游戏圈,是手Q游戏中心在社交化场景的一个探索和实践,将用户在游戏内的战绩、高光等事件作为动态展示在好友的 feeds 流列表中,产品形态上类似微信朋友圈、QQ 空间、推特等。
整体交互上就是用户产生游戏高光(发动态),好友进入动态 feeds 列表按照时间线查看。
先分享下我们业务的一些数据:feeds 发表峰值(写)大约是在 x k/s 左右,日发表量约在 xkw,活跃用户大约 x 亿,单条 feeds 约 900B,每个用户存最近 x 条,大约需要 5T 存储;好友 feeds 流时间线拉取(读)峰值大约在 xk/s。
社交 feeds 型的产品,绕不开的挑战是:
业界几款明星产品的选型:
QQ 空间 | 读扩散 |
|---|---|
微信朋友圈 | 写扩散 |
新浪微博 | 读写扩散 |
写扩散 | |
读扩散 |
读扩散:只有发件箱。优点是写简单、省存储、feeds 策略更灵活(例如支持多种关系链);缺点是读逻辑实现复杂且存储读扩散压力大。
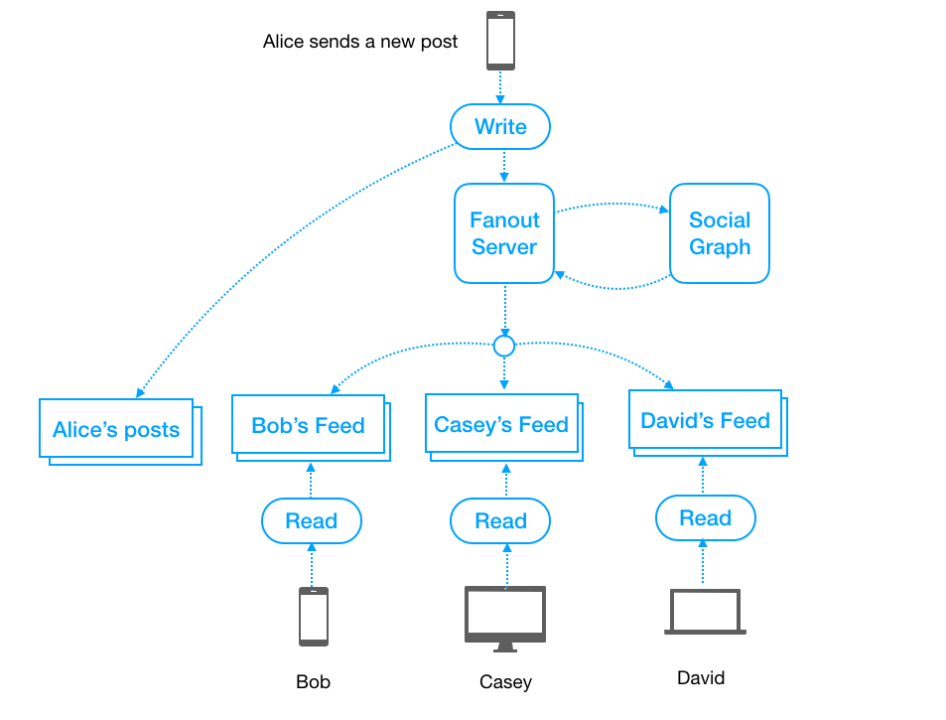
写扩散:有发件箱和收件箱。优点是读简单,缺点是费存储、写复杂(合并写)、大V关系链下扩散慢,延迟高。
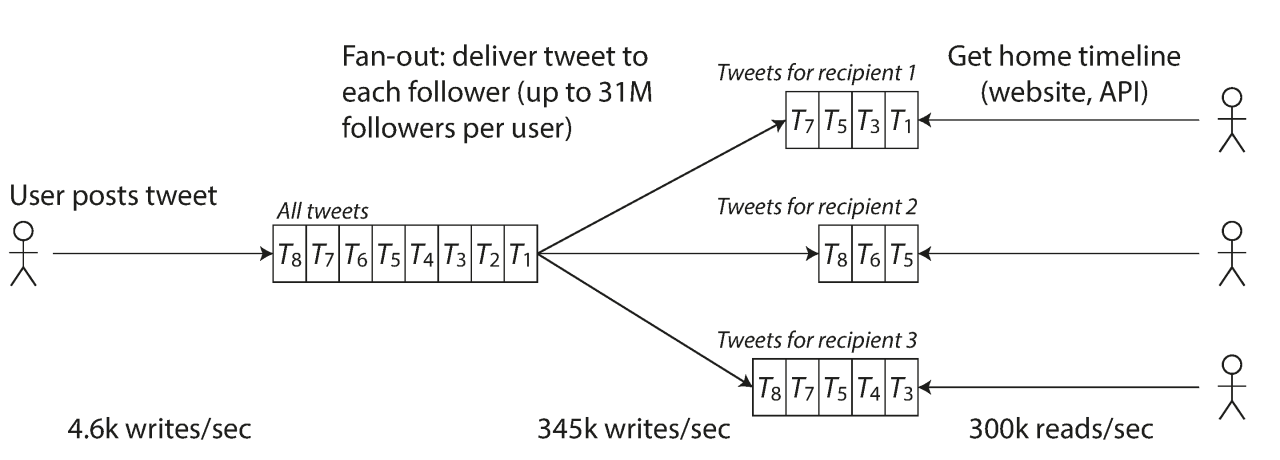
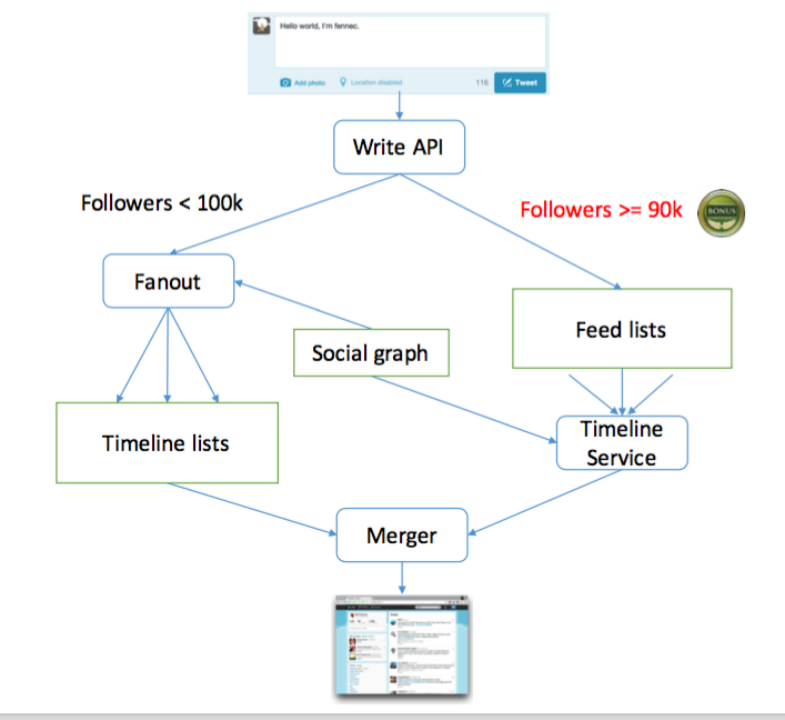
读写扩散:本质还是写扩散。大V用读扩散加速拉取。
架构选择上没有银弹,具体选型还是要结合业务的场景选择。以我们业务为例,选择读扩散,主要考虑:
