

Hello folks,我是 Luga,今天我们来分享一下与 Kafka 有关的观测性话题- Kafdrop。作为一个构建在 Spring Boot 之上的免费 Web UI工具,越来越受到广大技术人员的喜好。
— 01 —
Kafdrop 是一个 Apache 2.0 许可项目,作为一款 Apache Kafka Web UI 可视化工具,在无数的开源选项中,Kafdrop 以其简单、快速和易于使用而脱颖而出。同时,它是一个开源 Web 项目,允许查看来自 Kafka 代理的信息,如现有主题、消费者,甚至是发送的消息内容。
那么,Kafdrop到底有什么可圈可点的优势呢?接下来,我们来简要看一下 Kafdrop 的核心功能,具体如下所示:
1、查看 Kafka 代理 -主题和分区分配以及控制器状态
2、查看主题 -分区数,复制状态和自定义配置
3、浏览消息 -JSON,纯文本和 Avro 编码
4、查看消费者组 -每个分区的停放偏移量,合并延迟和每个分区滞后
5、创建新主题
6、查看 ACL 等
— 02 —
通常情况下,若基于 Docker 容器引擎运行 Kafdrop 组件,我们可采用如下 2 种方式启动。
1、后台直接运行
[leonli@Leon ~ ] % docker run -d --rm -p 19000:9000 \
-e KAFKA_BROKERCONNECT=<host:port,host:port> \
-e JVM_OPTS="-Xms32M -Xmx64M" \
-e SERVER_SERVLET_CONTEXTPATH="/" \
obsidiandynamics/kafdrop2、基于 Protobuff 定义在后台运行
[leonli@Leon ~ ] % docker run -d --rm -v <path_to_protobuff_descriptor_files>:/var/protobuf_desc -p 19000:9000 \
-e KAFKA_BROKERCONNECT=<host:port,host:port> \
-e JVM_OPTS="-Xms32M -Xmx64M" \
-e SERVER_SERVLET_CONTEXTPATH="/" \
-e CMD_ARGS="--message.format=PROTOBUF --protobufdesc.directory=/var/protobuf_desc" \
obsidiandynamics/kafdrop针对上述的 2 种不同参数方式运行后,我们可以通过 http://localhost:19000 访问 Web UI。
— 03 —
这里,我们分别基于 Helm 以及 Kubernetes Manifest file 进行部署安装,具体可参考如下。
基于 Helm 部署
1、获取代码仓库
[leonli@Leon ~ ] % git clone https://github.com/obsidiandynamics/kafdrop && cd kafdrop
