

对象标识符是PostSQL很重要的一个特征,需要熟练掌握。
OID 是 PostgreSQL 内部用于标识数据库对象(数据库,表**,视图,**存储过程等等)的标识符,用4个字节的无符号整数表示。它是PostgreSQL大部分系统表的主键。
类型oid表示一个对象标识符。 也有多个oid的别名类型:regproc,regprocedure, regoper, regoperator,regclass, regtype, regrole,regnamespace, regconfig, 和regdictionary。
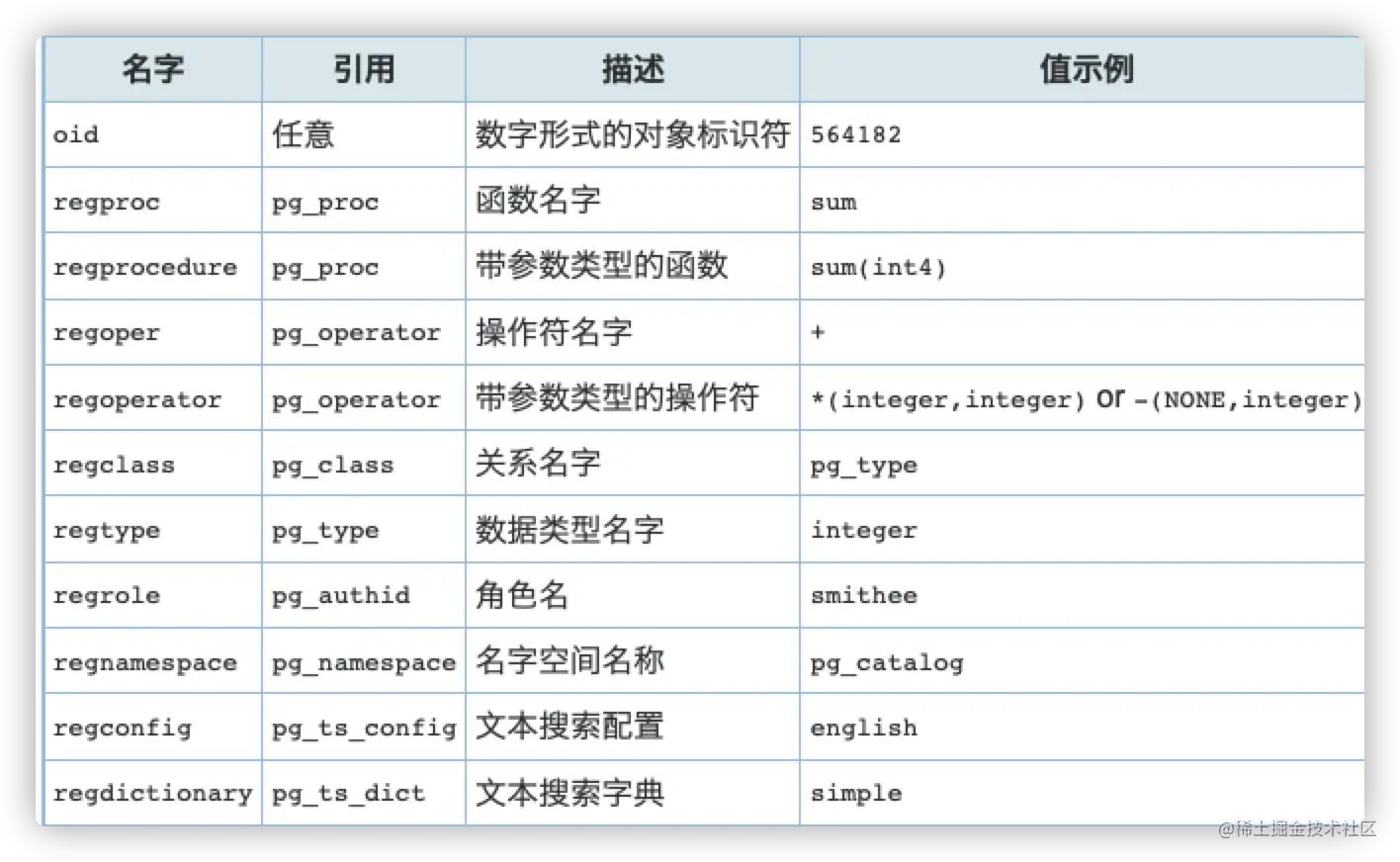
OID的别名类型除了特定的输入和输出例程之外没有别的操作。这些例程可以接受并显示系统对象的符号名,而不是类型oid使用的原始数字值。别名类型使查找对象的OID值变得简单。例如,要检查与一个表course有关的pg_attribute行,你可以写:
SELECT * FROM pg_attribute WHERE attrelid = 'course'::regclass;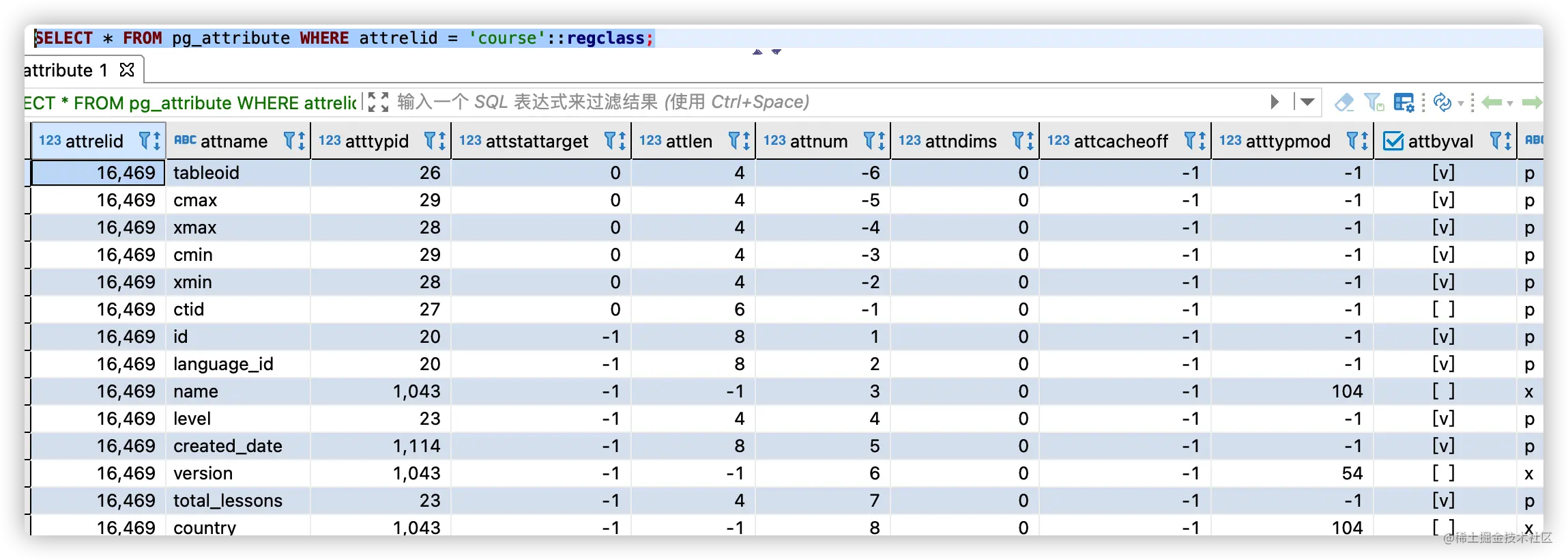
