


导语 |2022年11月30日,OpenAI 发布了其最新的聊天机器人模型 ChatGPT。站长素材网开发者先后从其玩法体验、技术原理、上手方法和竞品洞察几个方面进行解读,并邀请腾讯前沿科技研究中心主任王强畅聊 ChatGPT 最受关注的问题(如果你对相关内容感兴趣,可点击一键跳转阅读)。然而,ChatGPT 成为现象级火爆技术之作的背后,是常年累月的技术积累和灵敏迭代。此次我们邀请腾讯 NLP 工程师张先礼深度解析 ChatGPT 进化历程——GPT 各代有何区别、如何演进?其现有能力有什么不足?未来将会有什么发展方向?欢迎各位开发者阅读、分享与交流 ChatGPT 神话的缔造之路。
目录
1 背景介绍
2 原理解析——从发展历程了解 ChatGPT
2.1 Transformer
2.2 初代 GPT vs. BERT
2.3 GPT-2
2.4 GPT-3
2.5 InstructGPT
2.6 ChatGPT
3 热门关注点
3.1 模型到底是否需要标签监督?
3.2 ChatGPT 对多模态有何启发?
3.3 ChatGPT 为何能对同个问题生成不同的答案?
3.4 ChatGPT 如何拒绝回答知识范围外的问题?
3.5 如何获得更强的泛化?
3.6 小结
背景介绍
2022年11月30日,OpenA I发布其最新的聊天机器人模型—— ChatGPT,由此引发热烈讨论。作为一个目前最接近“六边形”战士的聊天机器人,它不仅能够用来聊天、搜索、翻译,还能写故事、写代码甚至是 debug。由于其能力过于惊艳, ChatGPT成为历史上最快达到1亿用户的应用。各位开发者对其背后的技术充满了好奇。
本文将围绕ChatGPT探讨其原理解析、优缺点、未来发展方向。其中将介绍从Transformer逐步进化到 ChatGPT 的方式,并从分析 ChatGPT 的优缺点开始,思考ChatGPT、AI 的未来发展方向和改进点。
本章会逐步介绍Transformer(2.1节)、初代GPT vs. BERT(2.2节)、GPT-2(2.3节)、 GPT-3(2.4节)、 InstructGPT(2.5节)、ChatGPT(2.6节)。如果你对某个演进节点特别感兴趣,可以优先跳转到对应章节阅读了解。
2017 年,Google 的一篇题为 Attention is all you need 的 Paper 横空出世,自此完全使用 Attention 机制的 Transformer 模型开始主导 NLP 领域。不久后,利用 Transformer 模型结构的预训练语言模型 GPT 和 BERT 大放异彩。时至今日,基于 GPT 和 BERT 的预训练语言模型进行 Fine-tuning 仍然是 NLP 中广泛任务的首选范式。除了 NLP 领域,Transformer 结构也被应用到了计算机视觉领域,由此诞生了一系列比CNN更强大的模型,如 ViT、BEiT 和 MAE。可以说,Transformer 结构继 RNN、CNN(以及其一系列变体 LSTM、GRU、ResNet、DenseNet 等)之后,在 Inductive Bias 方向上打开了一个新世界的大门。
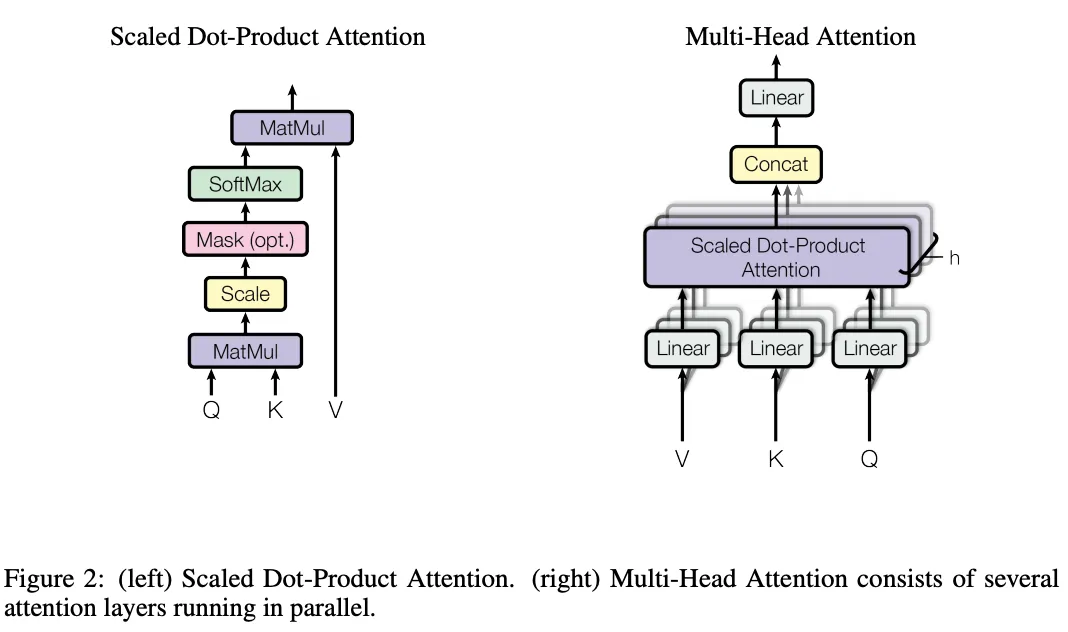
图一 Self-Attention 和 Multi-Head Attention
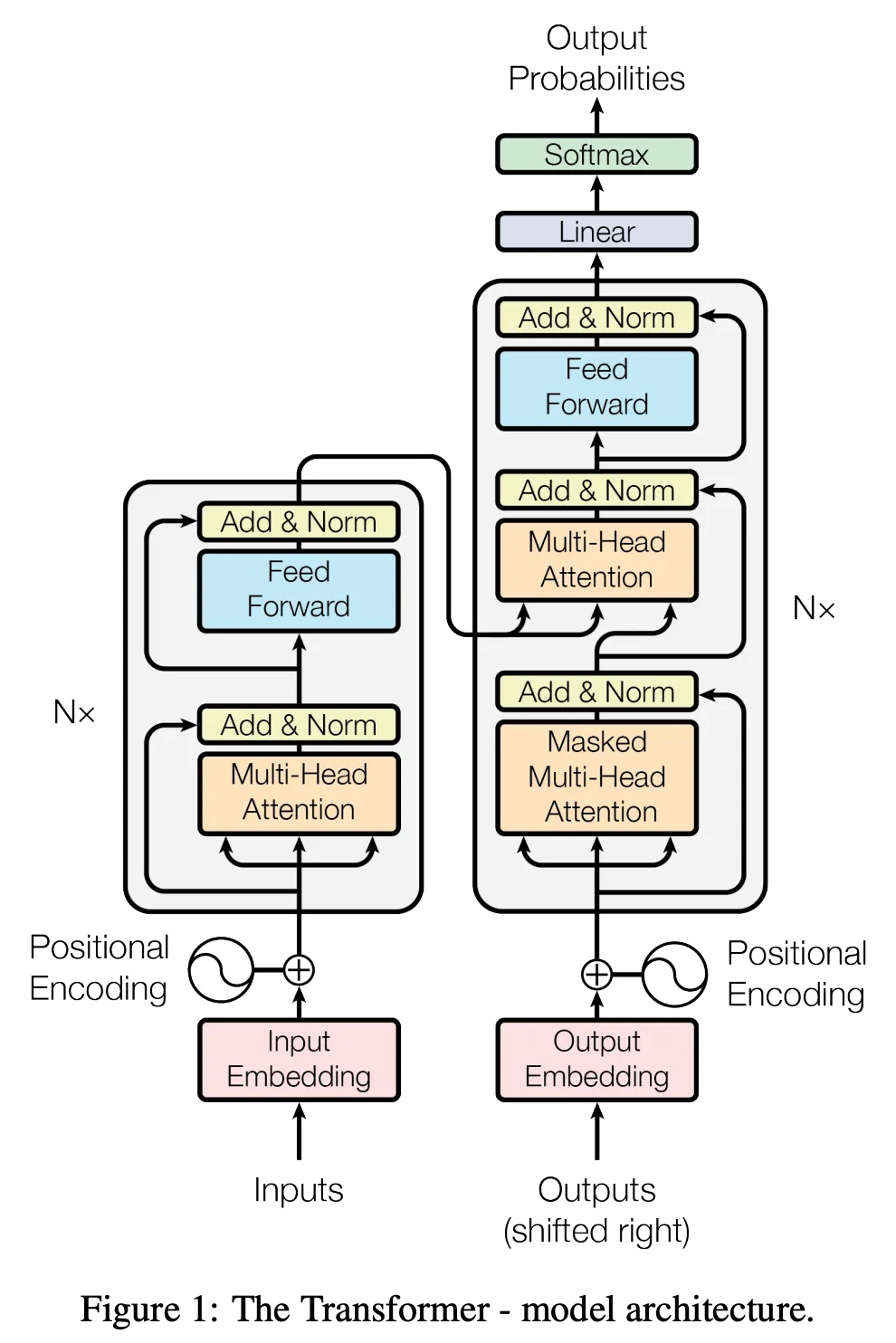
