

Quartz一款功能丰富、历史悠久,完全基于Java实现的开源任务调度框架,Java调度领域知名度非常高。其简单易用、稳定可靠的特性,使其被很多第三方应用将其当成调度框架基础依赖,如spring boot已内置集成quartz,elastic-job调度框架则将quartz作为其底层基础实现进行封装,xxl-job曾经历史版本也是集成quartz作为其触发实现机制基础,不过在最新版本采用时间轮实现已将quartz移除。
使用quartz api时,最核心三件套如下:
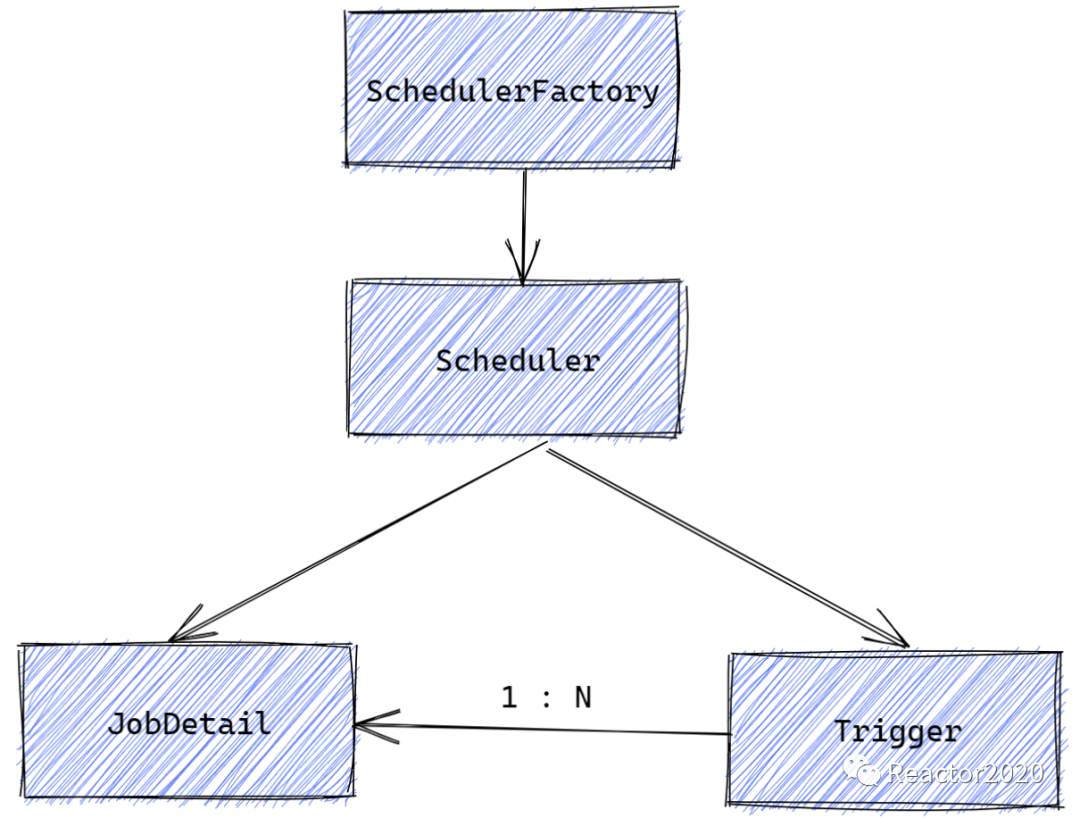
SchedulerFactory和Scheduler从名称就很容易识别这里采用工厂设计模式,Scheduler是quartz暴露出来供开发使用的一个最重要组件,从开发者视角来看它就是quartz的门面,对quartz的各种操作都是通过Scheduler进行串联,类似于quartz的大管家、代言人角色。
“这种设计模式在开源框架中很常见,比如
mybatis中SqlSessionFactory和SqlSession,通过给开发者提供大管家组件,通过一个组件串联起所有核心功能,简化了开发人员上手框架难度。
一般一个应用只会对应一个Scheduler实例,不同Scheduler实例之间通过schedulerName进行隔离,所有的quartz数据库表设计中都有sched_name这一列字段,这样Scheduler处理任务时只会操作数据库表中对应schedulerName下的数据。quartz集群就是利用多个Scheduler实例配置相同schedulerName名称,实现多机器同时处理同一个schedulerName下任务来达到集群效果。
“
schedulerName可以通过org.quartz.scheduler.instanceName进行配置,默认名称为QuartzScheduler。
Scheduler操作的主要是JobDetail和Trigger两个组件,JobDetail封装的是任务配置信息,而Trigger触发器封装了任务触发信息,它们是1:N关系,即一个JobDetail可以关联多个Trigger触发器,但是一个Trigger触发器只能绑定到一个Job上。
JobDetail组件封装了quartz调度任务定义信息,下面是JobDetail组件常规使用方式如下:
// JobDataMap实现Map接口,任务调度时存储到JobExecuteContext中,可以传递给Job实例
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.put("name", "zhangsan");
jobDataMap.put("time", System.currentTimeMillis());
JobDetail jobDetail = JobBuilder
// 绑定任务类
.newJob(QuartzCronJob.class)
.storeDurably()
// job对应ID
.withIdentity("job2", "DEFAULT")
.usingJobData(jobDataMap)
.build();
JobKey jobKey = jobDetail.getKey();
if (scheduler.checkExists(jobKey)) {
log.warn("调度任务已存在,删除后重新添加:{}", jobKey);
scheduler.interrupt(jobKey);//停止JOB
/**
* deleteJob操作在删除Job之前,会执行unscheduleJob()取消job和trigger关联
*/
scheduler.deleteJob(jobKey);
}
// 将JobDetail任务定义信息插入quartz表
scheduler.addJob(jobDetail, true);
JobDetail操作比较简单,主要有两点需要注意:1、newJob(Class <? extends Job> jobClass)操作绑定任务类,任务类就是封装用户业务逻辑类;2、withIdentity(String name, String group)给该任务设置一个身份ID,后续可以通过该身份ID进行管理,为方便灵活管理quartz抽象出group概念,这样可以批量对一组作业进行批量操作,身份ID使用JobKey进行封装。
使用Scheduler类addJob(JobDetail jobDetail, boolean replace)方法就将创建的Job定义信息添加到quartz中,一般采用数据库持久化模式,即这里就会将Job定义信息插入到qrtz_job_details表中(见下图)。

