

ES除了拥有索引上的优势,最重要的还是数据的结构,这都是ES为什么效率高,会使用它的原因。
1,结构化数据 VS 非结构化数据
其他的不同之处还有: 结构化数据往往占用的空间较小,占企业数据的 20% 左右,容易管理。 非结构化数据通常占用更多的存储空间,约占企业数据的 80% 左右,比较难以管理
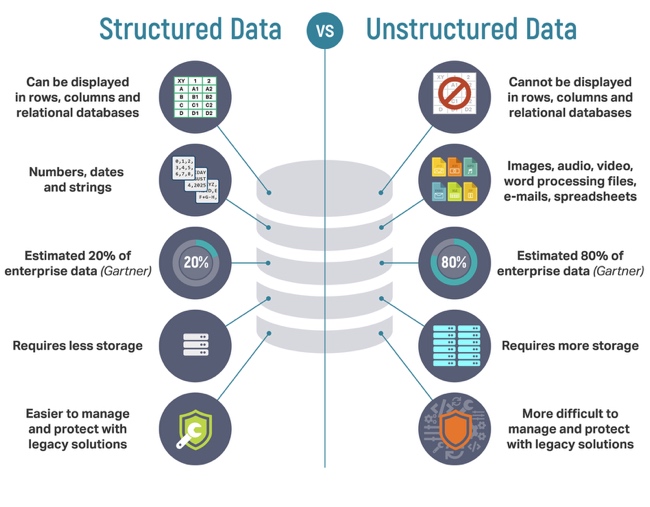
到这里,为什么需要使用 ES 进行搜索的答案就很明确了:对于非结构化文本(比如评论内容),传统的结构化搜索难以满足需求,于是就会使用 ES 进行全文搜索。当然 ES 不仅可以进行全文搜索,也可以进行一部分的结构化搜索,更加扩大了他的应用范围。对于数据量巨大的情景,有公司会使用 ES 代替传统的 MySQL 管理数据。
本小结主要是介绍 ES 的一些基本概念,目的是方便之前没有了解过 ES 的同学可以理解这次分享所介绍的内容。
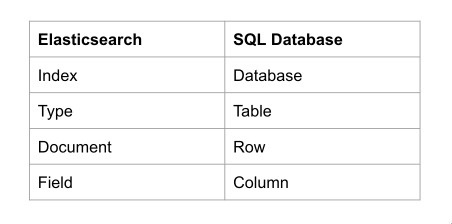
ES 在设计存储模型时,考虑了大家从关系型数据库转换肯能带来的困难,于是设计了 Index、Type、Document、Field 分别于对应传统关系型数据库(比如 MySQL) 的 Database、Table、Row、Column。 注意: ES 存储时,并没有 Type 的概念,同一个Index 里的 Type 会拍平存储,只是方便理解才会对使用者提供这样一个抽象。由于Type 的存在会带来一些问题,在后续的版本里会逐步移除。
ES 底层基于 Lucene 开发,Lucene作为其核心来实现索引和搜索的功能。我们虽然讲的是 ES,但很大一部分内容是 Lucene 的实现。