图二 Transformer 整体结构
这里我们会先讲初代GPT,然后介绍BERT实验,最后在2.2.3将二者的试验训练进行对比。
接下来我们会分别讲到初代GPT的模型结构、训练方法、Task-specific input transformations、数据集、实验结果概览,然后进行小结。

图三 Transformer Decoder和GPT Decoder对比
GPT (Generative Pre-Training) 是 OpenAI GPT 系列的开山之作。在模型结构方面, GPT 仅使用了 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动。如图三所示,原本的 Decoder 包含了 MHA 和 MMHA,而 GPT 只保留了 MMHA,这确保了 GPT 只能关注上文的信息,从而达到单向模型的目的。
初代GPT的无监督 Pre-training 是基于语言模型进行的,给定一个无监督语料
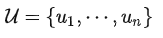
,GPT利用标准的语言建模目标最大化以下似然:
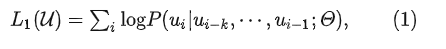
其中
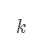
是上下文窗口的大小。
在利用目标函数(1)进行无监督 Pre-training 得到模型后,将其直接应用到有监督任务中。假设有一个有标注的数据集
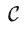
,其中每个样本的inputs包含一系列的 token,即
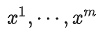
和一个label

。将 inputs 输入 Pre-training 的模型得到最后一个 transformer decoder block 的状态表征
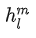
,然后将状态表征输入到在 Fine-tuning 阶段新加入的线性输出层预测
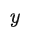
:
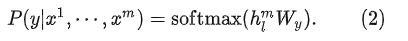
因此,Fine-tuning阶段最大化以下目标:
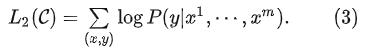
此外,初代 GPT 将语言建模作为微调的辅助目标以帮助 Fine-tuning 阶段(a)提升泛化性,(b)加速模型收敛。具体地,整个 Fine-tuning 阶段的优化目标为:
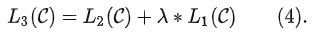
相比Pre-training阶段,Fine-tuning 引入了额外的参数包含 和 delimiter tokens(分隔符) 的 embeddings。而 delimiter tokens 是针对 Fine-tuning 阶段不同的下游 tasks进行设计的,目的是为了使得 Pre-training 得到的模型能在 Fine-tuning 的时候适配不同的 tasks。
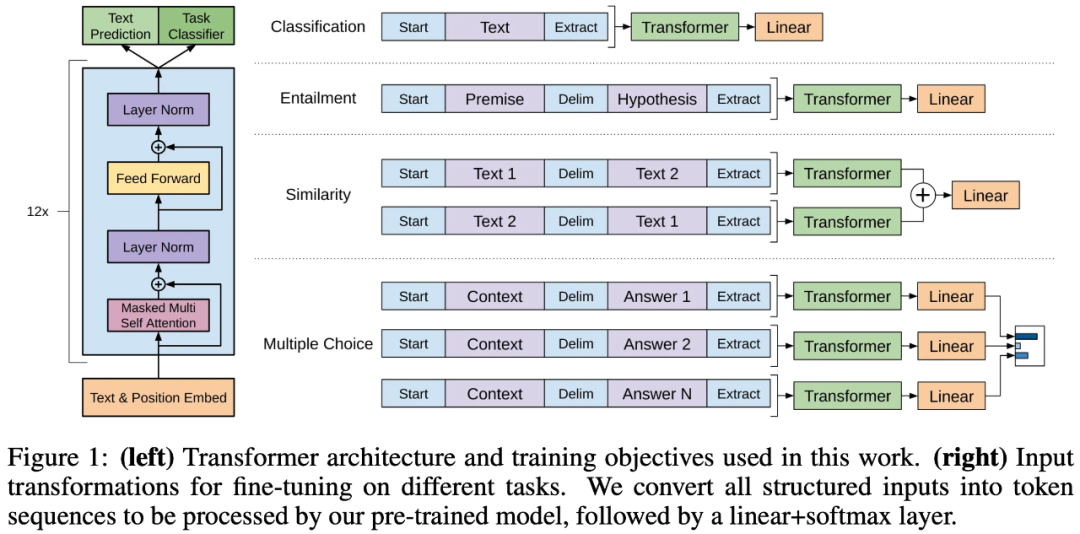
图四 特定于任务的输入转换
