

相比于哨兵集群,cluster集群能支持扩容,且无须额外的节点来监控状态,所以使用这种模式集群的系统会用得更多些。
在cluster集群里会有16384个哈希槽(hash slot),在设置Redis的键(key)时,会先用CRC16算法对key运算,并用16384对运算结果取模,结果是多少,就把这个key放入该结果所编号的哈希槽里。具体的数学算法如下所示,其中slotIndex表示该key所存放的槽的编号。
slotIndex=HASH_SLOT=CRC16(key) mod 16384读取key的操作和写操作相反,先用上述公式求得对应的槽编号,再到对应的哈希槽里取值。
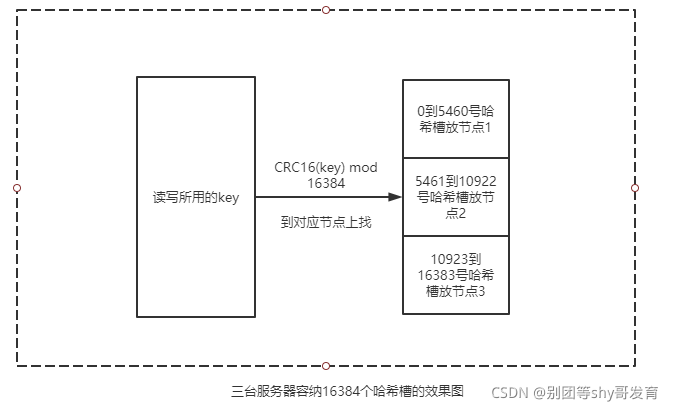
上文中提到的cluster集群里有16384个哈希槽,并不意味着在这种集群模式中一定要有16384个节点。哈希槽是虚拟的,是会被分配到若干台集群里的机器上的。
比如某cluster集群由三台Redis服务器组成,那么编号从0到5460号哈希槽会被分配到第一台Redis服务器,5461到10922号哈希槽会被分配到第二台服务器,10923到16393号哈希槽会被分配到第三台服务器上,具体效果如下。
同理,如果某cluster集群是由六台Redis服务器组成的,那么每台服务器上也会被平均分配一定数量的哈希槽。此外,cluster集群里也支持主从复制模式,即分配到一定数量哈希槽的Redis服务器也可以携带一个或多个从节点。在下图中,大家能看到包含三主三从的cluster集群的效果。
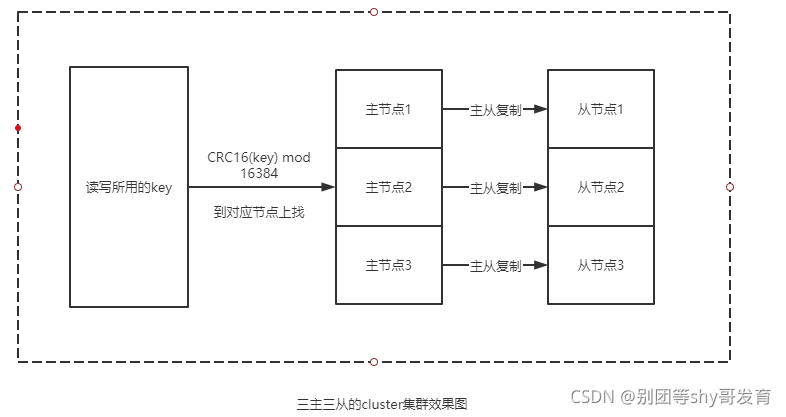
这里将通过如下步骤搭建如上图所示的三主三从的cluster集群,其他集群也可参照此集群的搭建方式。
宿主机配置文件目录:/root/redisconf 第一个主节点:clusterMaster1.conf
port 6379 # Redis服务器端口为6379
dir "/redisConfig" # 指定该节点的日志路径
logfile "clusterMaster1.log" #指定该节点的日志文件名
cluster-enabled yes #开启cluster集群模式,并把该节点加入集群
cluster-config-file nodes-6379.conf #设置cluster集群相关的配置文件,该文件会自动生成第二个主节点:clusterMaster2.conf
port 6380
dir "/redisConfig"
logfile "clusterMaster2.log"
cluster-enabled yes
cluster-config-file nodes-6380.conf第三个主节点:clusterMaster3.conf
port 6381
dir "/redisConfig"
logfile "clusterMaster3.log"
cluster-enabled yes
cluster-config-file nodes-6381.conf第一个从节点:clusterSlave1.conf
port 16379 #从节点端口
dir "/redisConfig"
logfile "clusterSlave1.log"
cluster-enabled yes
cluster-config-file nodes-16379.conf注意,这里并没有设置主从关系,而主从关系将在后继的步骤里面设置。
第二个从节点:clusterSlave2.conf
port 16380
dir "/redisConfig"
logfile "clusterSlave2.log"
cluster-enabled yes
cluster-config-file nodes-16380.conf第三个从节点:clusterSlave3.conf
port 16381
dir "/redisConfig"
logfile "clusterSlave3.log"
cluster-enabled yes
cluster-config-file nodes-16381.confredisClusterMaster1
docker run -itd --privileged=true --name redisClusterMaster1 -v /root/redisconf:/redisConfig -p 6379:6379 redis:latest redis-server /redisConfig/clusterMaster1.conf由于再通过redis-server命令启动Redis服务器时传入了clusterMaster1.conf配置文件,因此该容器里的Redis会自动加入cluster集群,当然现在集群中就只有这一个节点。由于在clusterMaster1.conf配置文件里指定了cluster集群相关的配置文件是node-6379.conf,因此在启动时就会自动生成该文件,此时在与容器里/redisConfig映射的/root/redisconf目录中就能看到生成的nodes-6379.conf文件
redisClusterMaster2
docker run -itd --privileged=true --name redisClusterMaster2 -v /root/redisconf:/redisConfig -p 6380:6380 redis:latest redis-server /redisConfig/clusterMaster2.confredisClusterMaster3
docker run -itd --privileged=true --name redisClusterMaster3 -v /root/redisconf:/redisConfig -p 6381:6381 redis:latest redis-server /redisConfig/clusterMaster3.confredisClusterSlave1
docker run -itd --privileged=true --name redisClusterSlave1 -v /root/redisconf:/redisConfig -p 16379:16379 redis:latest redis-server /redisConfig/clusterSlave1.confredisClusterSlave2
docker run -itd --privileged=true --name redisClusterSlave2 -v /root/redisconf:/redisConfig -p 16380:16380 redis:latest redis-server /redisConfig/clusterSlave2.confredisClusterSlave3
docker run -itd --privileged=true --name redisClusterSlave3 -v /root/redisconf:/redisConfig -p 16381:16381 redis:latest redis-server /redisConfig/clusterSlave3.conf查看创建好的所有容器