存储诉求:1是要支持海量存储,10T级别,最好是分布式的,可动态扩容;2是要支持高并发的访问,业务侧估算,4k/s 的 feeds 流拉取,平均每个活跃用户有 160+ 好友,对存储层压力在 64w/s 左右;3是要上云。
结合如上诉求,可选的就这2个:Mongo 分片集群、Tendis/keewidb。
Mongo 的特点是:
Tendis/Keewidb 简而言之就是支持大容量的降冷版的 redis,特点如下:
综上来说,我们选择了 mongo 集群作为存储方案,单用户单条 feeds 为一条记录。

用户进入动态页,按照时间顺序展示好友的 feeds 列表。采用读扩散的方案,先拉取好友列表,再拉取好友的 feeds 记录统一排序返回页面,每页展示10条动态。
参考QQ空间的实现方案,为了减轻读扩散对存储层的压力,游戏圈主要采用如下两种策略:
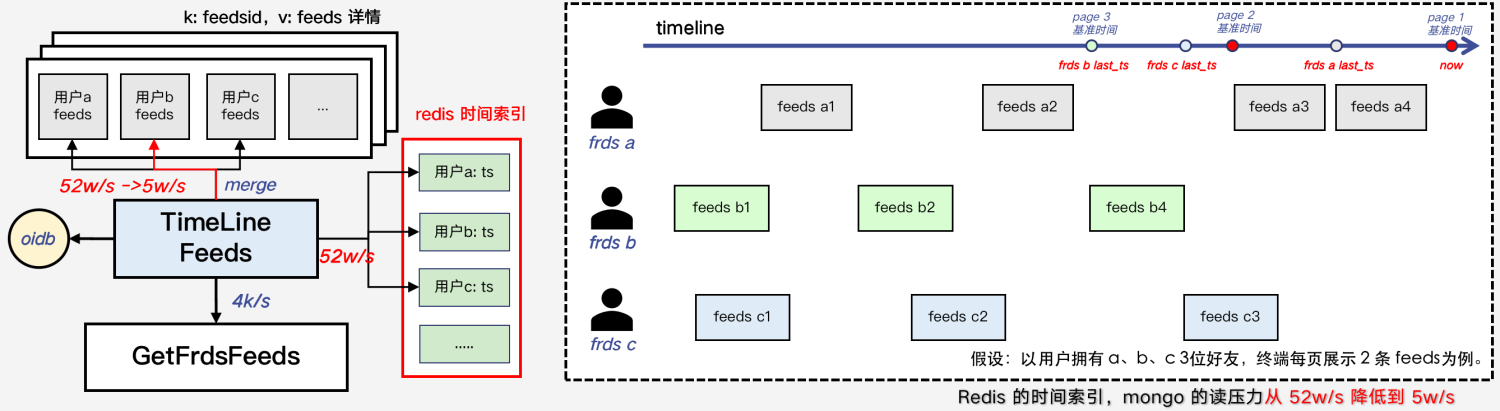
Redis 记录所有用户最近发表 feeds 的时间戳。首页拉取时,以当前时间为基准,根据 redis 时间索引只拉取最近的10个好友的10条 feeds;翻页时,以上一页的最后一条 feeds 时间为基准,找到基准时间最近的10个好友,加上前一页展示的所有好友,拉取这些好友的基准时间前发表的10条 feeds,排序后返回。
缺陷很明显:越往后翻页,查好友数量越多,拉取速度越慢。但是按照统计数据来说,超过 90% 的用户都是只看第一页,因此问题不是很严重。
那针对这 10% 的活跃用户,我们有办法进行优化吗?作为开发人员,我们要有精益求精,极致优化的追求。