某些任务(如文本分类),GPT 可以对其进行直接如上所述的模型微调。而某些其他任务(如问答或文本蕴涵)和具有结构化输入的任务,如有序的句子对或文档、问题和答案的三元组,由于 GPT 的预训练模型是在连续的文本序列上训练的,因此需要一些修改才能将其应用于这些任务。初代 GPT 之前的工作提出了基于 transferred representations 的学习任务特定的结构。这种方法重新引入了大量特定于任务的定制,并且不对这些额外的结构组件使用迁移学习。相反,GPT 使用遍历式方法(traversal-style approach)将结构化输入转换为 Pre-training 模型可以处理的有序序列。这种输入转换避免了针对不同任务对模型结构进行大量更改。图四展示了特定于任务的输入转换方式,所有的输入转换都包含了随机初始化的起始(Start)和结尾(End)token,分别用
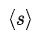
和
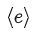
表示。具体于不同任务:
Textual Entailment 如图三所示,对于文本蕴含任务,GPT在 Fine-tuning 阶段将前提p(premise )和假设 h (hypothesis)的 token 序列拼接,并在二者中间添加分隔(delimiter) token ,用$表示。
Similarity 对于相似度任务,两个句子之间没有固有的顺序。为了反映这一点,GPT将输入的两个句子以两个可能的排列顺序拼接两次,同样需要将delimiter token添加在两个句子中间。这样两个句子就能获得两个不同顺序的输入转换。然后将两个转换后的输入独立地输入 Pre-trianing 得到的模型,再将得到两个序列表征进行element-wise加法得到最终的表征
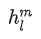
。最后将其输入到线性输出层。
Question Answering and Commonsense Reasoning 对于这两个任务,给定context document
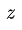
,question
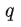
和可能的answer集合
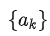
,GPT先将document context和question拼接(二者中间没有delimiter),然后再将其与每个answer进行拼接(中间有delimiter),得到
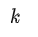
个序列
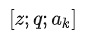
。每个序列都被Pre-training模型+Linear层独立地处理得到相应的分数,最终通过softmax层进行归一化,以产生可能答案的输出分布。
无监督Pre-training,BooksCorpus 7000本未发布的书,这些书里包含长段的连续文本,这使得生成模型能够学习以长距离信息为条件的依赖关系。
有监督Fine-tuning
Neural Language Inference
Question Answering & Commonsense Reasoning