下面来看下几个关键字段:
sched_name:上面说过,用来关联对应的Scheduler实例
is_durable:是否持久化
is_nonconcurrent:是否允许同一个作业可以同时多个实例执行,比如一个任务间隔1秒,但其执行时间为2秒,通过该属性控制是否允许同一个作业有多个任务同时允许,参见@DisallowConcurrentExecution
is_update_data: 任务已经执行中,是否允许更新JobDataMap持久化信息,参见@PersistJobDataAfterExecution
requests_recovery: 故障恢复使用,具体参见后续源码分析
job_data:JobDataMap序列化后存储到字段中
任务定义完成,但是任务按照怎么周期性规则进行触发执行,这就要看Trigger触发器的脸色了
Trigger组件常规使用方式如下:
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.put("name", "lisi");
jobDataMap.put("address", "China");
Trigger trigger = TriggerBuilder
.newTrigger()
.withIdentity("trigger1", "DEFAULT")
.usingJobData(jobDataMap)
.startAt(new Date())
.endAt(new Date(System.currentTimeMillis()+38 * 60 * 1000))
.withSchedule(CronScheduleBuilder.cronSchedule("*/10 * * * * ?"))
.forJob(new JobKey("job1", "DEFAULT"))
.build();//时间
TriggerKey triggerKey = trigger.getKey();
if(scheduler.checkExists(triggerKey)){
scheduler.unscheduleJob(triggerKey);
}
//必须绑定job
scheduler.scheduleJob(trigger);
和JobDetail类似,主要有两点需要注意:1、同withIdentity(String name, String group),同理给该触发器设置一个身份ID,对应TriggerKey;2、startAt()、endAt()对应启止时间;3、withSchedule(CronScheduleBuilder.cronSchedule("*/10 * * * * ?"));4、forJob(JobKey keyOfJobToFire)将Trigger与Job进行关联,这样才知道触发哪个任务。

最后通过Scheduler类scheduleJob(Trigger trigger)方法就将创建的Trigger定义信息添加到quartz中,一般采用数据库持久化模式,即这里就会将Trigger定义信息插入到触发器相关表中,示例中使用cron触发器,则插入到qrtz_cron_triggers表中(见下图)。


下面我们就来看下任务是咋个触发的。Scheduler类scheduleJob(Trigger trigger)将触发器持久化后,你会发现qrtz_cron_triggers中没有起止时间以及和Job绑定内容,所以,接下来我们看一张非常重要表:qrtz_triggers。scheduleJob()方法在持久化Trigger信息后会同时向qrtz_triggers表插入一条记录(见下图):

qrtz_job_details和qrtz_cron_triggers可以看成静态表,那qrtz_triggers就是运行动态表,保存着任务运行期间数据,且随着运行记录在动态变更,是quartz调度任务运行最重要的一张表,下面我们来看下这张表中几个关键字段:
start_time、end_time: trigger定义时设置的起止时间
next_fire_time: 下次触发时间戳
prev_fire_time: 上次触发时间戳
trigger_state: trigger状态,最常见状态WAITING、ACQUIRED和EXECUTING,分别对应等待(下次触发时间还早) -> 加载到内存中等待(下次触发时间快到了) --> 执行(下次触发时间到了,需要触发任务),具体参见后续源码分析
misfire_instr: trigger触发时间过期处理策略,比如本来是10:23:50时间点进行触发,但是由于某些原因在10:23:53秒才检索出来,这是该触发时间点已经过期,misfire_instr就是控制采用什么策略处理该过期任务,是直接丢弃重新计算下次触发时间点、还是一定时间范围内过期的理解执行等等,具体参见后续源码分析
job_data: 和JobDetail一样,Trigger也可绑定一个JobDataMap,用于向Job实例传递参数,该字段就是存储Trigger关联的JobDataMap序列化内容
quartz基本上就是围绕qrtz_triggers中这几个关键字段实现任务触发,我们连蒙带猜大致可以想出quartz任务调度触发机制粗略流程:
1、通过配置的trigger触发器,计算出下次触发时间,更新到next_fire_time字段,同时更新trigger_state状态为WAITING;
2、quartz线程扫描该表,从表中查询出未来很短一段时间将要触发的记录(比对next_fire_time和当前时间)放入到内存排队队列中,然后将trigger_state更新成ACQUIRED;
3、然后阻塞直到内存排队队列中触发任务到时间点,再触发任务之前,重新计算下次触发时间点,更新到next_fire_time,同时将trigger_state更新为WAITING,然后执行当前任务;
4、由于next_fire_time和trigger_state值更新,重新开始步骤1,就这样循环往复触发下去。
这节从一个使用者角度简单分析quartz核心运行机制,由于只是简单的从外层而未深入剖析源码,只是简单结合数据库表信息对quartz大致的运行机制做个简单猜想,一些重要属性也没展开,带着这些疑问下一节通过源码分析找到真实的答案,一步步加深对quartz运行机制的理解。
