

这一章我们介绍在下游任务微调中固定LM参数,只微调Prompt的相关模型。这类模型的优势很直观就是微调的参数量小,能大幅降低LLM的微调参数量,是轻量级的微调替代品。和前两章微调LM和全部冻结的prompt模板相比,微调Prompt范式最大的区别就是prompt模板都是连续型(Embedding),而非和Token对应的离散型模板。核心在于我们并不关心prompt本身是否是自然语言,只关心prompt作为探针能否引导出预训练模型在下游任务上的特定能力。
固定LM微调Prompt的范式有以下几个优点
Paper: 2021.1 Optimizing Continuous Prompts for Generation Github:https://github.com/XiangLi1999/PrefixTuning Prompt: Continus Prefix Prompt Task & Model:BART(Summarization), GPT2(Table2Text)
最早提出Prompt微调的论文之一,其实是可控文本生成领域的延伸,因此只针对摘要和Table2Text这两个生成任务进行了评估。
先唠两句可控文本生成,哈哈其实整个Prompt范式也是通用的可控文本生成不是,只不过把传统的Topic控制,文本情绪控制,Data2Text等,更进一步泛化到了不同NLP任务的生成控制~~
Prefix-Tuning可以理解是CTRL 1 模型的连续化升级版,为了生成不同领域和话题的文本,CTRL是在预训练阶段在输入文本前加入了control code,例如好评前面加'Reviews Rating:5.0',差评前面加'Reviews Rating:1.0', 政治评论前面加‘Politics Title:’,把语言模型的生成概率,优化成了基于文本主题的条件概率。
Prefix-Tuning进一步把control code优化成了虚拟Token,每个NLP任务对应多个虚拟Token的Embedding(prefix),对于Decoder-Only的GPT,prefix只加在句首,对于Encoder-Decoder的BART,不同的prefix同时加在编码器和解码器的开头。在下游微调时,LM的参数被冻结,只有prefix部分的参数进行更新。不过这里的prefix参数不只包括embedding层而是虚拟token位置对应的每一层的activation都进行更新。

对于连续Prompt的设定,论文还讨论了几个细节如下
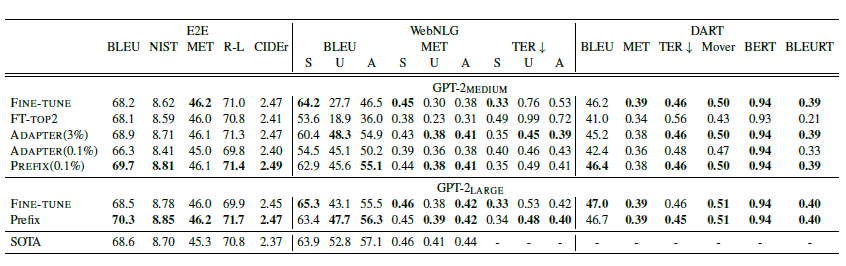 摘要任务上,prompt的效果要略差于微调。
