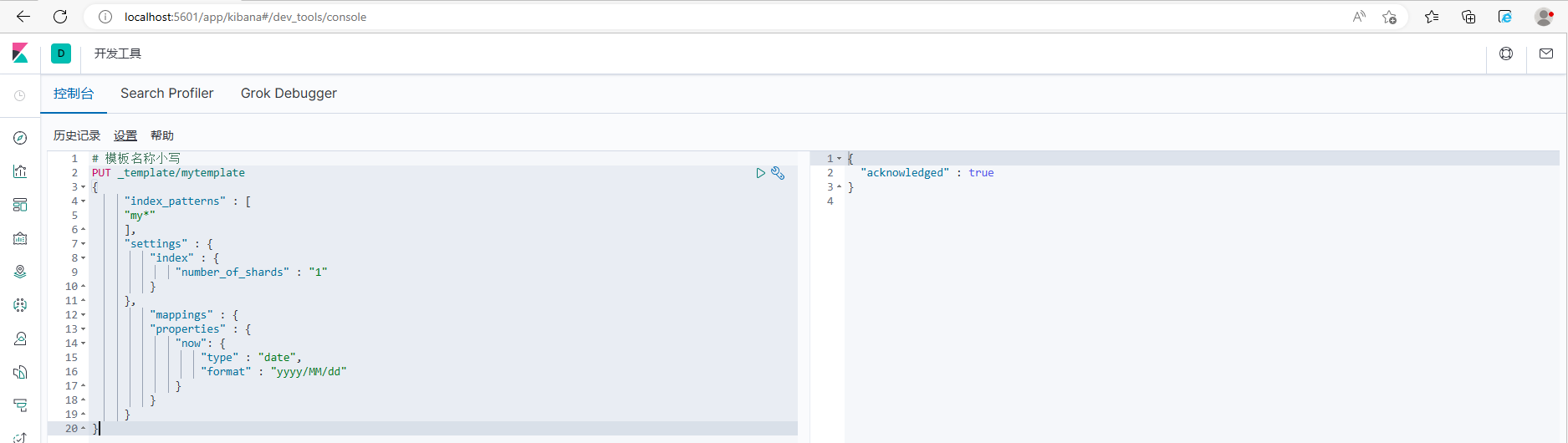
# 模板名称小写
PUT _template/mytemplate
{
"index_patterns" : [
"my*"
],
"settings" : {
"index" : {
"number_of_shards" : "1"
}
},
"mappings" : {
"properties" : {
"now": {
"type" : "date",
"format" : "yyyy/MM/dd"
}
}
}
}
# 查看模板
GET /_template/mytemplate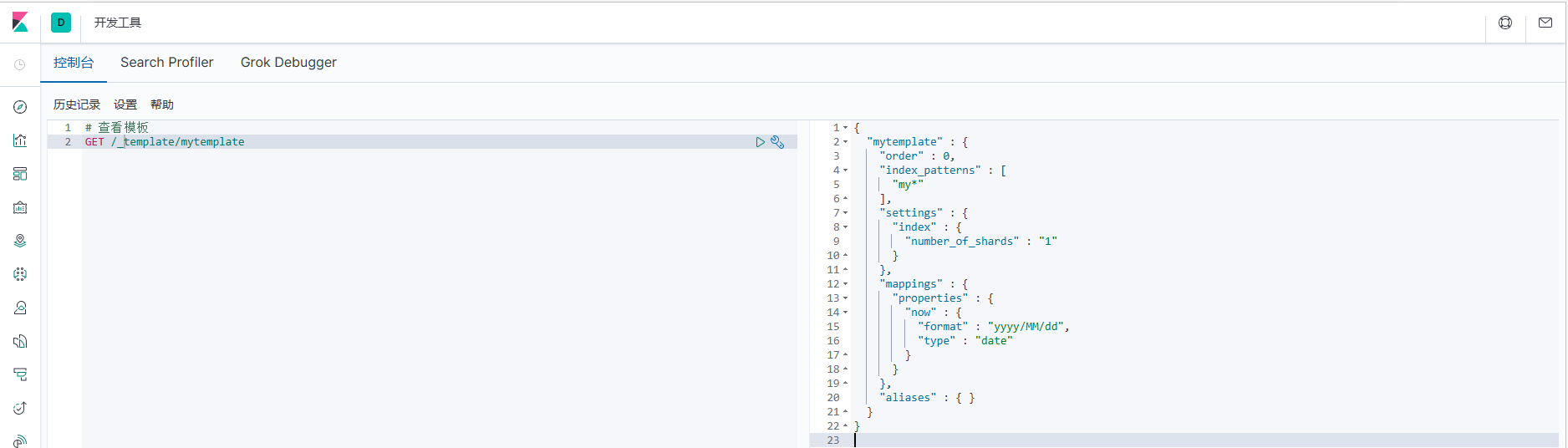
#验证模板
HEAD /_template/mytemplate
#创建索引
PUT mytest
#查询索引
GET mytest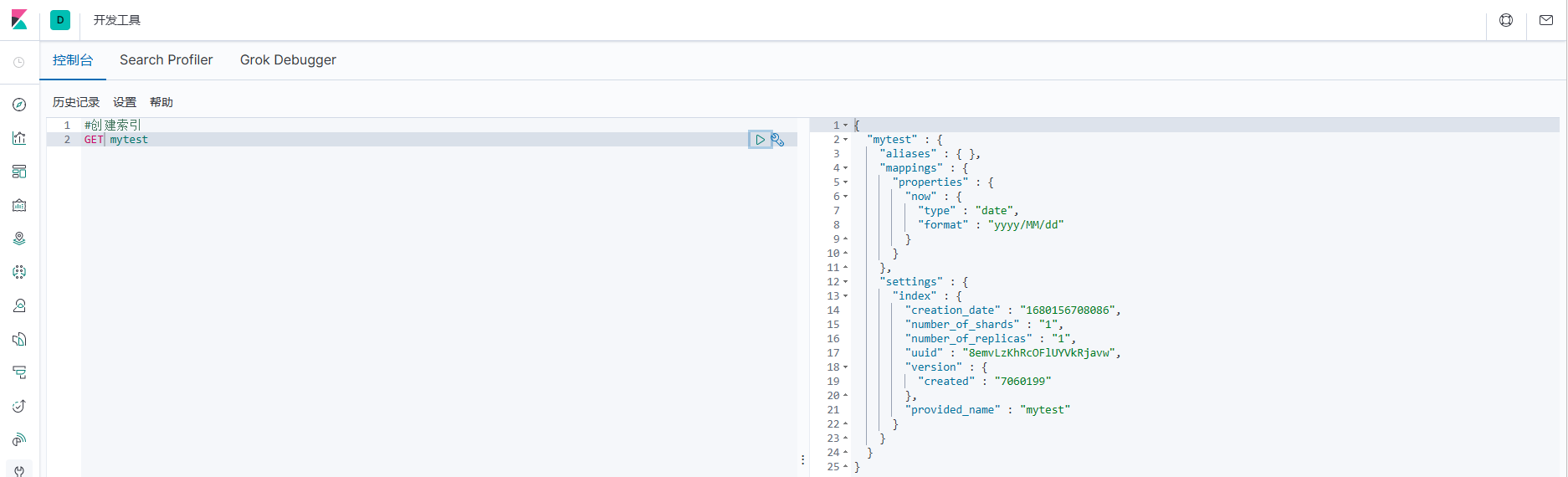
#删除模板
DELETE /_template/mytemplate
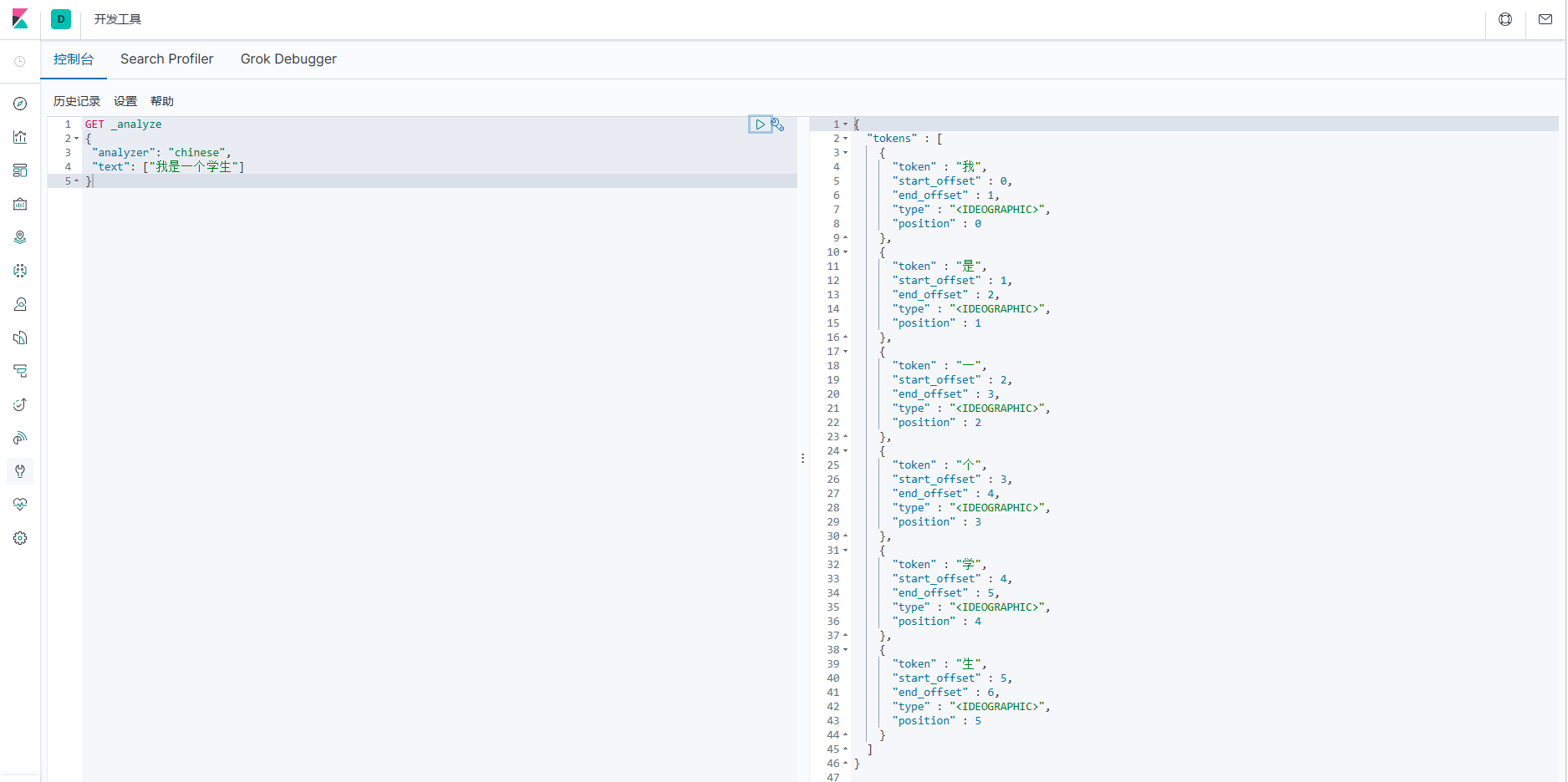
