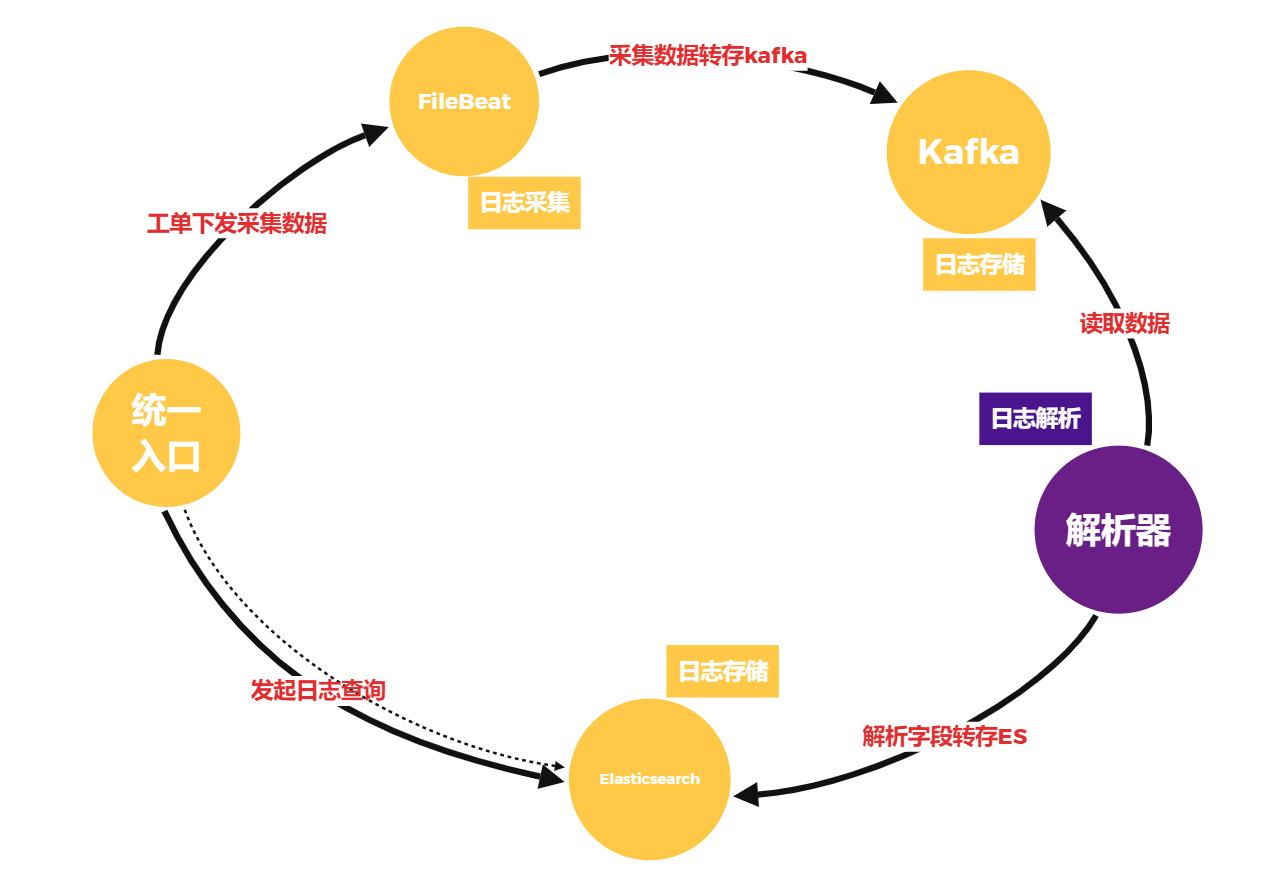
公司日志系统目前日均处理数据10T左右,查询经常出现数据延迟问题且延迟经常在4-5个小时以上,但是服务器的1分钟load值经常不高于5,鉴于解析端的配置为16C_32G的配置,该现象并没有充分的利用CPU资源,单纯的扩容解析器资源虽然能解决问题,但是并没有从根本解决,优化数据流程架构图去除不必要项,并分析解析器性能瓶颈问题到底出现在哪里?