Cloning into 'kafdrop'...
remote: Enumerating objects: 4502, done.
remote: Counting objects: 100% (35/35), done.
remote: Compressing objects: 100% (33/33), done.
Receiving objects: 4% (181/4502), 36.00 KiB | 4.00 KiB/s
...2、执行安装
[leonli@Leon kafdrop ] % helm upgrade -i kafdrop chart --set image.tag=3.x.x \
--set kafka.brokerConnect=<host:port,host:port> \
--set server.servlet.contextPath="/" \
--set cmdArgs="--message.format=AVRO --schemaregistry.connect=http://localhost:8080" \ #optional
--set jvm.opts="-Xms32M -Xmx64M" 基于 Manifest file 部署
1、编写 kafdrop-deployment.yaml
[leonli@Leon ~ ] % vi kafdrop-deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-kafdrop-deployment
namespace: "kafdrop"
labels:
app: kafka-kafdrop
spec:
replicas: 1
selector:
matchLabels:
app: kafka-kafdrop
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
labels:
app: kafka-kafdrop
spec:
volumes:
- name: tz-config
hostPath:
path: /usr/share/zoneinfo/Asia/Kolkata
containers:
- image: obsidiandynamics/kafdrop
imagePullPolicy: Always
name: kafka-kafdrop
volumeMounts:
- name: tz-config
mountPath: /etc/localtime
resources:
limits:
cpu: 200m
memory: 1Gi
requests:
cpu: 200m
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
ports:
- containerPort: 5010
name: server