Semantic Similarity & Classification
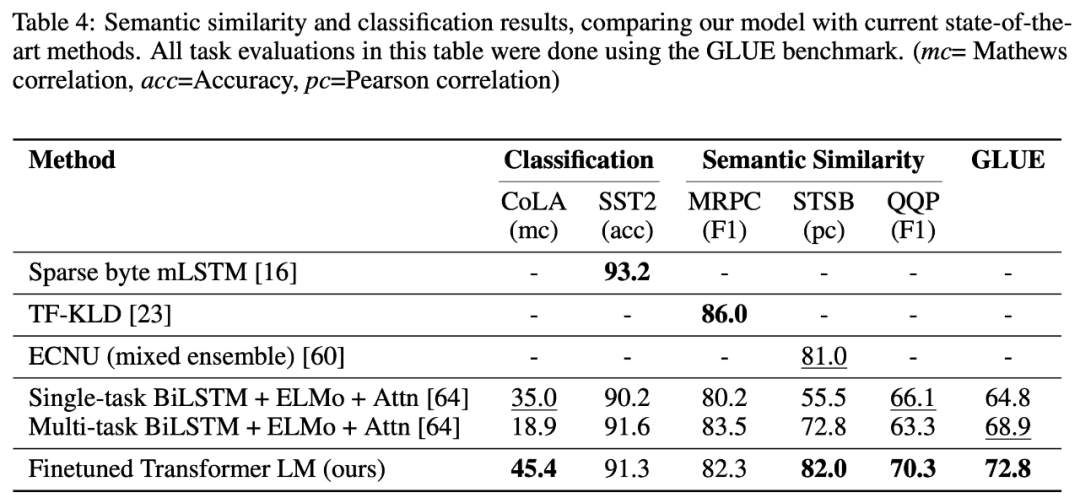
GPT Fine-tuning 阶段迁移层数的影响和 Pre-training 阶段迭代次数对 zero-shot 性能的影响(GPT vs. LSTM)
图五
从图五(左)可以看出,Fine-tuning 阶段使用更多层数的 Pre-training 模型可以显著提升下游任务的性能;而图五(右)说明(a)GPT在 zero-shot 方面比 LSTM 效果好,并且方差低(方差低没有数据展示,但作者在原文中提到了),(b)随着 Pre-training 的训练步数的增加,GPT 的 zero-shot 能力稳步提高。
在有监督学习的12个任务中,初代GPT在9个任务上的表现超过了SOTA的模型。在的 zero-shot 任务中,初代 GPT 的模型要比基于 LSTM 的模型稳定,且随着训练次数的增加,其 zero-shot 的性能也逐渐提升。这些都表明初代 GPT 已经具备(相对)非常强的泛化能力,能够用到和有监督任务无关的其它 NLP 任务中。初代 GPT 证明了 transformer 对学习词向量的强大能力,在初代 GPT 得到的词向量基础上进行下游任务的学习,能够让下游任务取得更好的泛化能力。对于下游任务的训练,初代 GPT 往往只需要简单的微调便能取得非常好的效果。
本小节会讲BERT的模型结构、输入构造、训练方法、数据集和实验结果。
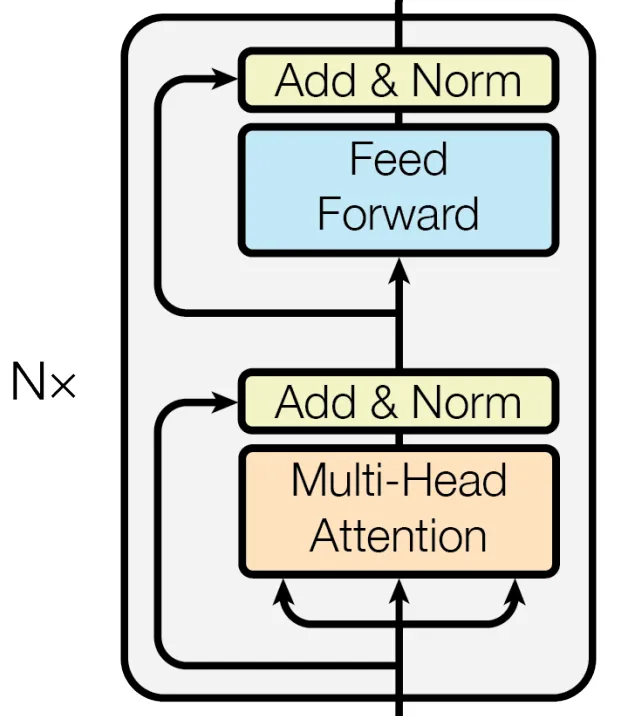
图六 BERT采用了 Transformer 的 Encoder 部分
BERT(Bidirectional Encoder Representations from Transformers ) 的模型结构采用了原始 Transformer 的 Encoder(如图六所示)。由于没有 MMHA,因此在建模时允许每个 token 访问其前后两个方向的 context,因此 BERT 是双向的语言模型。
至于为什么需要选择支持双向的Encoder,在这里引用作者原文的话:"The major limitation is that standard language models are unidirectional, and this limits the choice of architectures that can be used during pre-training. For example, in OpenAI GPT, the authors use a left-to-right architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer. Such restrictions are sub-optimal for sentence-level tasks and could be very harmful when applying finetuning-based approaches to token-level tasks such as question answering, where it is crucial to incorporate context from both directions."