OID 在系统表中通常是作为隐藏列存在的,它是以整个PostgreSQL数据库实例(Database Cluster)的范围内统一分配。因为只有四个字节,因此,在大型数据库中它并不足以提供数据库范围内的唯一性,甚至在一些大型的表中也无法提供表范围内的唯一性。
OID 在旧版本中还可以用于标识元组,对于没有主键,重复的行,此时 OID 作为唯一 ID,则可以根据它进行删除指定行数据。我们之前创建表时,default_with_oids 默认是关闭的。在老版本中执行 create table 语句时可以指定开启 OID。
create table foo (
id integer,
content text
) with oids;不过从 Postgres 12 开始,删除了将 OID 用作表上的可选系统列。将无法再使用:
CREATE TABLE … WITH OIDS 命令default_with_oids (boolean) 相容性设定数据类型OID保留在Postgres 12中。您可以显式创建类型的列OID。
事务ID:
数据库系统中使用的数据类型为 xmin 和 xmax。
简单示例如下:
select id, xmin, xmax from course;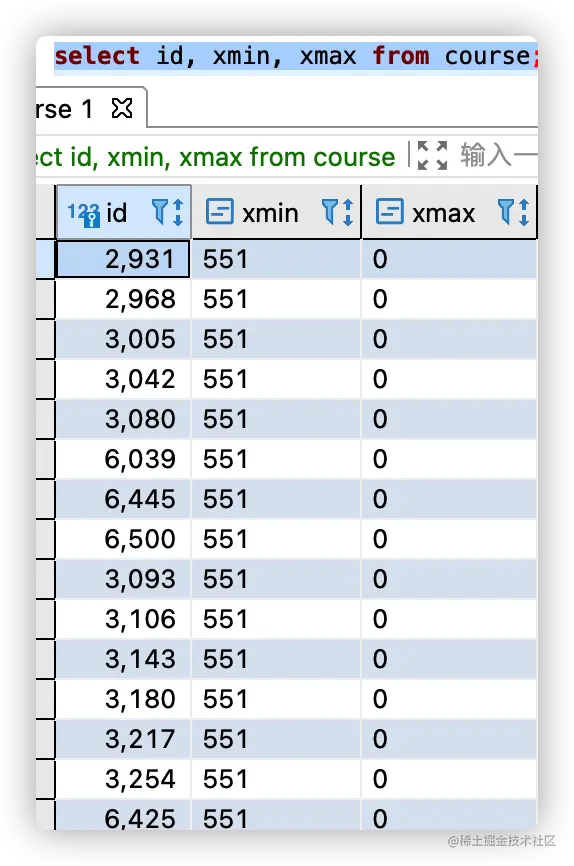