我们在使用 Elasticsearch 官方默认的分词插件时会发现,其对中文的分词效果不佳,经常分词后得效果不是我们想要得,
GET _analyze
{
"analyzer": "chinese",
"text": ["我是一个学生"]
}
为了能够更好地对中文进行搜索和查询,就需要在Elasticsearch中集成好的分词器插件, 而 IK 分词器就是用于对中文提供支持得插件。这个在上一篇文章中已经介绍这里不做赘述。
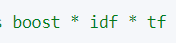
Lucene 和 ES 的得分机制是一个基于词频和逆文档词频的公式,简称为 TF-IDF 公式
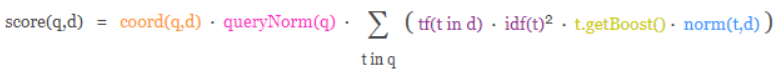
公式中将查询作为输入,使用不同的手段来确定每一篇文档的得分,将每一个因素最后 通过公式综合起来,返回该文档的最终得分。这个综合考量的过程,就是我们希望相关的文 档被优先返回的考量过程。在 Lucene 和 ES 中这种相关性称为得分。
考虑到查询内容和文档得关系比较复杂,所以公式中需要输入得参数和条件非常得多。但是其中比较重要得其实是两个算法机制
接下来咱们用一个例子简单分析一下文档的打分机制:
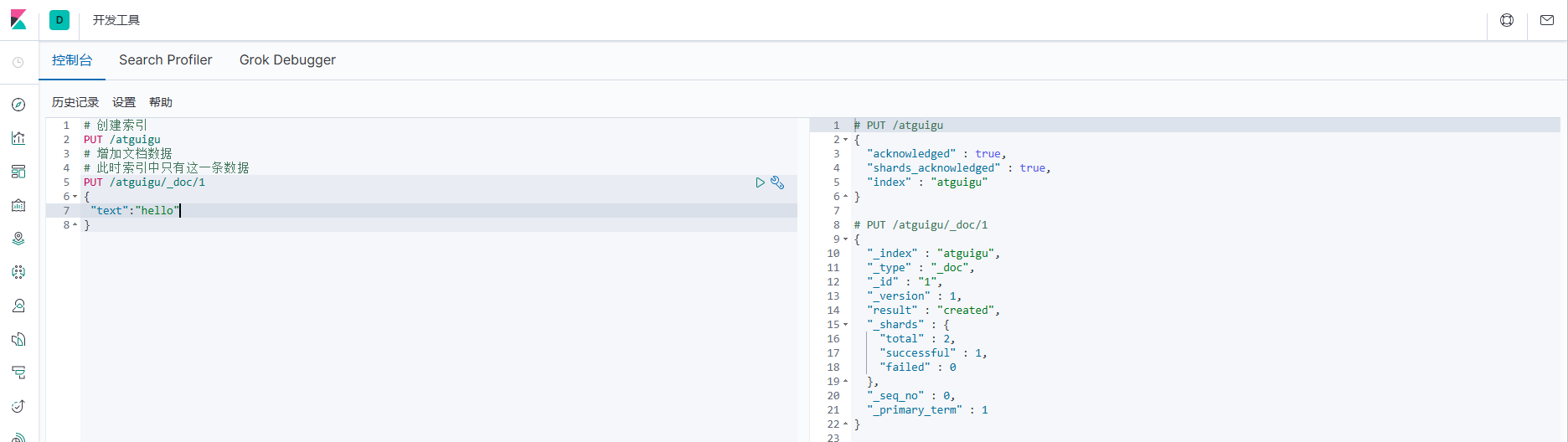
1.首先,先准备一个基础数据
# 创建索引
PUT /atguigu
# 增加文档数据
# 此时索引中只有这一条数据
PUT /atguigu/_doc/1
{
"text":"hello"
}
2.查询匹配条件的文档数据
GET /atguigu/_search
{
"query": {
"match": {
"text": "hello"
}
}
}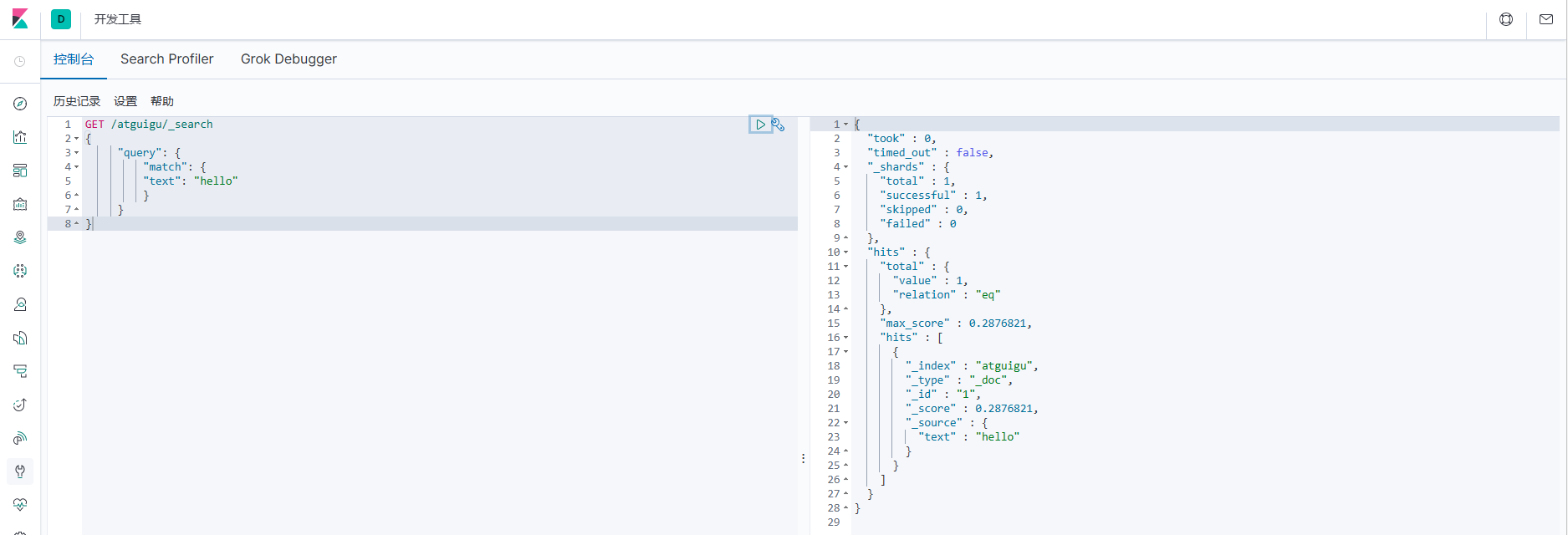
这里文档的得分为:0.2876821,很奇怪,此时索引中只有一个文档数据,且文档数据中可 以直接匹配查询条件,为什么分值这么低?这就是公式的计算结果,咱们一起来看看
1.分析文档数据打分过程
# 增加分析参数
GET /atguigu/_search?explain=true
{
"query": {
"match": {
"text": "hello"
}
}
}2.执行后,会发现打分机制中有 2 个重要阶段:计算 TF 值和 IDF 值