1、开启火焰图分析CPU、内存使用情况:
CPU:
获取CPU 30s内资源耗时使用情况

内存:
获取解析器当前内存使用情况,从kafka获取1346.07MB有效数据,经解析丢弃无效数据剩余1.19G ,但是发送ES却只有377.18MB,剩余数据写入了内存中,显然从kafka获取数据的速度远远大于写入ES的速度。
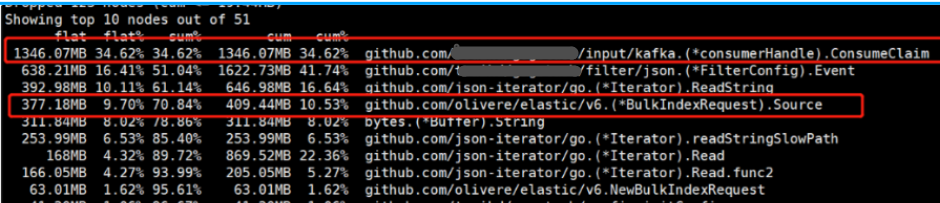
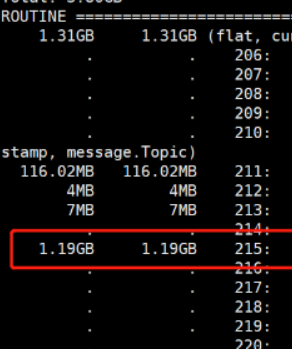
由于解析器的本身机制:从kafka获取数据,然后写入Elasticsearch,当服务器内存经常出现报警,此时判断数据出现了积压,Elasticsearch批量提交数据出现了瓶颈,但是该瓶颈可能出现在两方面:
第一、解析器代码的问题 第二、Elasticsearch服务端出现了瓶颈
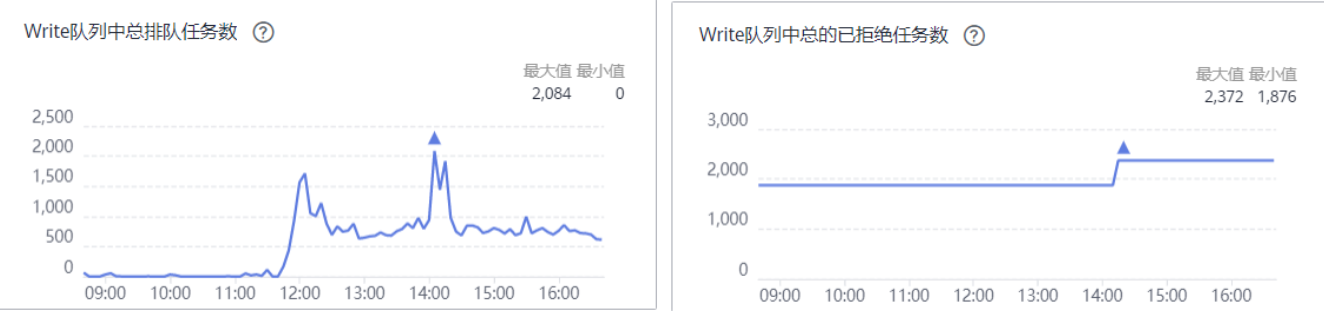
下图是Elasticsearch服务端监控图,由此图可看出中午业务日志量猛增时,写入数据队列开始出现了排队现象:
查询Elasticsearch文档以及论坛建议,可从以下方面着手优化:
服务端:
1、index.translog.durability :async 事务日志和内存缓冲区,调整为异步落盘,一次落盘数据大于512MB,可根据集群规模内存大小适当调整1024MB
2、index.refresh_interval: 增加Elasticsearch执行刷新操作,默认1S,建议对数据不敏感业务调整30s
3、使用负载均衡代理9200端口: 可以减少服务端TCP开销,并且可以避免异常情况下数据重复问题。 如果使用多个节点链接,当ES单个服务端出现响应超时的时候,bulk方法就会重新找下一个节点发送写请求。而ES本身是用写队列的方式落库数据,虽然响应慢,但是实际的写请求已经进入ES,导致数据重复