- containerPort: 5012
name: jmx
env:
- name: JVM_OPTS
value: "-Xms512M -Xms512M"
- name: SERVER_SERVLET_CONTEXTPATH
value: "/"
- name: KAFKA_BROKERCONNECT
value: "<kafka_broker_ip>:9092"
restartPolicy: Always
2、进行创建及部署
[leonli@Leon ~ ] % kubectl apply -f kafdrop-deployment.yaml通常情况下,主题的创建和删除默认是通过 KafDrop 启用的。因此,如果要禁用主题创建和删除功能,那么,我们需要在 YAML 文件的 env 部分添加以下内容,具体如下所示:
- name: CMD_ARGS
value: "--topic.deleteEnabled=false --topic.createEnabled=false"若要从本地计算机的浏览器访问 Kafdrop UI,我们需要创建一个 Kubernetes 服务,该服务将指向在上一步中创建的 Deployment。在其中创建 kafdrop-service.yaml并添加以下参数:
---
apiVersion: v1
kind: Service
metadata:
name: kafka-kafdrop-service
namespace: "kafdrop"
labels:
app: kafka-kafdrop
annotations:
cloud.google.com/load-balancer-type: "Internal"
spec:
ports:
- protocol: "TCP"
port: 9000
name: server
selector:
app: kafka-kafdrop
type: LoadBalancer然后进行如下操作,具体可参考:
[leonli@Leon ~ ] % kubectl apply -f kafdrop-service.yaml等待服务启动后,我们可以从浏览器访问 Kafdrop UI ,至此,基于 Kubernetes 的 2种部署方式解析完成,接下来将是工具的操作使用。
— 04 —
在完成上述的部署操作后,我们通过访问 http://localhost:19000 进入 Kafdrop GUI 窗体,具体可参考:
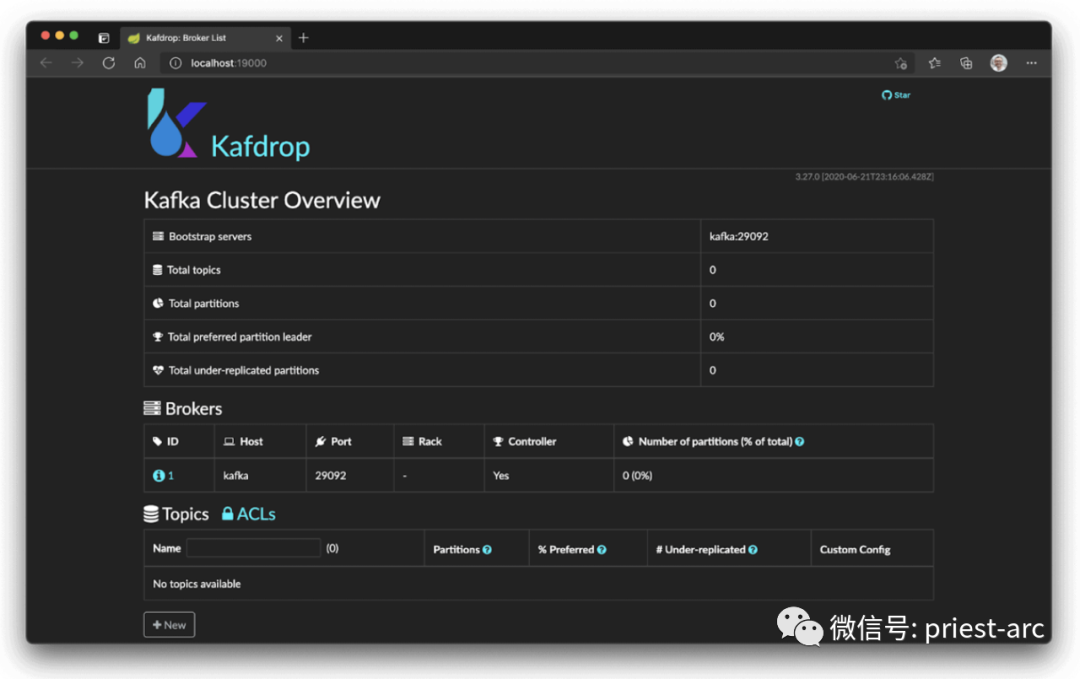
此页面显示了整个 Kafka 集群所有相关的信息,例如,Topic(主题)总数、Topic(主题)名称、Partitions(分区)、Broker(代理)详细信息等详细信息等。同时,随着集群规模和主题(以及分区)数量的增长,我们通常希望看到集群中的分区大致呈水平分布,以评估当前集群的性能情况,为后续资源配置进行优化。
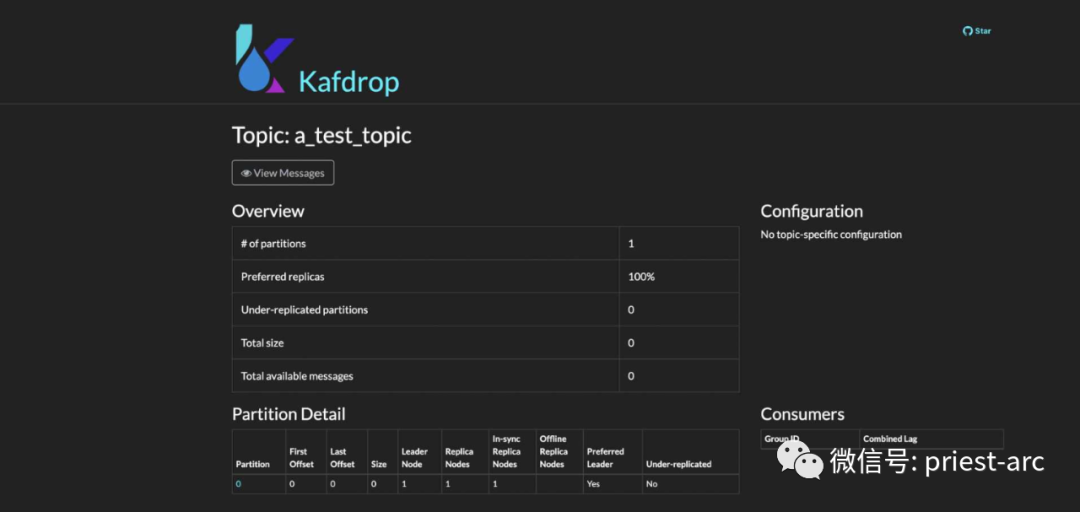