此时打开描述redisClusterMaster1节点集群链接配置的nodes-6379.conf文件,就会看到如下内容

第2行能看出该节点属于master(主)节点,它只连接到myself滋生,没有同其他Redis阶段关联,观察nodes-6380等配置文件,也会发现当前这些节点均没有关联其他节点,在后续步骤会使用meet命令关联各节点。
节点名 | IP地址 | 端口 |
|---|---|---|
redisClusterMaster1 | 172.17.0.2 | 6379 |
redisClusterMaster2 | 172.17.0.3 | 6380 |
redisClusterMaster3 | 172.17.0.4 | 6381 |
redisClusterSlave1 | 172.17.0.5 | 16379 |
redisClusterSlave2 | 172.17.0.6 | 16380 |
redisClusterSlave3 | 172.17.0.7 | 16381 |
进入redisClusterMaster1所在容器,执行以下命令连接该节点和其他节点,注意,这里的IP地址是Docker容器工作的IP地址,而不是127.0.0.1

在第一行通过cluster meet命令连接工作在172.17.0.3:6380的redisClusterMaster2节点,其他命令以此类推。
使用redis-cli命令用客户端进入redisClusterMaster1服务器,在运行cluster info命令

可以看出集群有6个节点(cluster_known_nodes:6),但cluster_state的值为fail(失败)状态,原因是还没有给集群中分每个几点分配哈希槽。
分配哈希槽的命令格式如下:
redis-cli -h 172.17.0.2 -p 6379 CLUSTER ADDSLOTS n通过-h和-p指向Redis服务器节点,通过cluster addalots命令添加哈希槽,其中n是哈希槽的编号。根据上文的描述,要把0到5360号哈希槽分配到redisClusterMaster1节点上,如果要运行命令要运行5000多次,所以用如下脚本来分配。
setHashSlots.sh脚本也是让在/root/redisconf目录
for i in $(seq 0 5460)
do
/usr/local/bin/redis-cli -h 172.17.0.3 -p 6380 CLUSTER ADDSLOTS $i
done运行该脚本

5461到10922分配到redisClusterMaster2
for i in $(seq 5461 10922)
do
/usr/local/bin/redis-cli -h 172.17.0.3 -p 6380 CLUSTER ADDSLOTS $i
done10923到16383分配到redisClusterMaster3
for i in $(seq 10923 16383)
do
/usr/local/bin/redis-cli -h 172.17.0.3 -p 6380 CLUSTER ADDSLOTS $i
done至此,哈希槽分配完毕。
在进入redisClusterMaster1所在窗口,redis-cli进去客户端,再运行cluster info查看cluster集群的情况