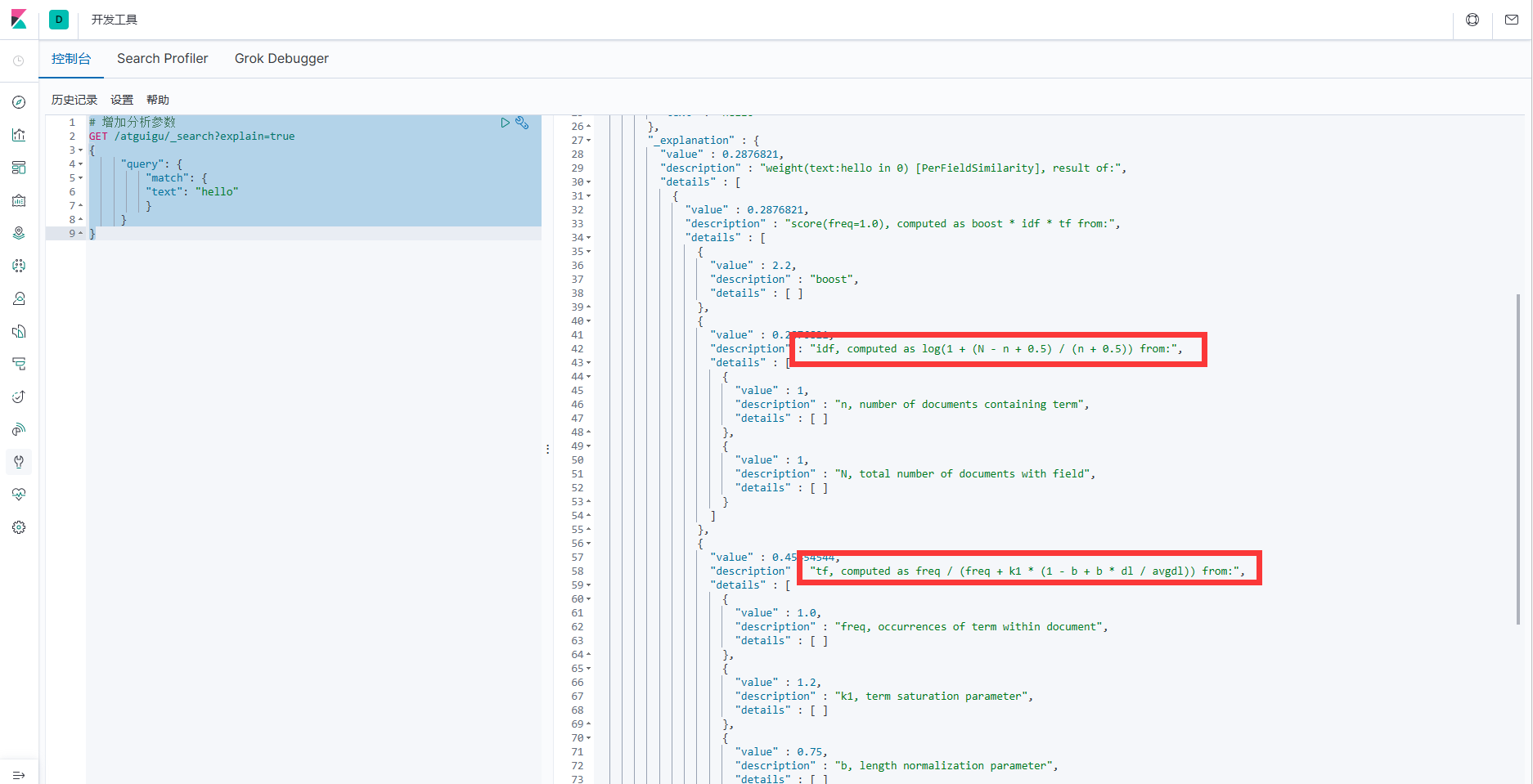
3.最后的分数为:
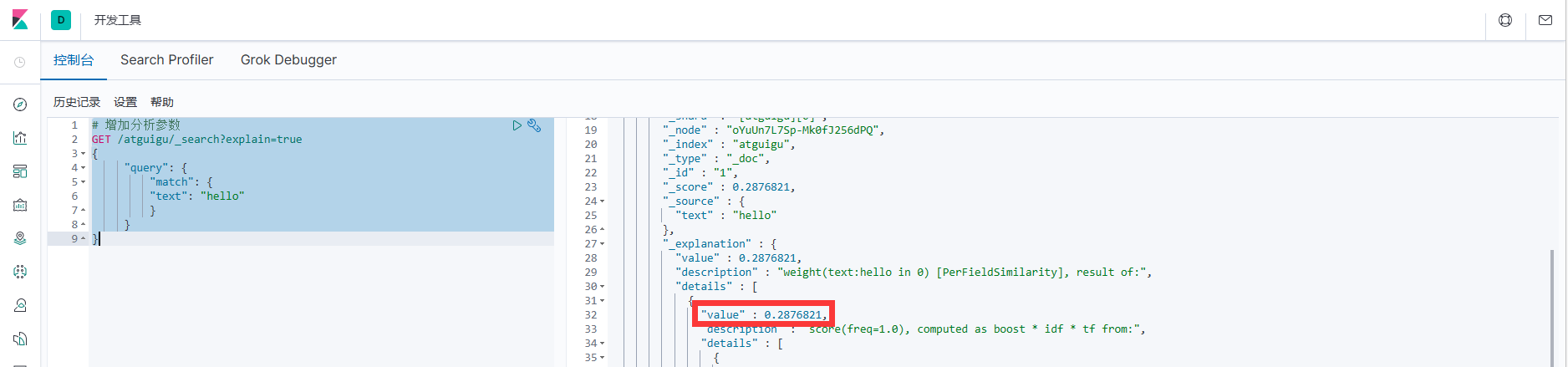
4.计算 TF 值
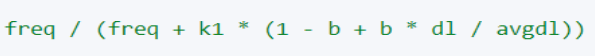
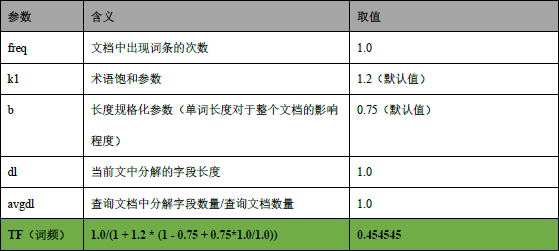
5.计算 IDF 值
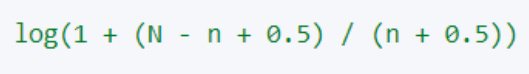

注:这里的log 是底数为 e 的对数
6.计算文档得分

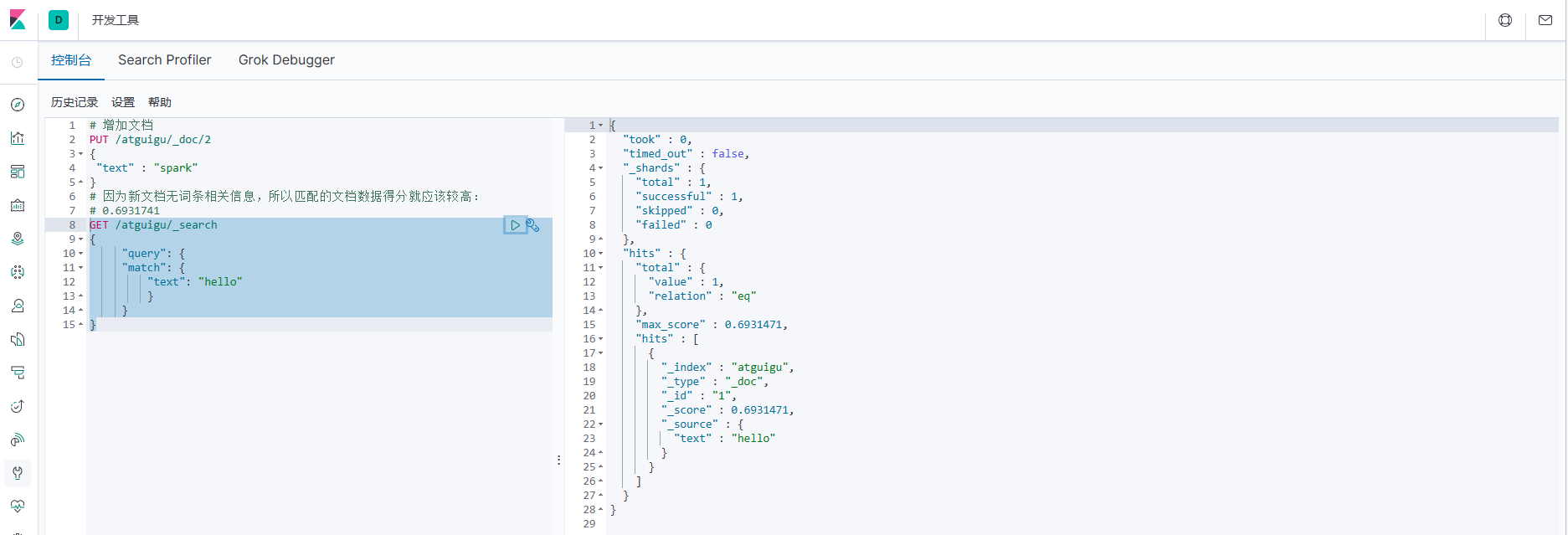
7.增加新的文档,测试得分 !.增加一个毫无关系的文档
# 增加文档
PUT /atguigu/_doc/2
{
"text" : "spark"
}
# 因为新文档无词条相关信息,所以匹配的文档数据得分就应该较高:
# 0.6931741
GET /atguigu/_search
{
"query": {
"match": {
"text": "hello"
}
}
}