方案就是叠加缓存,我们知道时间是单向流逝的。因此,用户 a 在时间 t0~t1 内看到的 feeds 应该说是固定的,不管用户是在 t2、t3、t4 进来查看,只要查看的时间区间是 t0~t1 那就是同一份数据。基于这个原因,我们可以额外做缓存优化。
具体来说,就是用户每次进入页面,我们将当前计算好的 feeds 列表缓存在 mongo 中(只缓存最近10页),下次用户进入页面时,计算增量的 feeds 列表,然后合并到 feeds 列表缓存中去。这样,用户特定时间区间内的 feeds 列表只会计算1次。
当然,这种策略更复杂,也会有额外的存储消耗,我们可以做进一步优化。
手Q游戏中心,毕竟不是一个 feeds 流的产品形态,只是希望展示用户最近的好友动态。因此产品策略上,对 feeds 的保留时间做了限制,每个用户只保留最近 N 条。
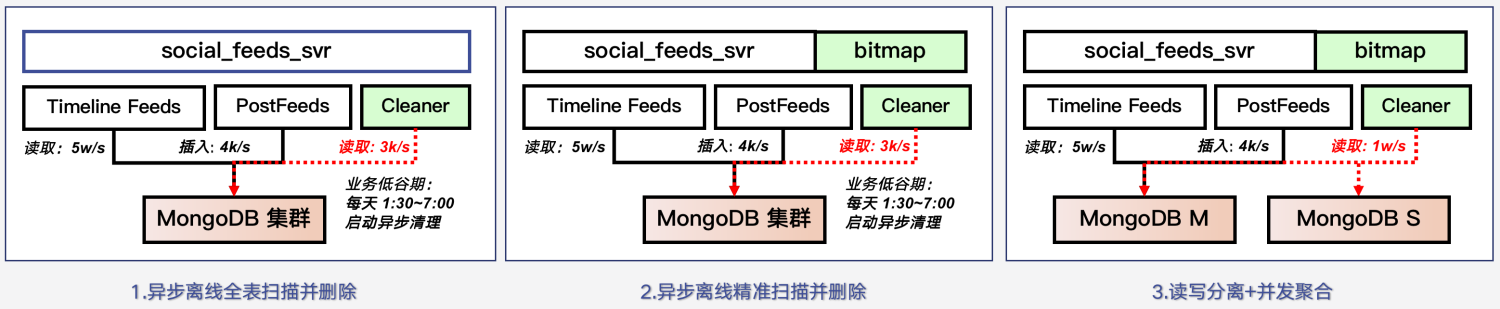
我们采用的方案是:在业务谷期,对 feeds 存储离线扫描;同时为了减少离线扫描的数量,用咆哮位图记录每天发表过 feeds 的用户;同时做了读写分离和合并查询,提升扫描速度。
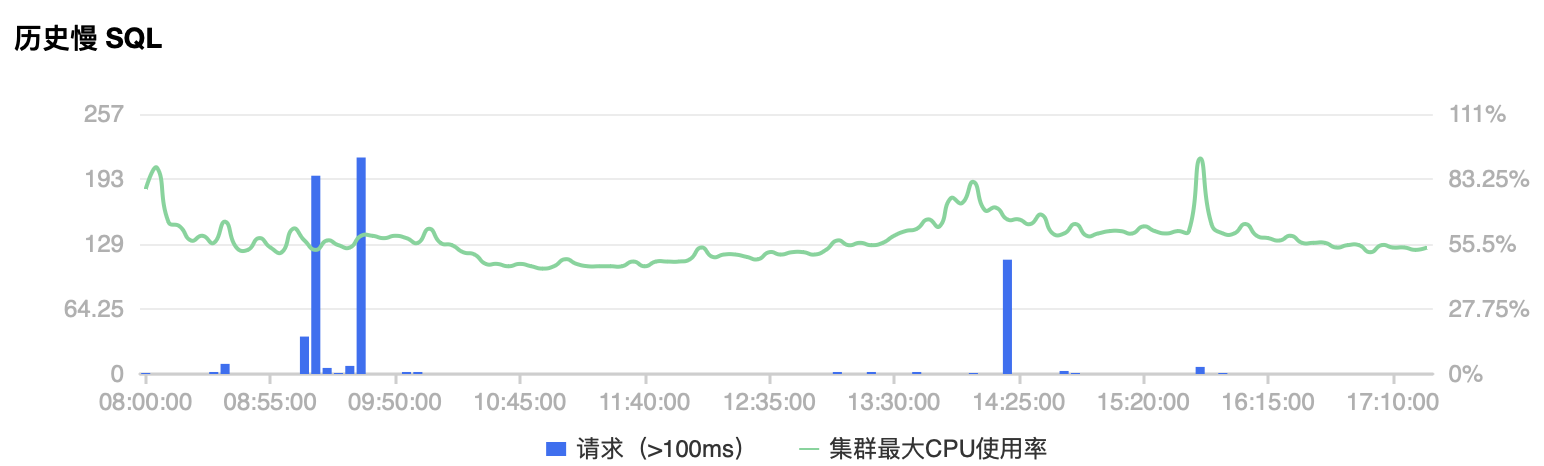
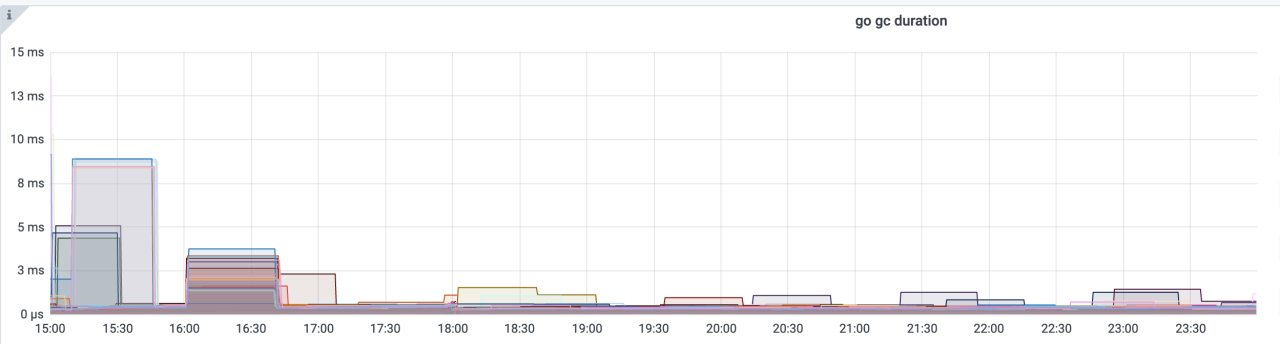
上线后,发现服务器 CPU 消耗较多,Perf 后发现大多数在 gc 上。

我们用 Sync.Pool 复用了大多数网络 IO 过程中的临时对象,优化后CPU 降低了 18%,gc 耗时也降低了很多。
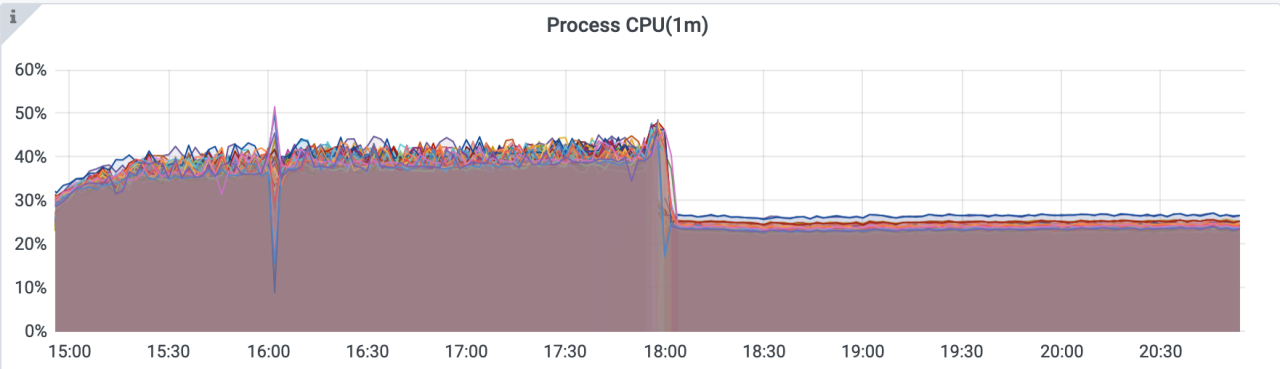