大概的意思是:标准语言模型是单向的,这限制了在预训练期间可以使用的结构选择。例如,在 OpenAI GPT 中,作者使用从左到右的架构,其中在 Self-attention 中每个 token 只能访问先前的 token。这种限制对于句子级任务来说是次优的,并且在将基于微调的方法应用于 token-level 任务(如问题回答)时可能非常有害,因为在这些任务中,从两个方向结合上下文是至关重要的。
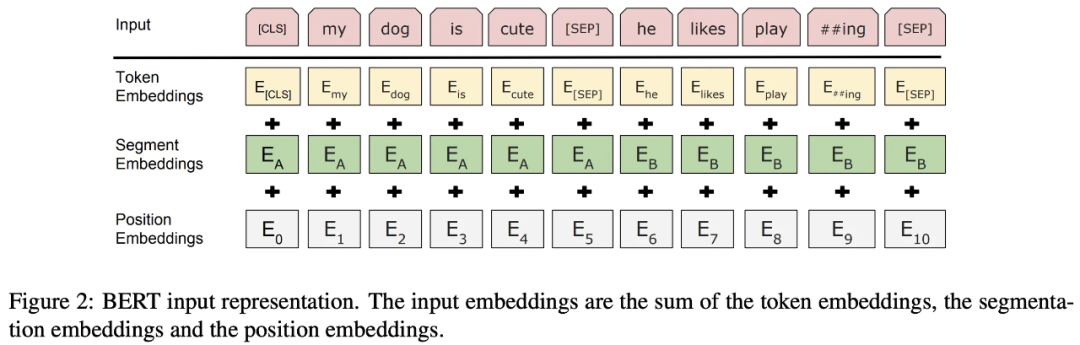
图七 BERT的输入层
为了使 BERT 能够处理不同的下游任务,对于每一个输入的 Sequence(在BERT的原文中,作者用" Sentence "表示任意跨度的连续文本,而不是语言意义上的句子;用" Sequence "表示输入 BERT 的 tokens 序列,可以是一个句子也可以是被打包在一起的两个句子),在其最前面拼接一个特殊的分类 token
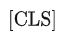
,
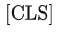
对应位置的最后一层的 Hidden state 将被用作分类任务的序列聚合表征。
对于被打包成一个 Sequence 的 Sentence pair, 通过两种机制来区分不同句子(a)用特殊token
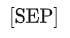
将两个句子分隔,(b)为每个 token 添加一个可学习的 Embedding(Segment Embedding),来指示其属于前句还是后句。如图七所示,对于每一个 token,其 Input representation 通过将其对应的 Token embedding、Position embedding 和 Segment embedding 求和得到。值得注意的是,特殊token
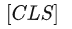
和
是在预训练的时候就引入了,并且参与预训练中的参数更新,而初代 GPT 的特殊 token 只有在 Fine-tuning 阶段才引入。
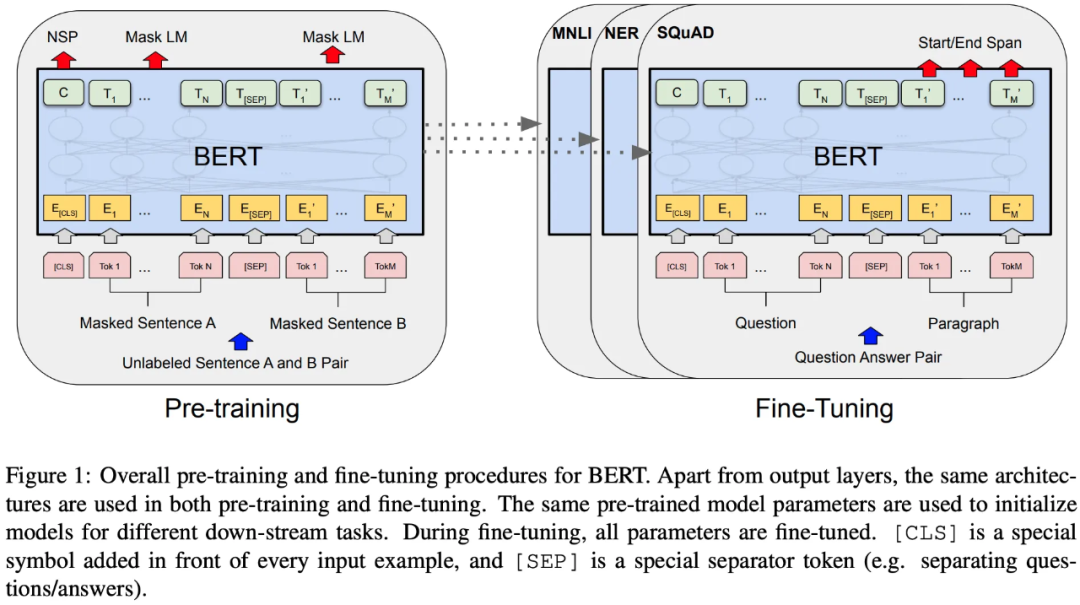
图八 Pre-traning和Fine-tuning过程
如图八所示。与初代 GPT 相同,BERT 也分为无监督 Pre-training 和有监督 Fine-tuning 两个阶段。
与 GPT 和其它预训练语言模型从左到右或是从右到左的标准预训练方式不同,BERT 提出了两个新的预训练任务:
Task-1 MASK LM | 作者在直觉上相信,双向模型比单项模型或是只在浅层拼接从左到右和从右到左的表征更强大。为此,作者提出随机遮蔽一定比例的 token,被遮蔽的 token 用代替,然后用未遮蔽的部分作为 context 预测遮蔽的部分。作者将其称为 MASK LM ,也被称为 Cloze task(完形填空)。在实际实现中,将被遮蔽的 token 在最后一层对应位置上的表征输入分类器;对于每一个句子,随机屏蔽 15% 的 token。