摘要任务上,prompt的效果要略差于微调。
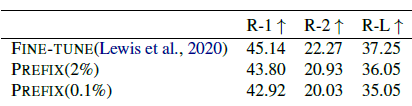
Paper: 2021.4 The Power of Scale for Parameter-Efficient Prompt Tuning prompt:Continus Prefix Prompt Github: https://github.com/google-research/prompt-tuning Task: SuperGLUE NLU任务 Model: T5 1.1(在原T5上进行了细节优化)

Prompt-tuning是以上prefix-tuning的简化版本,面向NLU任务,进行了更全面的效果对比,并且在大模型上成功打平了LM微调的效果~
对比Prefix-tuning,prompt-tuning的主要差异如下,
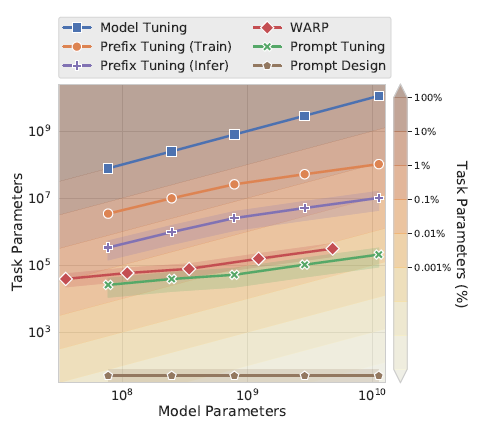
论文使用100个prefix token作为默认参数,大于以上prefix-tuning默认的10个token,不过差异在于prompt-tuning只对输入层(Embedding)进行微调,而Prefix是对虚拟Token对应的上游layer全部进行微调。因此Prompt-tuning的微调参数量级要更小,且不需要修改原始模型结构,这是“简化”的来源。相同的prefix长度,Prompt-tuning(<0.01%)微调的参数量级要比Prefix-tuning(0.1%~1%)小10倍以上,如下图所示
为什么上面prefix-tuning只微调embedding层效果就不好,放在prompt-tuning这里效果就好了呢?因为评估的任务不同无法直接对比,个人感觉有两个因素,一个是模型规模,另一个是继续预训练,前者的可能更大些,在下面的消融实验中会提到
下图,在SuperGLUE任务上,随着模型参数的上升,Promp-tuning快速拉近和模型微调的效果,110亿的T5模型(上面prefix-tuning使用的是15亿的GPT2),已经可以打平在下游多任务联合微调的LM模型,并且远远的甩开了Prompt Design(GPT3 few-shot)
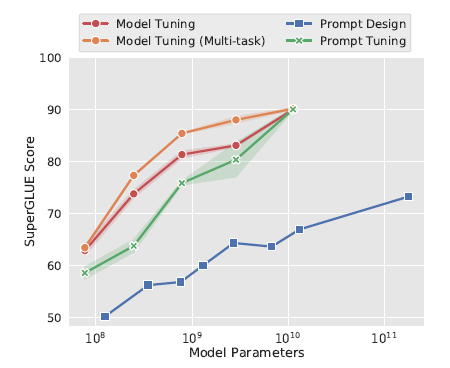
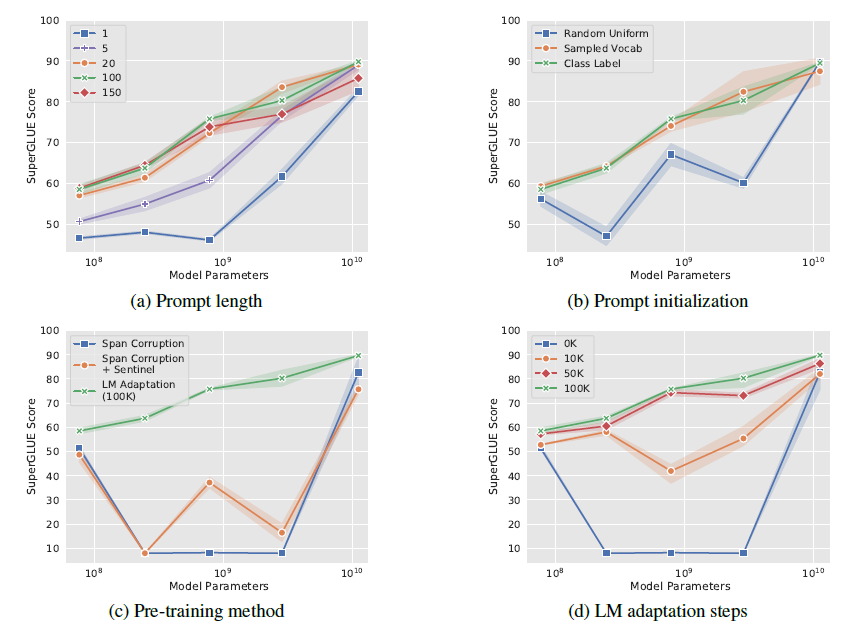
作者也做了全面的消融实验,包括以下4个方面,最核心的感受就是只要模型足够够大一切都好说