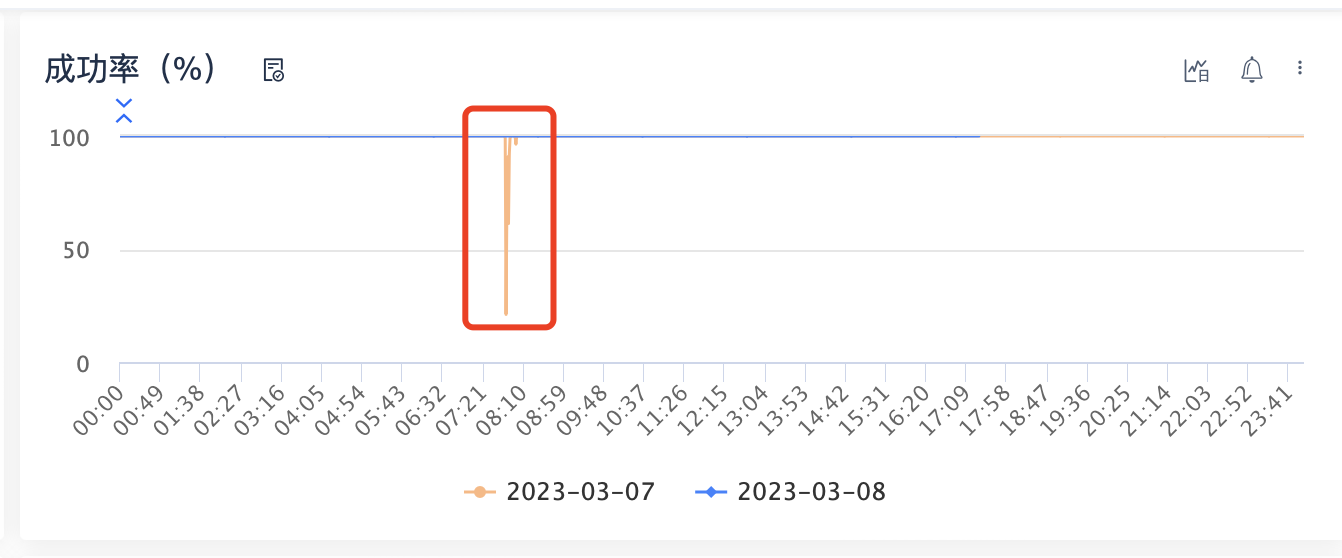
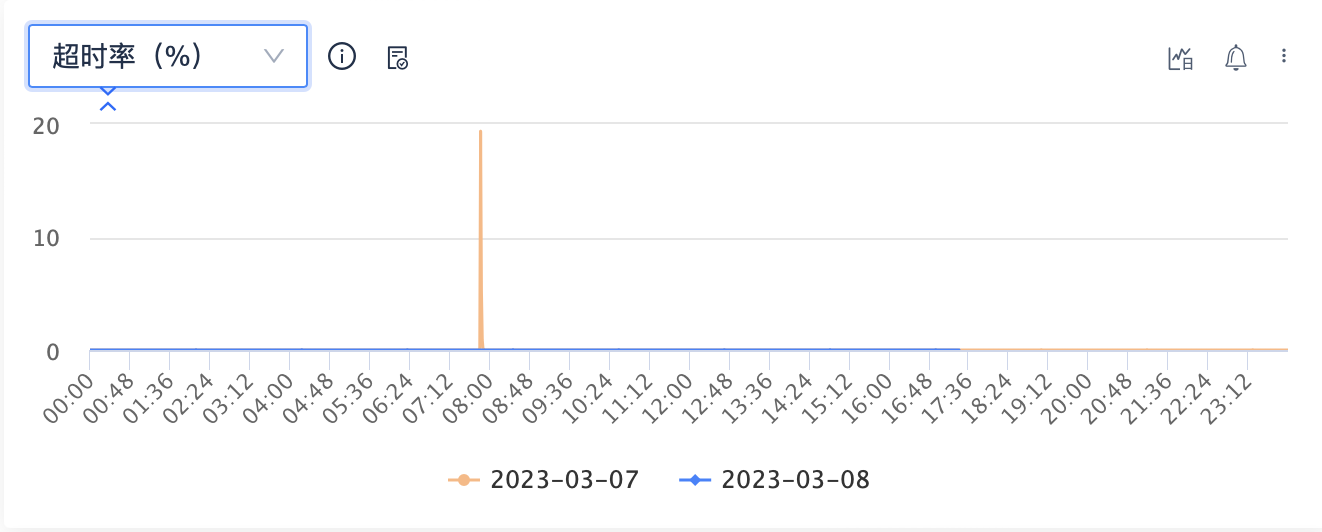
线上 Mongo 集群经常出现尖峰,峰值期间业务访问质量大受影响。
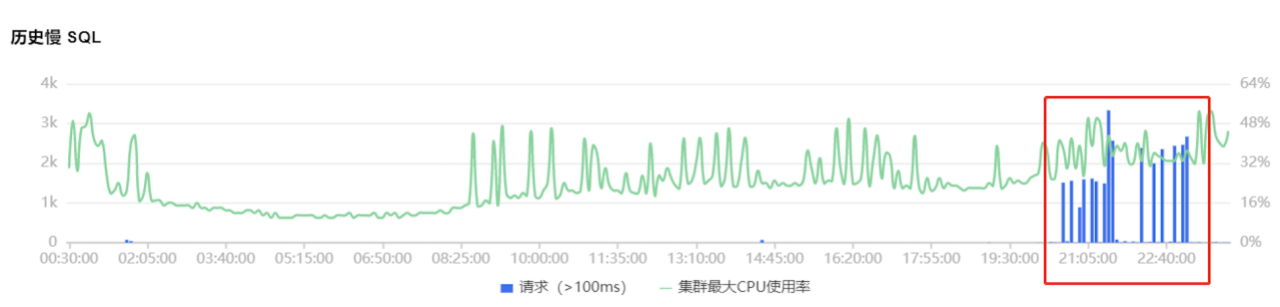
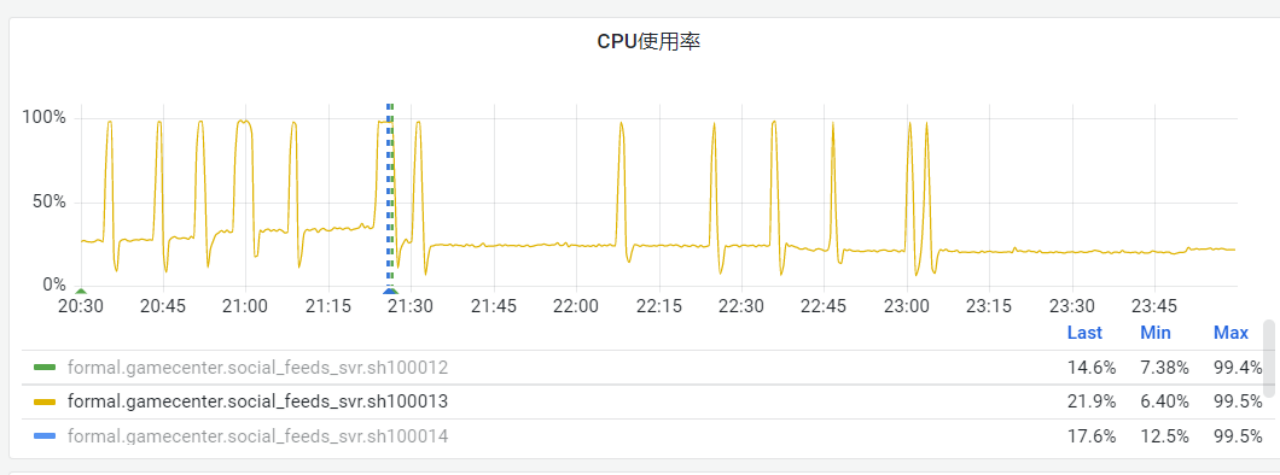
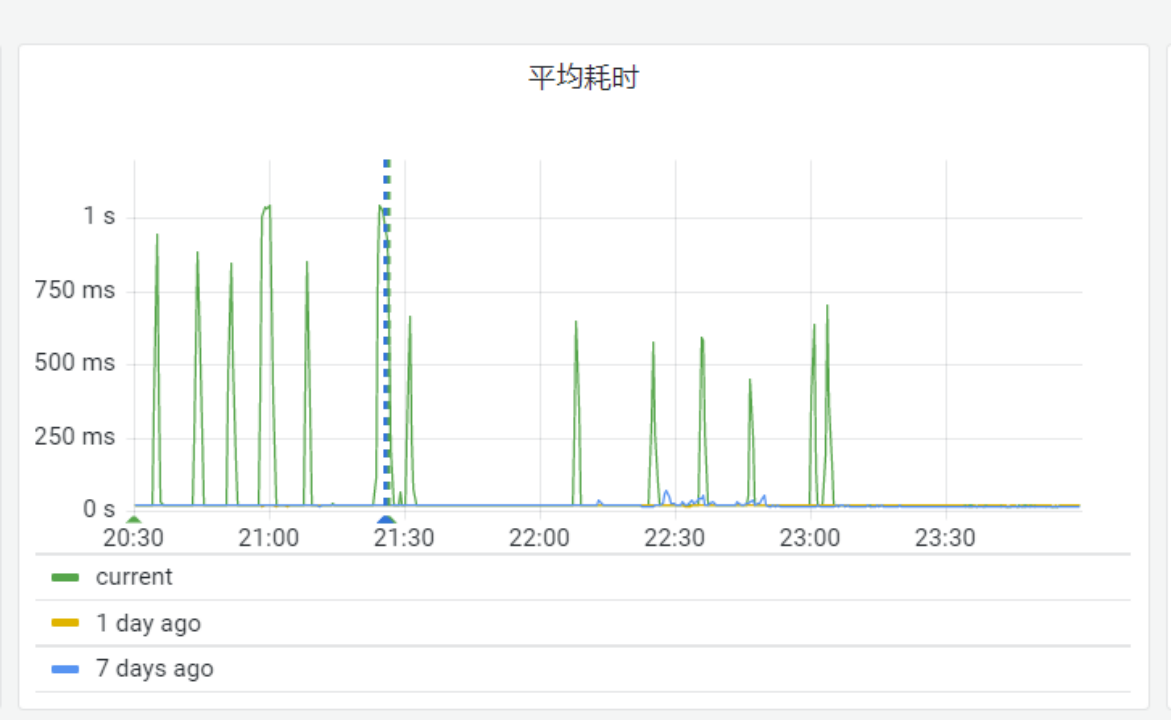
定位后发现,毛刺是由于业务服务和 Mongos 实例链接断掉后,短时间内大批量新建链接引起的。上游调用下来超时时间800ms。db 高负载时,由于800ms内无法响应,driver 认为出错,直接关闭链接,重新新起链接去查,新链接在 800ms 内无法建立,导致driver 不停地关闭、重建新链接;导致雪崩的出现。