尽管 MASK LM 能够得到双向的预训练 LM,然而 Pre-training 练阶段引入的特殊 token 不会在 Fine-tuning 阶段出现,这就产生了一个新的问题:Pre-training 和 Fine-tuning 输入 token 的不匹配。为了缓解这一问题, 对与15%被遮蔽的 token,不总是用替换,而是采用了如下策略:假设个 token 被选中遮蔽,其(a)有80%的概率用替换,(b)有10%的概率用随机 token 进行替换,(c)有10%的概率保持不变。 |
|---|---|
Task-2 Next Sentence Prediction (NSP) | QA 和 Natural Language Inference (NLI) 等许多重要的下游任务都是基于理解两个句子之间的关系,而语言建模并不能直接捕捉到这种关系。为了训练BERT能够理解句子的关系,作者提出一个预测下一句的二分类任务,这种任务很容易在任何语料中生成。对于 NSP 中的句子对儿(A,B),有 50% 的句子 B 在语料中是紧跟句子 A 的下一句,有50%的句子 B 是在语料中随机选择的。如图八所示,在最后一层输出的 Hidden state将被输入分类器预测 B 是否是 A 的下一句。 |
在Fine-tuning 阶段,将所有任务的输入构造成句子对(A,B)的形式。例如(a)Paraphrasing 中的句子对,(b)Entailment 中的 hypothesis-premise 对,(c)QA中的 question-passage 对和(d)文本分类和序列标注任务中的 text -
对。对于输出,在 token- level 的任务里,将所有 token 的对应位置最后一层的 hidden states 输入相应的输出层(例如序列标注和QA);在 sentence-level 的任务里,将
对应位置最后一层的 hidden state 输入到分类层进行分类(例如Entailment和Sentiment Analysis)。
无监督 Pre-training,来自 BooksCorpus 800M的words 和 English Wikipedia 2500M 的 words;有监督 Fine-tuning、GLUE Benchmark、 SQuAD v1.1和SQuAD v2.0共11个NLP 任务。
GLUE
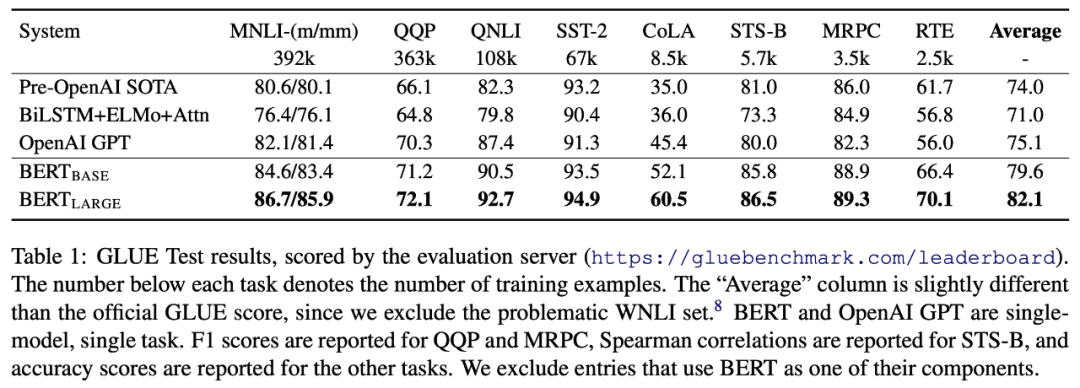
可以看到
与 OPENAI GPT 相比(二者模型结构上仅仅在Self-attention模块上是否有MASK机制存在差异),在每个任务上都有提升,平均提升 4.5%。
Ablation Study——Pre-training Task:
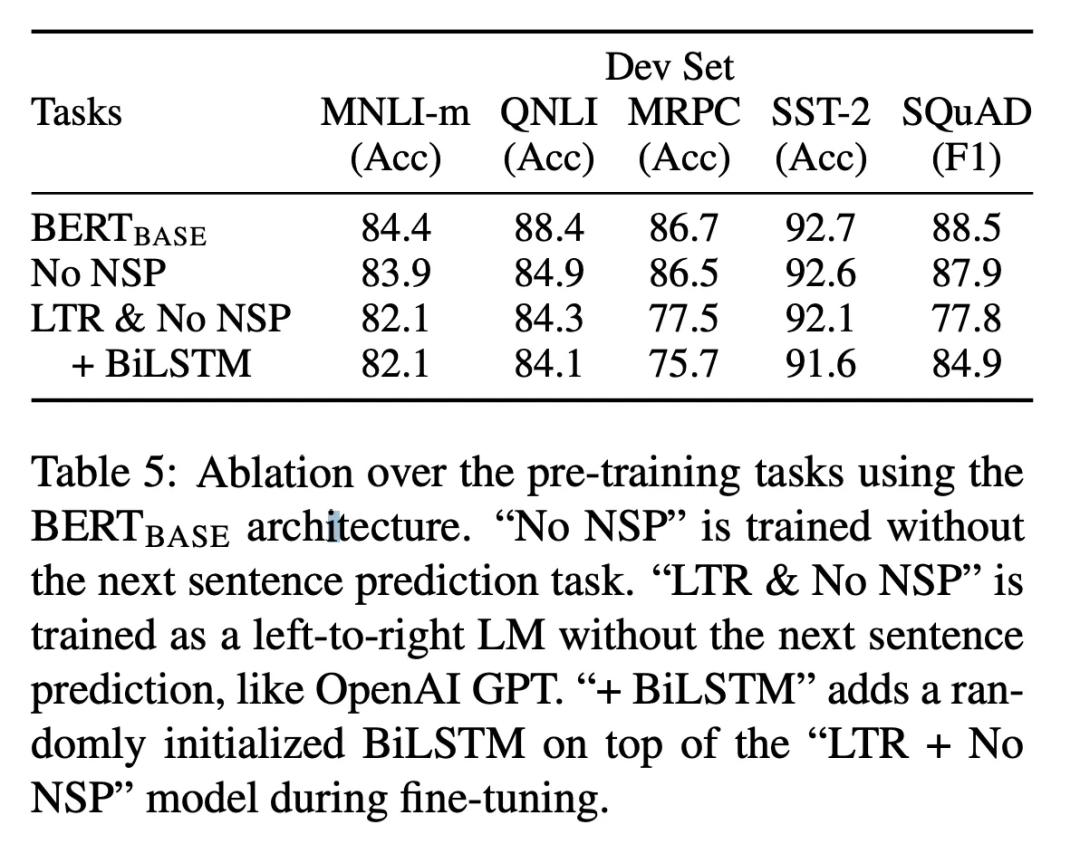
如上表所示。作者首先针对 Pre-training task 进行消融实验,以验证 MASK LM 和 NSP 任务的有效性。其中 LTR(Left to Right)表示类似 GPT 的从左到右的语言建模任务。+BiLSTM 表示在输出层前增加 BiLSTM 网络。从中可以看出 MASK LM 和 NSP 任务的有效性是显著的。