设置从节点的方式是用redis-cli命令进入从节点Redis服务器,并运行cluster replicate <对应主节点的node-id>
如何直到主节点的node-id?回到redisClusterMaster1窗口,用redis-cli连接服务器之后,使用cluster nodes命令,虽然没有设置主从关系,但是节点已经互联。

前面那个长串就是node-id
第一个从节点:redisClusterSlave1

redisClusterSlave1设置为redisClusterMaster1的从节点
第2个从节点:redisClusterSlave2

redisClusterSlave2设置为redisClusterMaster2的从节点 第3个从节点:redisClusterSlave3

redisClusterSlave3设置为redisClusterMaster3的从节点
再进入redisClusterMaster1所在服务器,运行cluster nodes

三主三从关系已经配置完毕
先用redis-cli -p 16381命令接入redisClusterSlave3所在的服务器,此时输入set命令,就能看到如下所示的错误信息

根据此前描述的cluster集群知识,在set命令时会先对键(name)进行CRC16运算,再根据结果把这个键放入对应哈希槽所在的节点,从第2行的输出能看到这个name键应当放入172.17.0.3:6380所在的5798哈希槽里。在操作中,用户是透明地进行数据的读写操作,而不希望看到此类的读写错误。 为了达到这个效果,需要在redis-cli命令后加入-c参数,以实现互联的效果。

在第1行的redis-cli命令后带了-c参数,所以当第2行执行set命令时,虽然不该把name键放入本节点对应的哈希槽里,但是在cluster集群中的Redis服务器会自动把该数据重新定位到172.17.0.3:6380节点上,从第3行的输出里能得到验证。

然后,使用get命令,虽然name键对应的数据没有存在该节点上,但同样可以读到name键对应的数据。这种“自动定位”带来的“读写透明”效果正是开发项目所需要的。
如果用docker stop redusClusterMaster1命令停止172.17.0.3:6380所对应的主节点,然后用set命令设置键name的数据,就会发现该键会被设置到其他节点上。也就是说,当节点失效后,cluster集群会自动再分配哈希槽,从而实现故障自动修复的效果。
上文三主三从的cluster集群里,针对键的读写操作将会摊到三个主节点上,比如当前针对Redis缓存的并发量是每秒3000次访问,那么均摊到三台主节点上的访问请求也就每秒1000次,也就是说cluster集群能很好地应对高并发带来的挑战。 随着项目业务量的增加,对cluster集群的访问压力有可能会增大,此时就需要通过向cluster集群里新增节点来承受更大的并发量。通过如下步骤,将会向上文搭建的三主三从的cluster集群里再增加一个主节点一个从节点,一次实现扩容效果。
在/root/redisconf目录下新增clusterMasterNew.conf配置,用以配置新增主节点的信息,配置如下所示:
port 6385
dir "/redisConfig"
logfile "clusterMasterNew.log"
cluster-enabled yes
cluster-config-file nodes-6385.conf随后用docker run命令启动该容器以及其中的Redis服务器
docker run --privileged=true -itd --name redisClusterMasterNew -v /root/redisconf/:/redisConfig -p 6385:6385 redis:latest redis-server /redisConfig/clusterMasterNew.conf
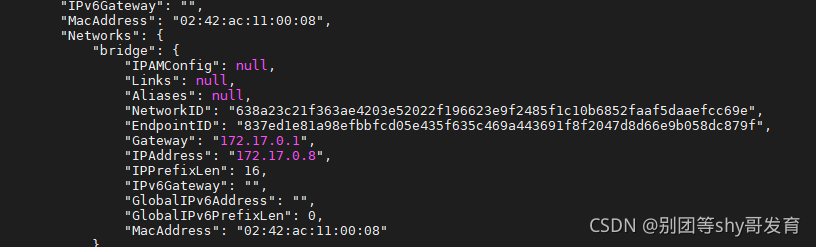
启动后再执行docker inspect redisClusterMasterNew命令,能看到该redis服务器节点的IP地址是172.17.0.8
在/root/redisconf目录里,新建clusterSlaveNew.conf配置文件,用以配置新增从节点(将使用16385端口)的信息,代码如下所示:
port 16385
dir "/redisConfig"
logfile "clusterSlaveNew.log"
cluster-enabled yes
cluster-config-file nodes-16385.conf随后用如下的docker命令启动该容器以及其中的Redis服务。
docker run --privileged=true -itd --name redisClusterSlaveNew -v /root/redisconf/:/redisConfig -p 16385:16385 redis:latest redis-server /redisConfig/clusterSlaveNew.conf
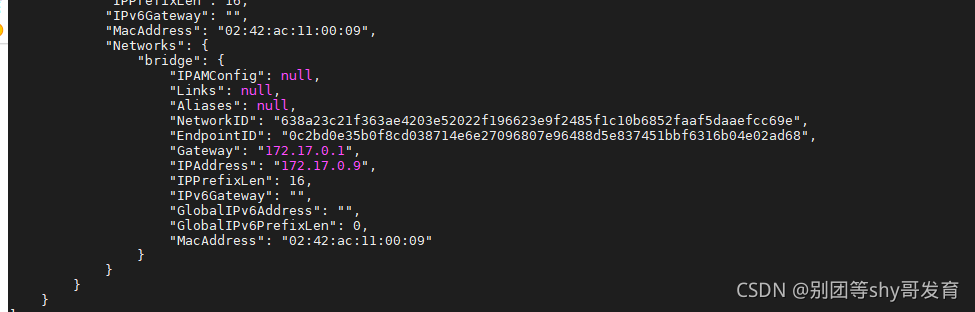
启动后,通过docker inspect redisClusterSlaveNew命令可以看到该Redis服务器的IP地址是172.17.0.9
注意,在cluster集群里不能通过slaveof的方式设置主从模式,所以需要先把节点加入cluster集群,再通过命令设置两者的主从关系。
通过redis-cli命令,进入redisCLusterMaster1节点所对应的Redis服务器,再通过如下的两条meet命令把上述两个节点加入cluster集群。