业务侧设置每台实例 maxPoolSize=minPoolSize=15。
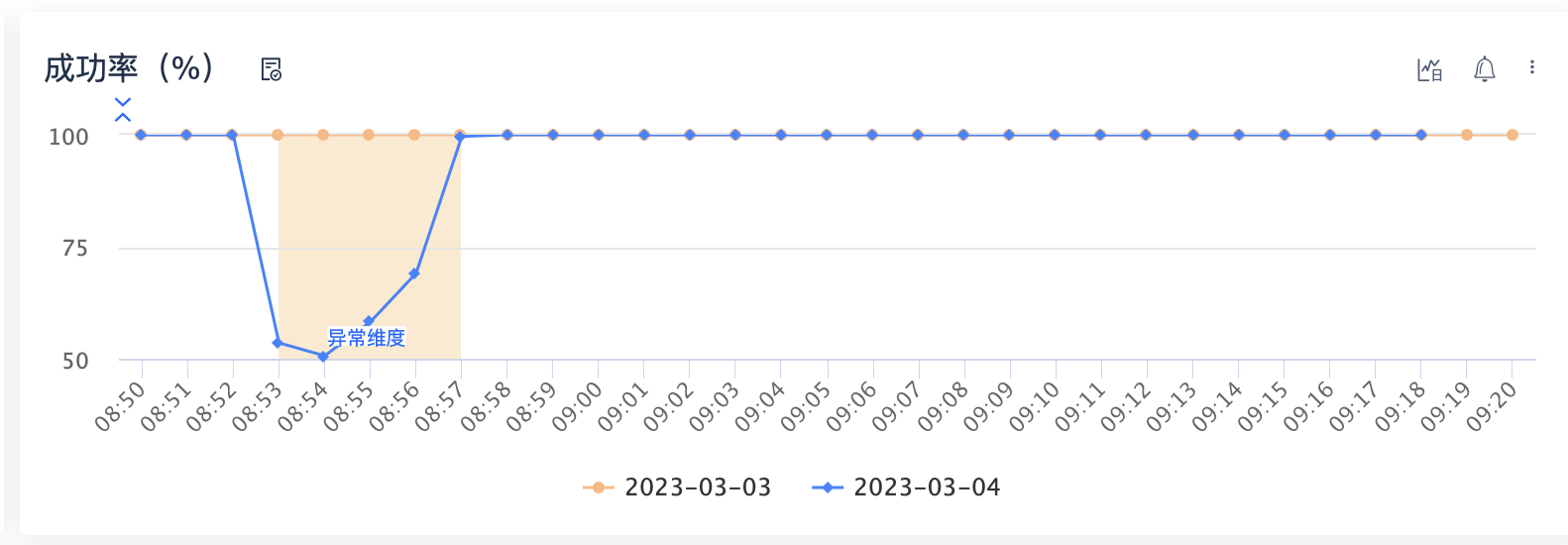
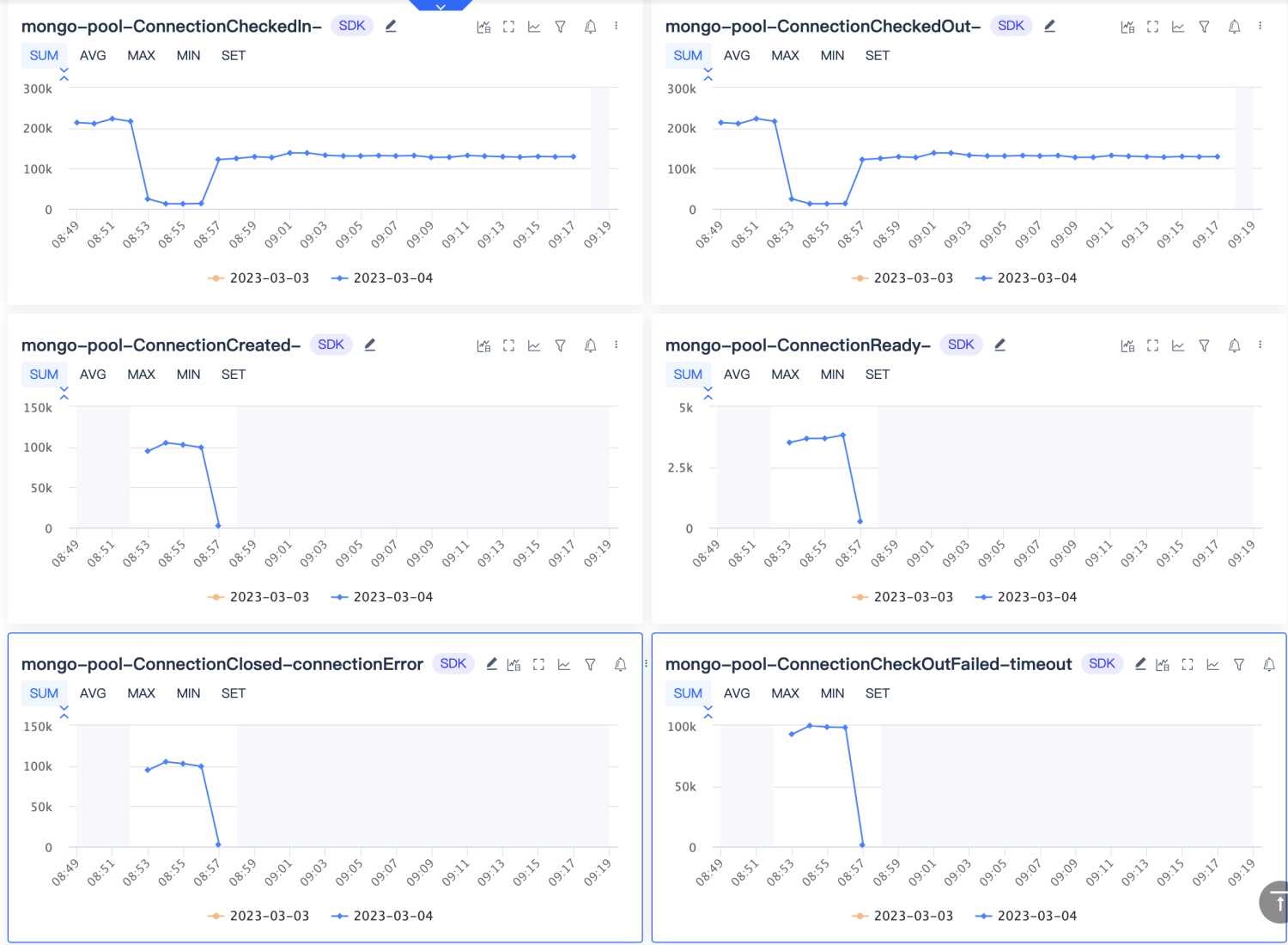
1. 线上 Mongod 集群高负载,偶尔出现一些超时慢查询,超过 800ms。
2. 业务使用连接池访问,高负载时链接访问1s超时了,导致链接被释放。
3. 连接池监控发现链接不够了,新起链接去 mongos,同样 1s 超时释放超时连接。
4. 后面反复这个流程,导致1分钟内不停的创建新链接,达到13w/min,引起雪崩。
调整完之后业务侧已经不受影响,即时偶尔有超时,也不会产生雪崩效应。