考虑Prompt-tuning使用Embedding来表征指令,可解释性较差。作者使用cosine距离来搜索prompt embedding对应的Top5近邻。发现
Paper: 2021.3, GPT Understands, Too prompt:Continus Prefix Prompt Task: NLU任务, 知识探测任务 github: https://github.com/THUDM/P-tuning Model: GPT2 & BERT
P-Tuning和Prompt-Tuning几乎是同时出现,思路也是无比相似。不过这个在prompt综述中被归类为LM+Prompt同时微调的范式,不过作者其实两种都用了。因此还是选择把p-tuning也放到这一章,毕竟个人认为LM+Prompt的微调范式属实有一点不是太必要。。。
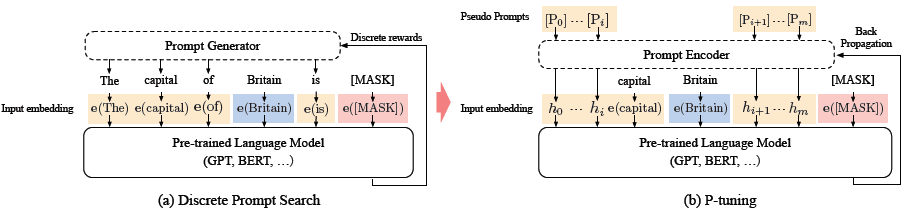
论文同样是连续prompt的设计。不过针对上面提到的Prompt的整体性问题进行了优化。作者认为直接通过虚拟token引入prompt存在两个问题
针对这两个问题,作者使用双向LSTM+2层MLP来对prompt进行表征, 这样LSTM的结构提高prompt的整体性,Relu激活函数的MLP提高离散型。这样更新prompt就是对应更新整个lstm+MLP部分的Prompt Encoder。下面是p-tuning和离散prompt的对比
作者分别对LAMA知识探测和SuperGLUE文本理解进行了评测。针对知识抽取,作者构建的prompt模板如下,以下3是虚拟prompt词的数量,对应prompt encoder输出的embedding数
在知识探测任务中,默认是固定LM只微调prompt。效果上P-tuning对GPT这类单项语言模型的效果提升显著,显著优于人工构建模板和直接微调,使得GPT在不擅长的知识抽取任务中可以基本打平BERT的效果。
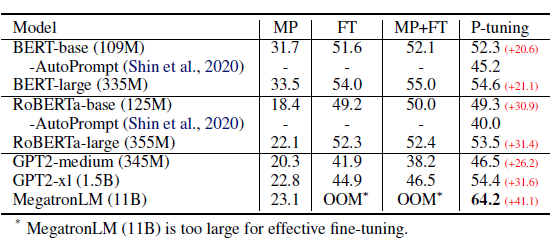
针对SuperGLUE作者是做了LM+Prompt同时微调的设定。个人对LM+prompt微调的逻辑不是认同,毕竟1+1<2,同时微调它既破坏了预训练的语言知识,也没节省微调的参数量级,感觉逻辑上不是非常讲的通(哈哈坐等之后被打脸)。结论基本和以上知识探测相似
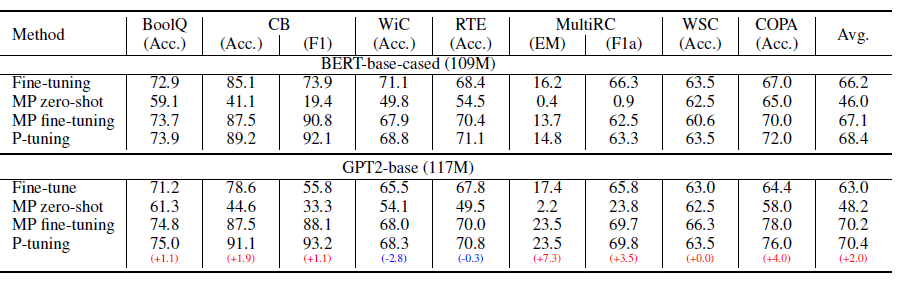
开头说优点,结尾说下局限性
更多Prompt相关论文,AIGC相关玩法戳这里DecryptPrompt