用redis-cli命令进入redisClusterSlaveNew节点所对应的Redis服务器,设置主从关系。

cluster replicate 后面跟的参数是redisClusterMasterNew节点对应的node-id。
通过上述步骤,确实能把两个节点加入cluster集群中,但是没有分配哈希槽,所以这两个节点还无法真正地承载缓存数据。此时进入redisClusterMasterNew容器对应的命令行窗口,通过如下命令可以给redisClusterMasterNew节点分配哈希槽:
redis-cli --cluster reshard 172.17.0.2:6379 --cluster-from 551056dbbf073c7a9e7a5a7d07ae459bfc0e5421,1110d0069971bbe0b65e515081367d9520dc769a,84eefde5160b4398e4290e97a71535de40c95407 --cluster-to cac1636bb6c3abba84fad3bc5bbc502311e93b1e --cluster-slots 1024其中,
reshard后面的172.17.0.2:6379表示由这个Redis服务器执行重新分配哈希槽的命令--cluster-from后面跟随的三个参数是原来三个主节点的node-id,即分配哈希槽的源节点--cluster-to后面跟随的参数表示目标节点--cluster-slots后面跟随的参数表示分配哈希槽的数量。
上述命令执行后会从原来的三个主节点里各取1024个哈希槽分配到redisClusterMasterNew节点上,从而使节点也能用哈希槽存放对应的键。 至此,完成了扩容动作,如果此时运行cluster info命令,就能看到如下所示的部分输出效果。
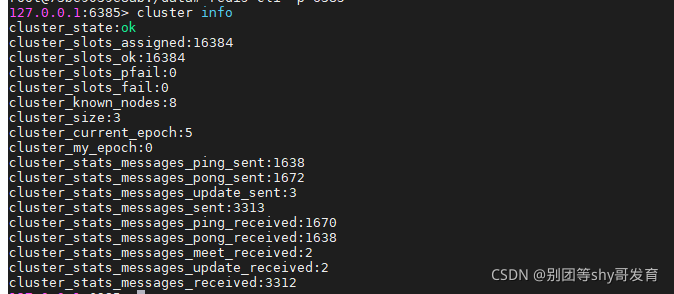
可以看到,第3行和第4行可看出该集群有16384个哈希槽,通过第7行的输出能看出集群有8个节点,确认扩容成功 在扩容时请注意,在迁移哈希槽以及其中的数据这段时间内,这部分数据是不可用的,由此可能出现缓存失效的现象,所以建议一般在业务请求比较空闲的时候进行扩容动作,比如将扩容的时间放在周末的凌晨。 在扩容时,不必精确地让cluster集群里地主节点包含相同数量的哈希槽,有些误差也是可接受的,而且如果cluster集群里某台Redis服务器性能较好,还可以在其中适当多分配些哈希槽,从而进一步提升cluster集群的吞吐量。