4、禁用Replicas, 单副本可以提高批量索引速度,关闭服务器swap,选择高性能磁盘
5、自动生成文档ID,让数据能够快速路由到节点
6、设置合理的分片数量number_of_shards,可以把数据存储到更多节点上,支持集群扩容和更好处理并发请求
客户端:
1、使用批量index,Bulk action 单次index大于1000,可根据服务端适量调整5000
2、增加bulk worker扩大批量index线程池,与服务端建立更多的TCP连接传输数据,Elasticsearch 6版本服务端默认200,可适当调整1024,客户端可根据实际情况增加
3、增加bulk size 单次index数据大小5-15MB,可根据服务内存使用情况调整,建议不超过15M
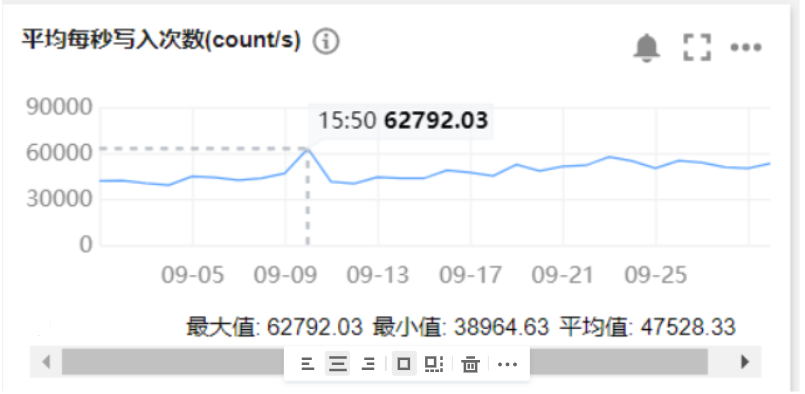
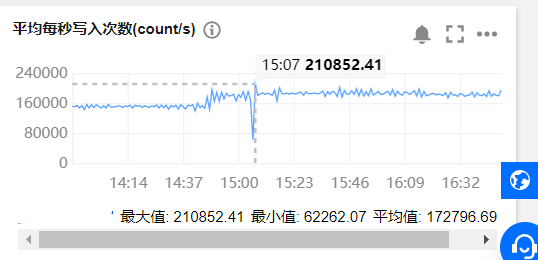
优化后性能对比
1、服务端Elasticsearch:站长素材网集群瞬时写入可达21W/s,相比之前性能已提升3倍
优化前:
优化后:
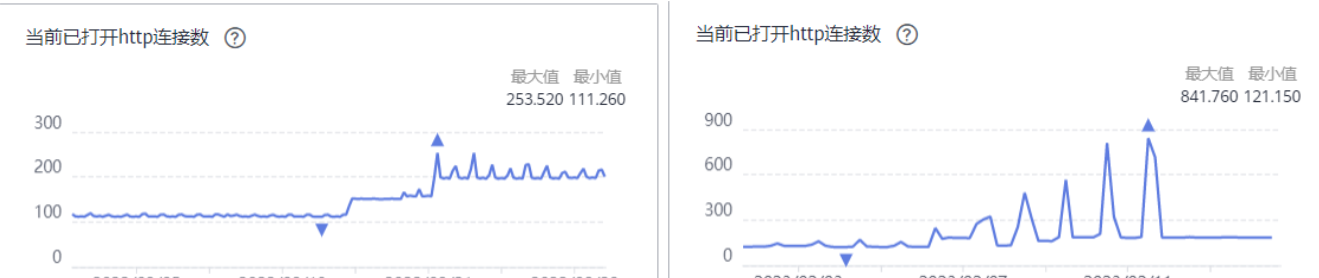
2、扩大bulk线程池带来更多的连接,相比之前增加3倍,以应对数据高峰期批量写入:
3、16C_32G的配置将服务器性能最大化的利用:
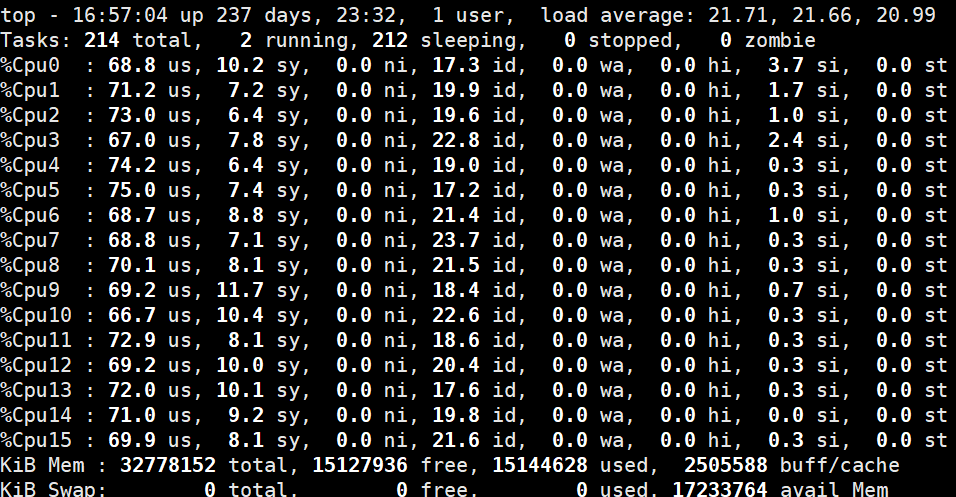
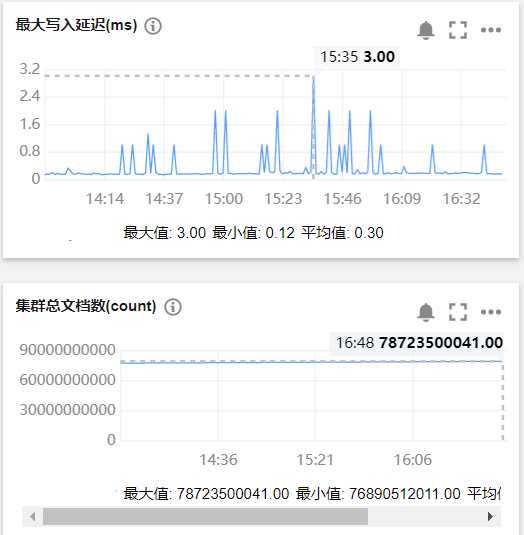
4、Elasticsearch写入延迟和文档数量