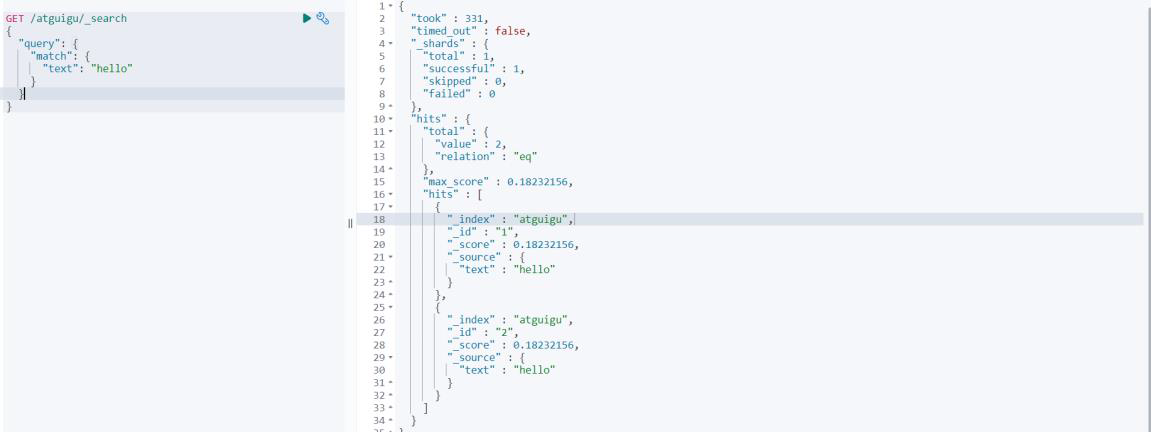
ii.增加一个一模一样的文档
# 增加文档
PUT /atguigu/_doc/2
{
"text" : "hello"
}
# 因为新文档含词条相关信息,且多个文件含有词条,所以显得不是很重要,得分会变低
# 0.18232156
GET /atguigu/_search
{
"query": {
"match": {
"text": "hello"
}
}
}
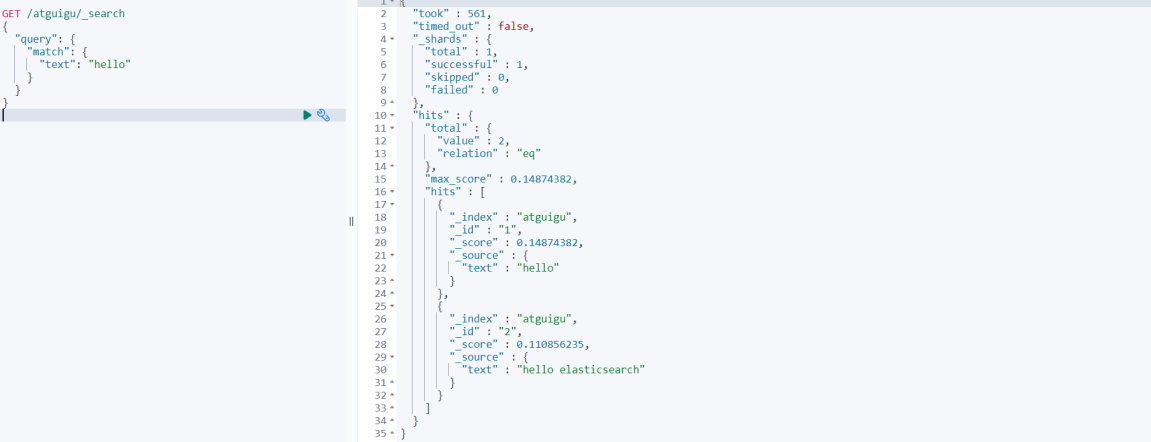
iii.增加一个含有词条,但是内容较多的文档
# 增加文档
PUT /atguigu/_doc/2
{
"text" : "hello elasticsearch"
}
# 因为新文档含词条相关信息,但只是其中一部分,所以查询文档的分数会变得更低一些。
# 0.14874382
GET /atguigu/_search
{
"query": {
"match": {
"text": "hello"
}
}
}
需求:
查询文档标题中含有“Hadoop”,“Elasticsearch”,“Spark”的内容。