当 PostgreSQL的XID 到达40亿,会造成溢出,从而新的XID 为0。而按照 PostgreSQL的MVCC 机制实现,之前的事务就可以看到这个新事务创建的元组,而新事务不能看到之前事务创建的元组,这违反了事务的可见性。具体参考文档
CID 名为命令标识符,PG 每个表都包含一些系统字段,关于 CID 用到的数据类型为 cmax 和 cmin。
cmin和cmax用于判断同一个事务内的其他命令导致的行版本变更是否可见。如果一个事务内的所有命令严格顺序执行,那么每个命令总能看到之前该事务内的所有变更,不需要使用命令标识。
简单示例如下:
select id, xmin, xmax,cmin,cmax from course;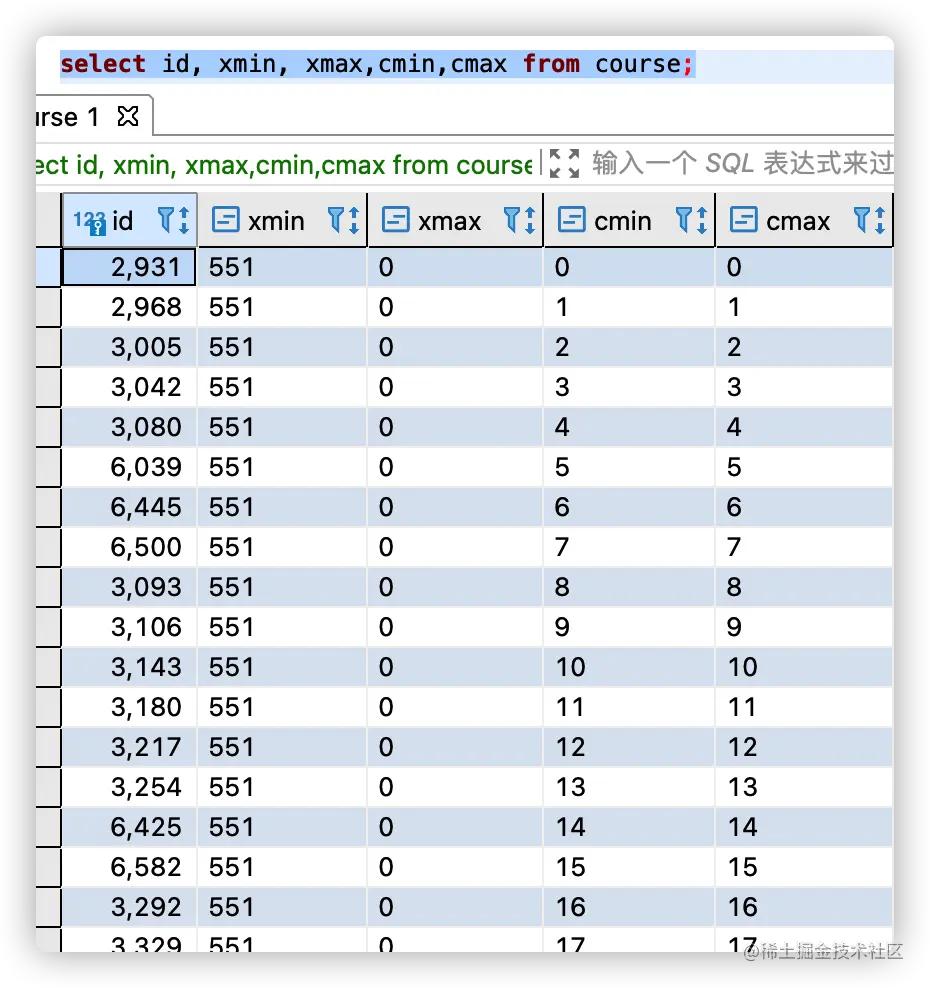
TID 称为元组标识符(行标识符),一个元组ID是一个(块号,块内元组索引)对,它标识了行在它的表中的物理位置。
简单示例如下:
select ctid,id, xmin, xmax,cmin,cmax from course;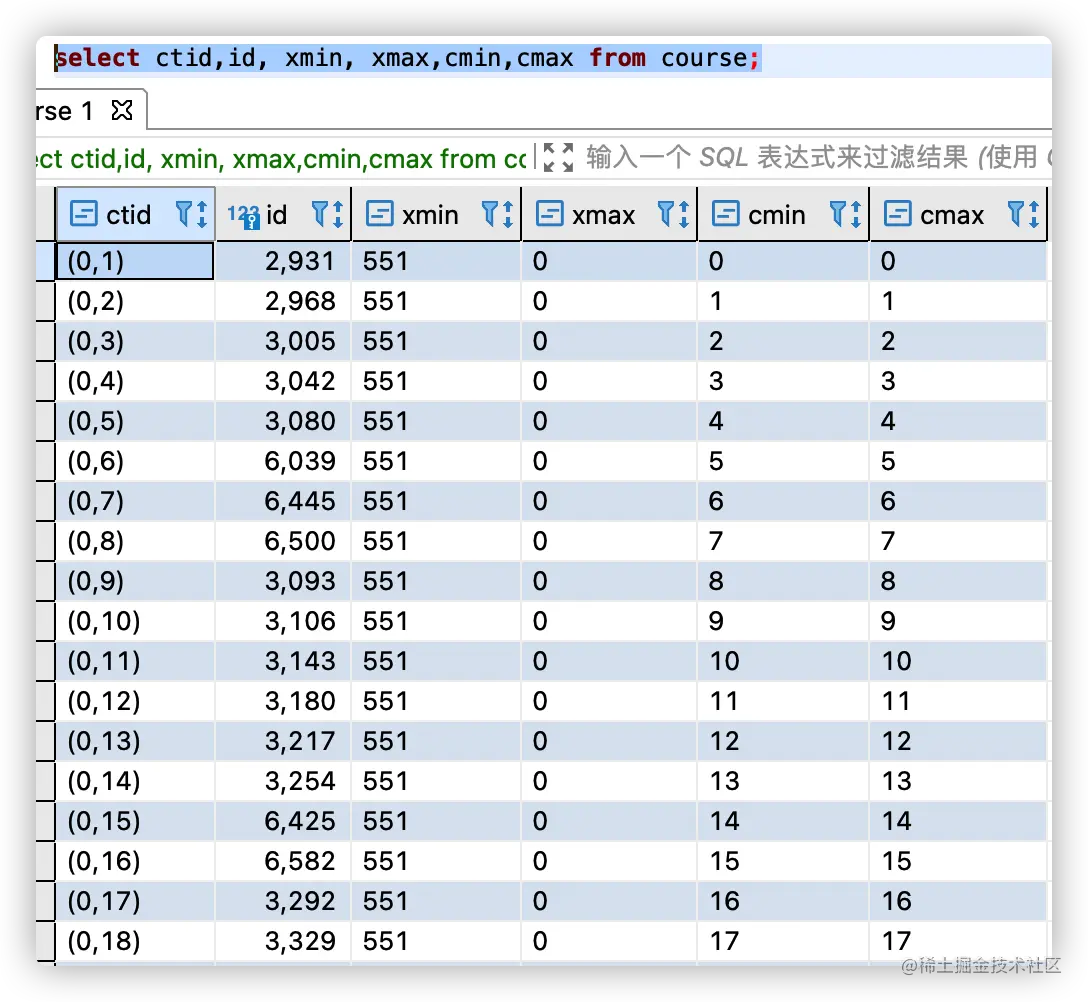
了解完上述四大标识符后,我们接着来学习 PostgreSQL 中数据到底是怎么存储的。
关于数据存储,我们都知道数据是存在数据库中的某个数据表中,每条数据记录对应数据表中的某一行,所以我们从上至下来查看各层次结构的数据存储。
PGDATA 是 PostgreSQL 用来存放所有数据的地方。
关于 PGDATA 的设置,可以先执行下述命令。
postgres=# show data_directory;
data_directory
-----------------------------
/Library/PostgreSQL/12/data
(1 row)接下来我们来看一下 PGDATA 文件夹中有哪些文件,首先打开命令行窗口,然后进入到上述目录。
MacBook-Pro 12 % cd /Library/PostgreSQL/12/data
cd: permission denied: /Library/PostgreSQL/12/data如果遇到上述问题,则执行如下命令,尝试使用 sudo 模拟 postgresql 用户登录:
MacBook-Pro 12 % sudo -u postgres -i
The default interactive shell is now zsh.