Ablation Study——Model Size:
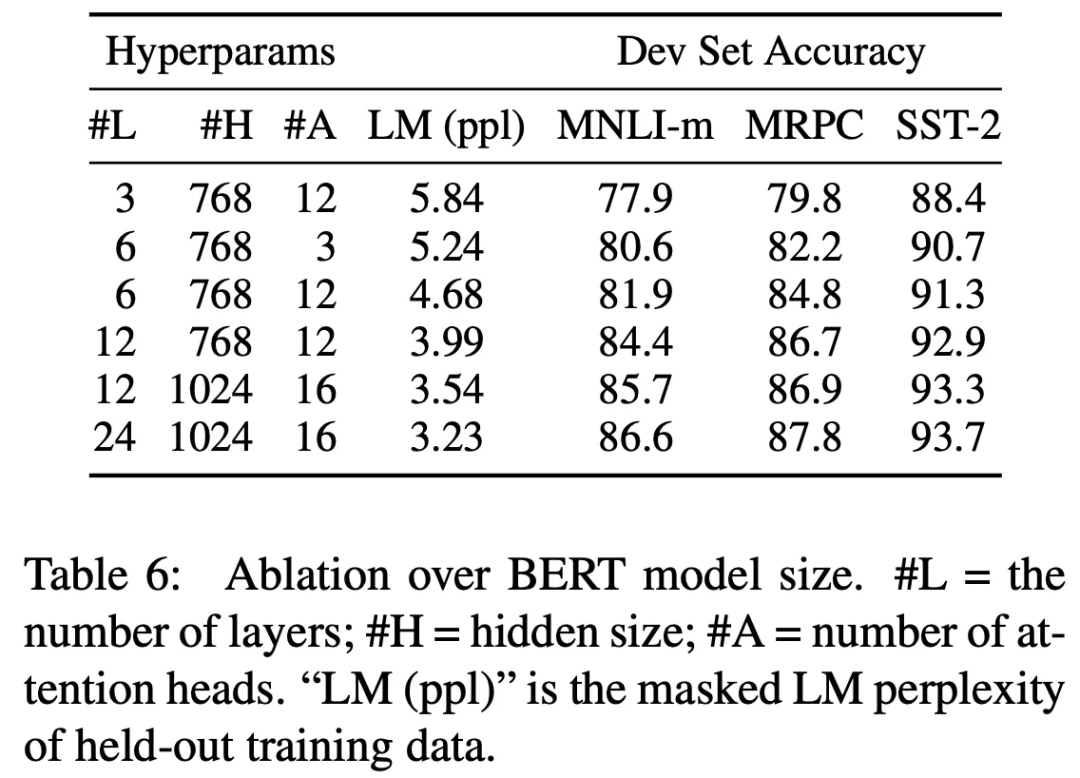
另外,作者针对模型参数量进行了消融实验。从上表可以看出,模型越大,在下游任务中的表现越好(这其实初步展示了大模型的潜力)。

本节会先介绍其原理(2.3.1),接着分享实现(2.3.2)、实验结果(2.3.3),最后得出小结(2.3.4)。
GPT-2的核心思想是:可以直接用无监督的 Pre-training 模型直接去做有监督任务。GPT-2在模型结构方面和GPT-1完全一致,Pre-training的任务也没有改变,那究竟是什么给 GPT-2 带来如此大的自信,可以让它在无监督 Pre-training 后直接用来做有监督任务呢?接下来,我将按照作者原文的思路,进行剖析。
传统Language Modeling(LM)也是GPT-2的中心思想(大道至简)。LM通常被构造为对来自一组样本
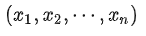
进行无监督分布估计,其中每个样本由长度可变的token序列
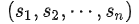
组成。由于language有自然的顺序性,因此通常将联合概率建模为:
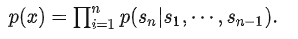
这种建模方式的缺点是:
(a)参数空间过大,但 Transformer 结构给大模型带来了光明;
(b)数据稀疏,但算力的提升以及资本的力量允许我们在超大规模语料上训练。
LM 其实也是在给序列的条件概率
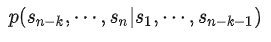
建模(有了 LM 的能力自然就有了对序列和序列间条件概率的建模能力)。
NLP 中对所有单个任务的建模都可以表达为
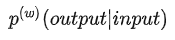
,那么一个通用的模型(指能够进行多种不同任务的模型),及时对于不同任务的输入相同,它也应该不仅 condition on input 还应该 condition on task 才能执行。而传统的多任务模型,需要对模型结构进行特殊的设计,比如针对不同任务添加任务特定编码器和解码器。但幸运的是,语言提供了一种灵活的方式来指定任务、输入和输出。
例如,一个翻译任务的样本可以被表达成 (translation to french, english text, french text) 的形式;一个阅读理解的样本可以被表达为 (answer the question , english text, french text)。由此可见,以这种数据格式可以有监督地训练 single model,其不需要特定任务的编码器或者解码器,就能执行多任务,
相比于有监督的多任务学习,LM 只是不需要显示地对哪些符号是输出进行监督。例如对于任意序列
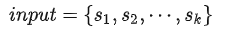
,通过 LM 都能推理新的序列