优先选择“Spark”的内容
1.准备数据
# 准备数据
PUT /testscore/_doc/1001
{
"title" : "Hadoop is a Framework",
"content" : "Hadoop 是一个大数据基础框架"
}
PUT /testscore/_doc/1002
{
"title" : "Hive is a SQL Tools",
"content" : "Hive 是一个 SQL 工具"
}
PUT /testscore/_doc/1003
{
"title" : "Spark is a Framework",
"content" : "Spark 是一个分布式计算引擎"
}2.查询数据
# 准备数据
PUT /testscore/_doc/1001
{
"title" : "Hadoop is a Framework",
"content" : "Hadoop 是一个大数据基础框架"
}
PUT /testscore/_doc/1002
{
"title" : "Hive is a SQL Tools",
"content" : "Hive 是一个 SQL 工具"
}
PUT /testscore/_doc/1003
{
"title" : "Spark is a Framework",
"content" : "Spark 是一个分布式计算引擎"
}此时,你会发现,Spark 的结果并不会放置在最前面
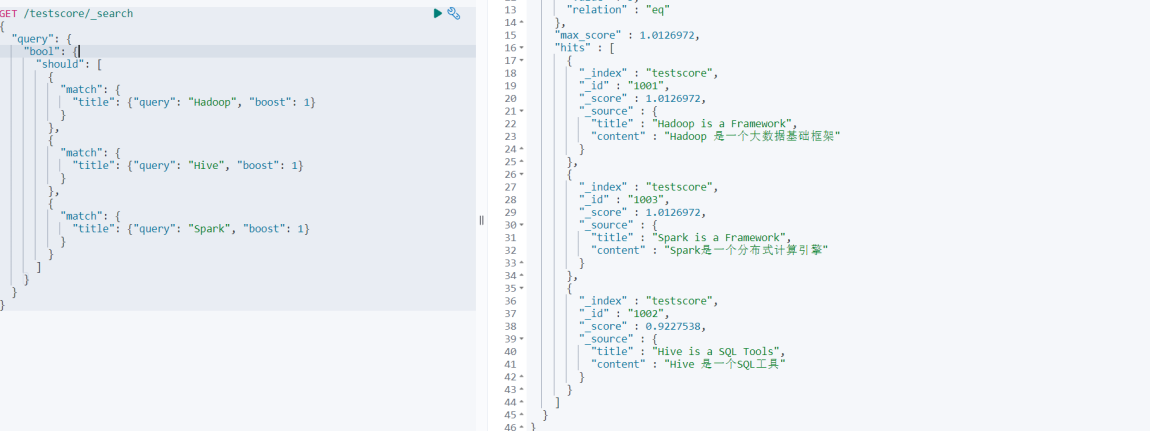
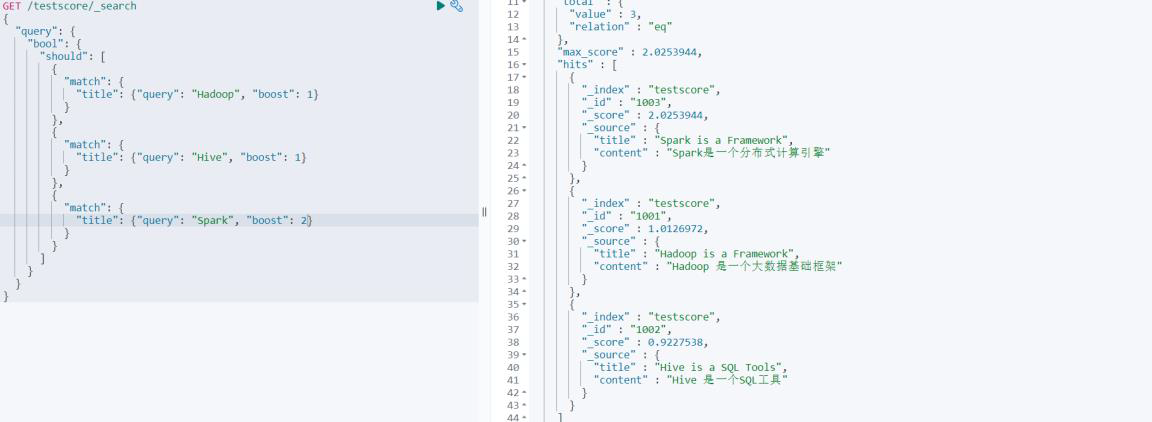
此时,咱们可以更改Spark 查询的权重参数 boost. 看看查询的结果有什么不同
# 查询文档标题中含有“Hadoop”,“Elasticsearch”,“Spark”的内容
GET /testscore/_search?explain=true
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {"query": "Hadoop", "boost": 1}
}
},
{
"match": {
"title": {"query": "Hive", "boost": 1}
}
},
{
"match": {