To update your account to use zsh, please run `chsh -s /bin/zsh`.
For more details, please visit https://support.apple.com/kb/HT208050.接着执行如下命令:
tree -FL 1 /Library/PostgreSQL/12/data
/Library/PostgreSQL/12/data
├── PG_VERSION
├── base/
├── current_logfiles
├── global/
├── log/
├── pg_commit_ts/
├── pg_dynshmem/
├── pg_hba.conf
├── pg_ident.conf
├── pg_logical/
├── pg_multixact/
├── pg_notify/
├── pg_replslot/
├── pg_serial/
├── pg_snapshots/
├── pg_stat/
├── pg_stat_tmp/
├── pg_subtrans/
├── pg_tblspc/
├── pg_twophase/
├── pg_wal/
├── pg_xact/
├── postgresql.auto.conf
├── postgresql.conf
├── postmaster.opts
└── postmaster.pid介绍几个常见的文件夹:
base/:存储 database 数据(除了指定其他表空间的),子目录的名字为该数据库在 pg_database里的 OID。postgresql.conf:postgresql 配置文件上文提到在 base/ 目录下存放着每个 database 数据,其中文件名我们叫做 dboid。
由于 OID 是系统表的隐藏列,因此查看系统表中数据库对象的OID时,必须在SELECT语句中显式指定。我们进入 postgres 命令行窗口,执行下述命令:
postgres=# select oid,datname from pg_database;
oid | datname
-------+-----------
13635 | postgres
1 | template1
13634 | template0
16395 | mydb
16396 | dvdrental
16399 | testdb
(6 rows)
select oid,relname from pg_class order by oid;我们可以在 PGDATA 文件夹下的 base 目录下看到 oid
MacBook-Pro:base postgres$ ls /Library/PostgreSQL/12/data/base
1 13634 13635 16395 16396 16399从上述内容可知 postgres 数据库相关的数据存储在 PGDATA/base/13635 目录里面。
上文我们定位到数据库的存储位置,接着我们来定位数据表的位置。
每一张表的数据(大部分)又是放在 $PGDATA/base/{dboid}/{relfilenode} 这个文件里面,relfilenode一般情况下和和tboid一致,但有些情况下也会变化,如TRUNCATE、REINDEX、CLUSTER以及某些形式的ALTER TABLE。
CREATE TABLE public.cities (
city varchar(80) NOT NULL,
"location" point NULL,
CONSTRAINT cities_pkey PRIMARY KEY (city)
);
postgres=# select oid,relfilenode from pg_class where relname = 'cities';
oid | relfilenode
-------+-------------
16475 | 16475
(1 row)
insert into cities values('北京',null);
insert into cities values('上海',null);
truncate cities ;
postgres=# select oid,relfilenode from pg_class where relname = 'cities';
oid | relfilenode
-------+-------------
16475 | 16480
(1 row)
SELECT * FROM pg_attribute WHERE attrelid = 'course'::regclass;除了上述 SQL 语句,我们还可以通过系统函数 pg_relation_filepath 来查看指定表的文件存储位置。
postgres=# select pg_relation_filepath('cities');
pg_relation_filepath
----------------------
base/13635/16480
(1 row)当查看 PGDATA/base/13635/ 目录时,会发现 16480 的文件夹,除此之外还会发现有些文件命名为 relfilenode_fsm、relfilenode_vm、relfilenode_init, 关于 16480 通常会有三种文件:16480、16480_fsm、16480_vm,分别是该数据库对应表的数据或索引文件、其对应的空闲空间映射文件、其对应的可见性映射文件。
如果数据文件过大,那么会怎么命名呢?