此时,我们点击要查看其详细信息的任何 Kafka 主题,它将打开一个页面,其中包含分区计数、复制因子、偏移延迟、复制不足的分区等详细信息,如下图所示:
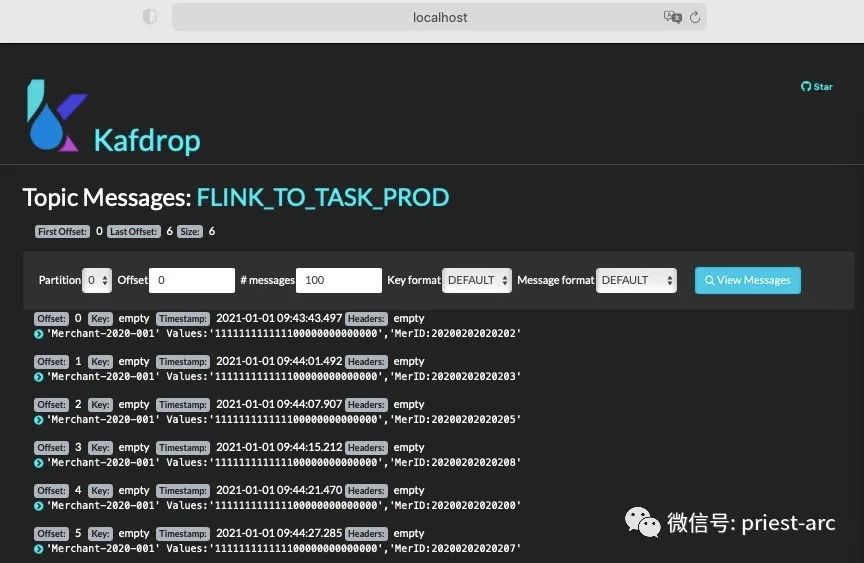
这里,我们模拟生产者生产消息,然后去平台对应的 Topic 查看所生产的消息以及消息的相关内容情况,具体如下所示:
bash-4.4# ./kafka-console-producer.sh --broker-list localhost:9092 --topic FLINK_TO_TASK_PROD
>'Merchant-2020-001' Values:'111111111111100000000000000','MerID:20200202020202'
>'Merchant-2020-001' Values:'111111111111100000000000000','MerID:20200202020203'
>'Merchant-2020-001' Values:'111111111111100000000000000','MerID:20200202020205'
>'Merchant-2020-001' Values:'111111111111100000000000000','MerID:20200202020208'
>'Merchant-2020-001' Values:'111111111111100000000000000','MerID:20200202020200'
>'Merchant-2020-001' Values:'111111111111100000000000000','MerID:20200202020207'
>
此时,我们进入“消息”窗口,这正是我们所期望的——所选分区按时间顺序排列的消息列表。
每个消息列表都方便地显示偏移量、记录键(如果设置了)、发布时间戳以及生产者可能附加的任何标头。
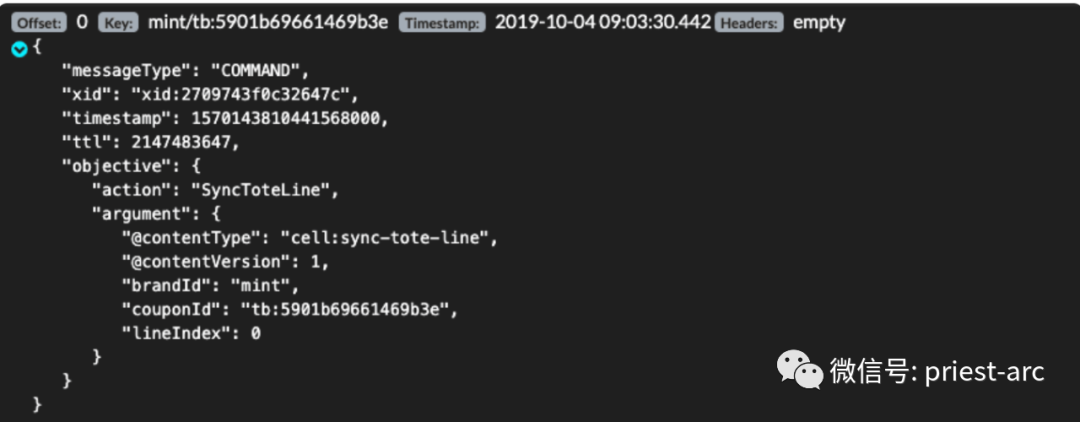
除此之外,若消息恰好是有效的 JSON 文档格式,主题查看器可以很好地格式化它。我们可以单击消息左侧的绿色箭头将其展开进行查看,具体如下所示:
综上所述,Kafdrop 是一款挺出色的工具,允许我们依据实际的业务场景能够查看主题内容、浏览消费者组、查看消费者滞后、主题配置、代理统计信息以及其他相关事件。总而言之,基于其它在填补 Kafka 可观察性工具中的明显空白方面做得非常出色,解决了社区长期以来一直病诟的问题。
Adiós !
··································
Hello folks,我是 Luga,一个 10 年+ 技术老司机,从 IT 屌丝折腾到码畜,最后到“酱油“架构师。如果你喜欢技术,不喜欢呻吟,那么恭喜你,来对地方了,关注我,共同学习、进步、超越~
您的每一个点赞、在看及分享,我都认真当成了喜欢 ~