"title": {"query": "Spark", "boost": 2}
}
}
]
}
}
}
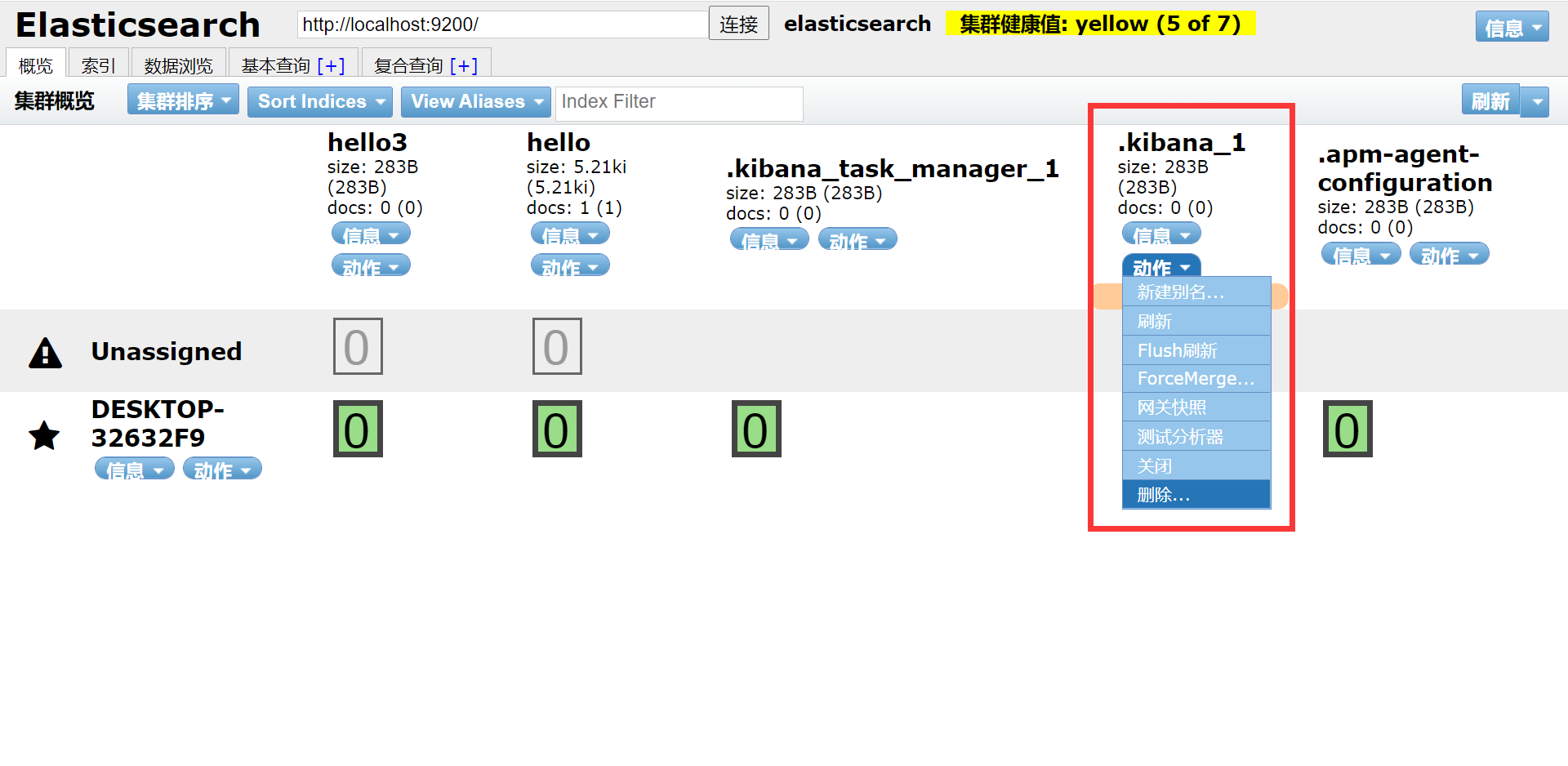
【ElasticSearch】Kibana启动报错: Another Kibana instance appears to be migrating the index.....
Another Kibana instance appears to be migrating the index. Waiting for that migration to complete. If no other Kibana instance is attempting migrations, you can get past this message by deleting index .kibana_1 and restarting Kibana.
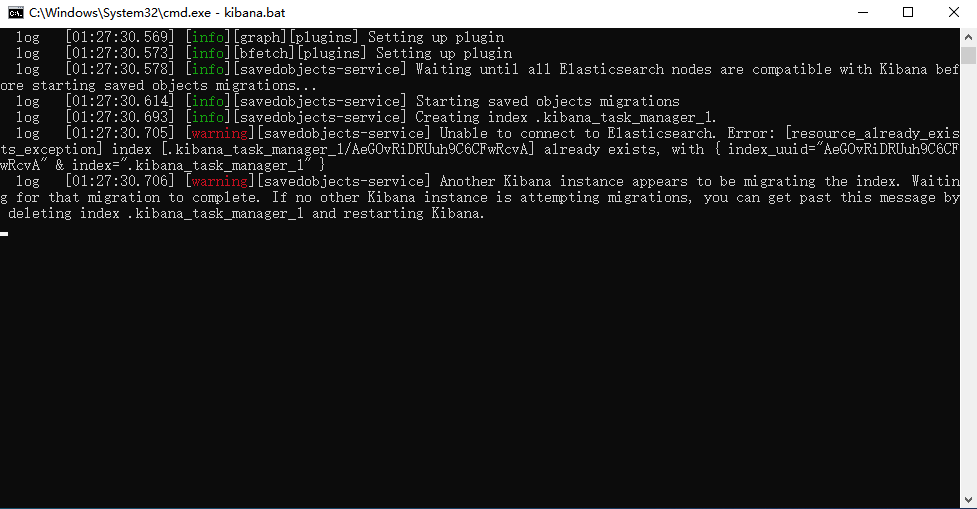
解决:删除出错的索引
使用head 客户端插件,删除 kibana_1、.kibana_task_manager_1节点,重新启动即可。