在表或者索引超过1GB之后,它就被划分成1GB大小的段。 第一个段的文件名和文件节点相同,随后的段被命名为 filenode.1、filenode.2等等。这样的安排避免了在某些有文件大小限制的平台上的问题。
postgres=# create table bigdata(id int,name varchar(64));
postgres=# insert into bigdata select generate_series(1,20000000) as key, md5(random()::text);
postgres=# select pg_relation_filepath('bigdata');
pg_relation_filepath
----------------------
base/13635/16486
(1 row)
#切换命令行界面
MacBook-Pro:base postgres$ ls 13635 |grep 16486
16486
16486.1
16486_fsm 上文我们提到 table 存储时,每个数据文件(堆文件、索引文件)可存储 1G 的容量,每个文件内部又是有若干个固定的页组成。页的默认大小为8192字节(8KB)。单个表文件中的这些页(Page)从0开始进行顺序编号,这些编号也称为“块编号(Block Numbers)”。如果第一页空间已经被数据填满,则 postgres 会立刻重新在文件末尾(即已填满页的后面)添加一个新的空白页,用于继续存储数据,一直持续这个过程,直到当前表文件大小达到 1GB位置。若文件达到1GB,则重新创建一个新的表文件,然后重复上面的这个过程。
每个页的内部又由一个页文件头(Page Header)、若干行指针(Line Pointer)、若干个元组数据(Heaple Tuple)组成。因为每个文件默认大小为 1GB,页大小为 8kb,则每个文件大概有 131072 个页。
首先来看一下页面结构。
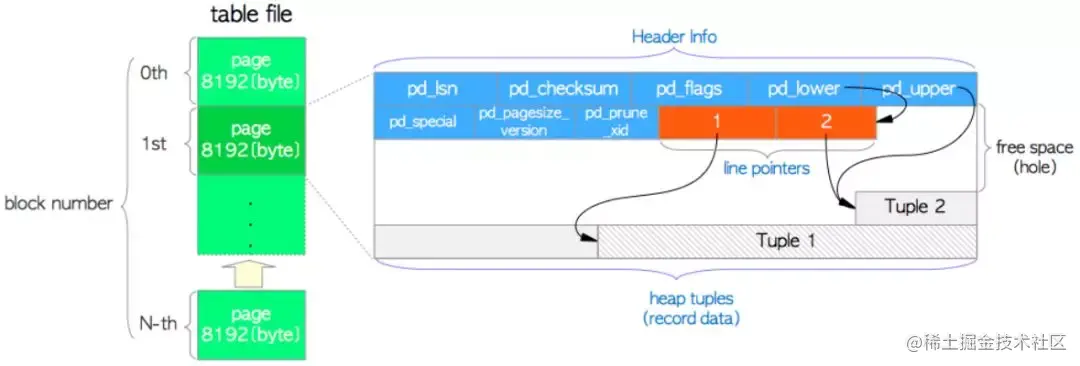
其中:
page header: 24 字节,存储 page 的基本信息,包括 pd_lsn、pd_checksum、pd_special...
pd_lsn: 存储最近改变该页面的xlog。 pd_checksum:存储页面校验和。 pd_lower,pd_upper:pd_lower指向行指针(line pointer)的尾部,pd_upper指向最后那个元组。 pd_special: 索引页面中使用,它指向特殊空间的开头。 pd_flags:用以设置位标志。 pd_pagesize_version:页面大小及页面版本号。 pd_prune_xid:可删除的旧 XID,如果没有则为零。 复制代码
line pointe:行指针,4 bytes,形为 (offset, length) 的二元组,指向相关 tuple
heap tuple: 用来存储 row 的数据,注意元组是从页面的尾部向前堆积的,元组和行指针之间的是数据页的空闲空间。
因此我们找 row 的数据需要知道哪一个 page,page 的哪一个 item, (page_index, item_index), 通常称它为 CTID(ItemPointer), 我们可以通过下面语句查看每一列的 CTID:
select ctid,* from course;查询结果如下所示:
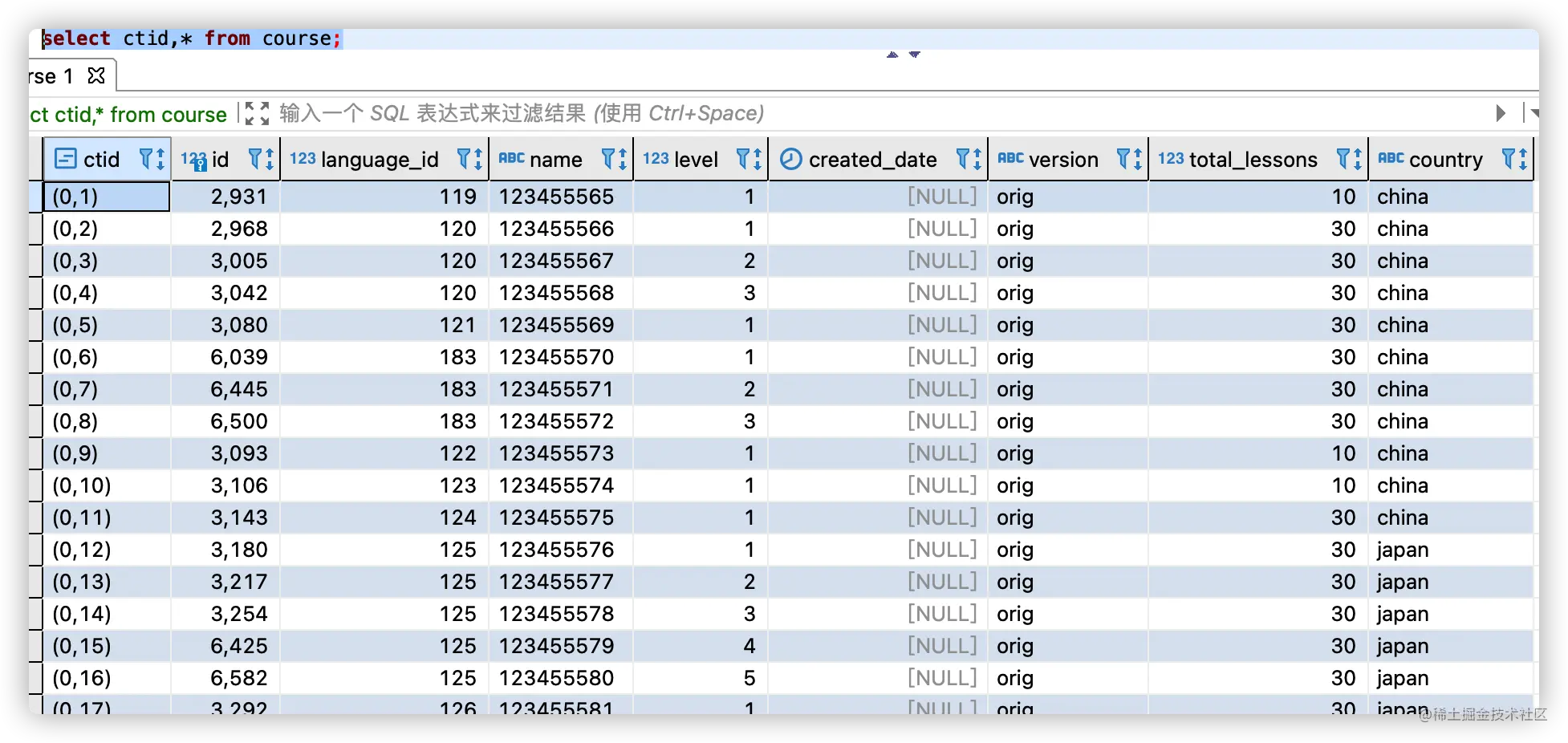
关于元组结构以及数据变化的详解讲解,可以参考本文。
PostgreSQL 除了默认的 public schema 之外,还有两个比较重的系统 schema:information_schema 与pg_catalog。
通过查看 pg_catalog.pg_namespace 来查看当前数据库中全部的 schema。
postgres=# select * from pg_catalog.pg_namespace ;
oid | nspname | nspowner | nspacl
-------+--------------------+----------+-------------------------------------
99 | pg_toast | 10 |
12314 | pg_temp_1 | 10 |
12315 | pg_toast_temp_1 | 10 |
11 | pg_catalog | 10 | {postgres=UC/postgres,=U/postgres}
2200 | public | 10 | {postgres=UC/postgres,=UC/postgres}
13335 | information_schema | 10 | {postgres=UC/postgres,=U/postgres}
(6 rows)我们创建的表、视图、索引等默认都在 public 下。
information_schema 是方便用户查看表/视图/函数信息提供的,它大多是视图。
select * from information_schema."tables";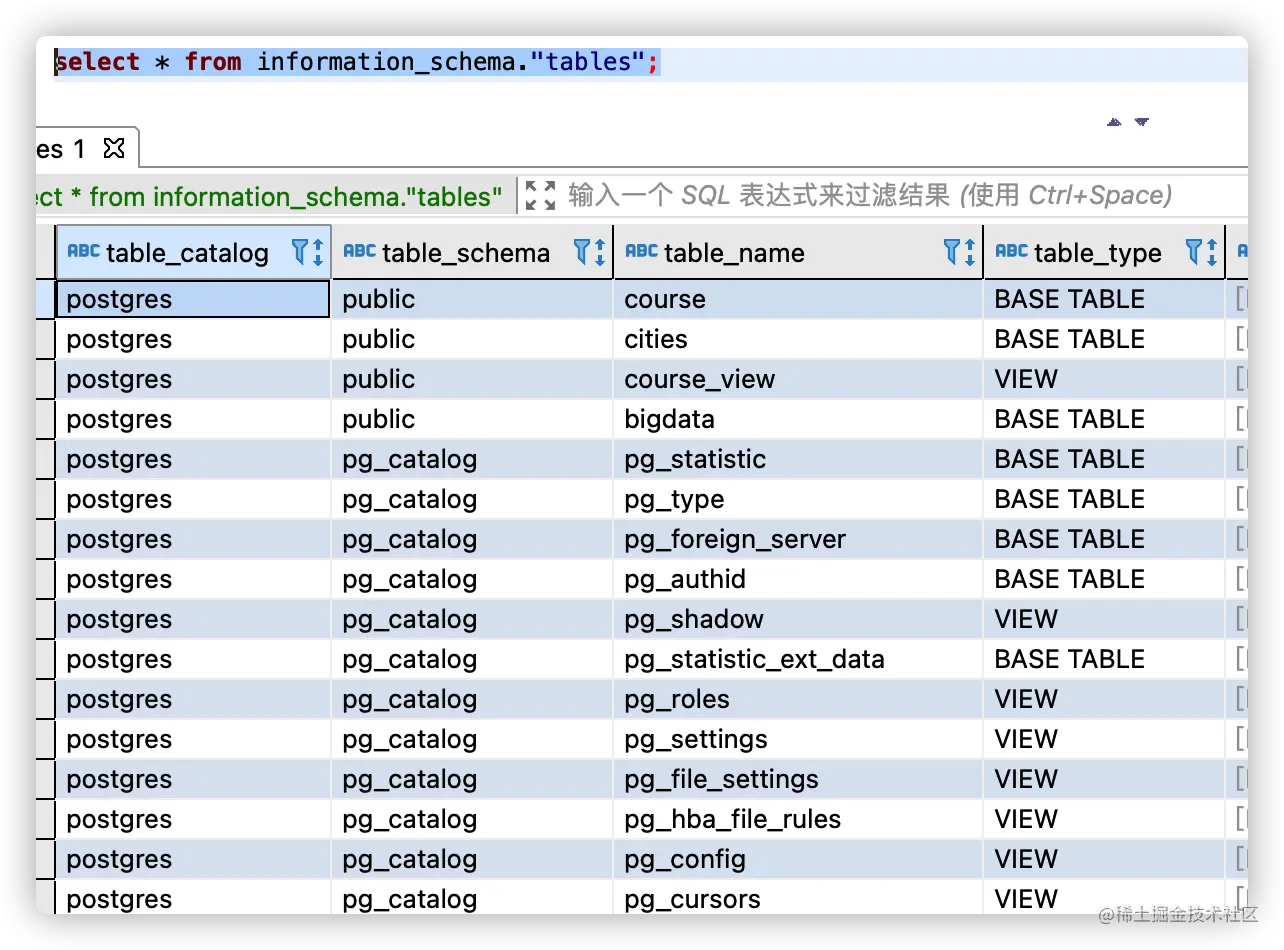
pg_catalog 包含系统表和所有内置数据类型、函数、操作符。pg_catalog 下有很多系统表,比如说 pg_class、pg_attribute、pg_authid等。