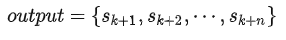
,而
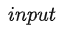
中所指定的任务的输出可能就出现在
中,但是 LM 的输出没有显示地对其进行监督。从这个意义上理解,多任务的有监督学习都是 LM 对序列建模的子集。例如,在 LM Pre-training 时,文本中有一句话,“The translation of word Machine Learning in chinese is 机器学习”,在训练完这句话后,LM就自然地将翻译任务的输入输出学到了。类似的例子如下表所示:

所以GPT-2是如何实现只进行无监督 Pre-training 就直接达到有监督多任务的效果呢?首先,子标题(1)中传统LM的两个缺陷(a)参数空间过大和(b)数据稀疏随着模型结构、算力提升以及资本的力量可以得到解决。换言之,LM的能力提升来自于大模型和在超大规模语料上预训练。
其次子标题(2)中的分析说明,LM 可以以其灵活的方式建模单模型多任务学习。
最后子标题(3)说明,有监督多任务学习是 LM 的子集。实际上有监督任务的监督信号是会出现在无监督任务的语料中的,只要语料足够大,那么就能 cover 到多个任务。综上可以得出结论,只要模型参数量足够大,预训练语料足够丰富,那么无监督 Pre-training 得到的 LM 就能直接拿来执行多任务。
GPT-2的模型结构相比GPT-1没有差别,仅仅是增加了参数规模。作者在实验中采用了四种规模参数的模型:

上表中第一个模型的参数规模与初代GPT相同,第二个模型的参数规模与BERT(Large)相同。而最后一行的模型是发布的GPT-2。
作者从网站上爬取了高质量的文本数据,形成的数据集被称为WebText。其中去掉了所有包含在Wikipedia中的文档。最终的数据集包含超过800万个文档,总共40 GB的文本。
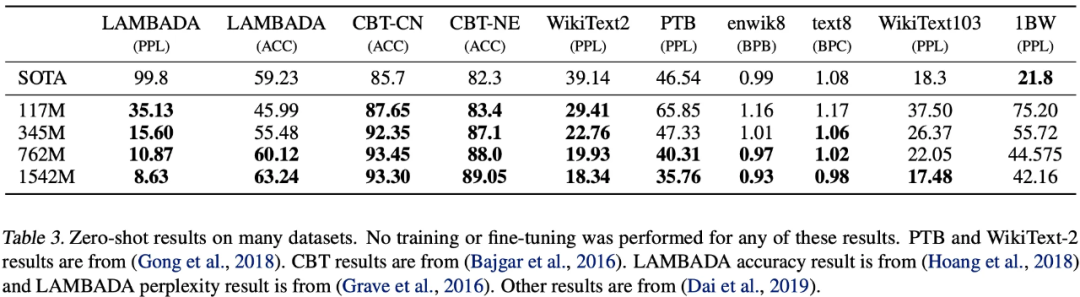
在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
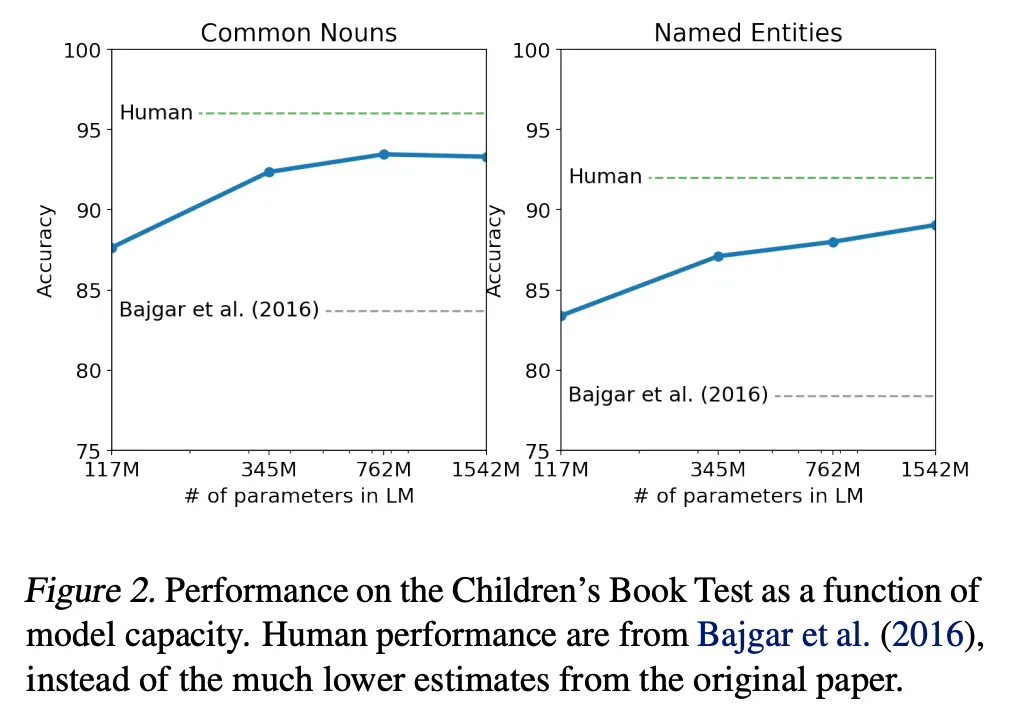
在Children's Book Test数据集上的命名实体识别任务中,GPT-2超过了SOTA的方法约7%。参数规模越大效果越好。LAMBADA数据集是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6。在阅读理解数据中,GPT-2超过了4个baseline模型中的三个。在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差。GPT-2在文本摘要上的表现不理想,但是它的效果也和有监督的模型非常接近。
GPT-2 验证了通过扩大参数规模和Pre-training语料的规模就可以迁移到多个任务且不需要额外的Fine-tuning。尽管其在有些任务上表现得不够好,但其已经初步展现了大模型大语料Zero-shot的潜力,未后续大模型的发展提供了有依据的方向。
本节会先介绍其原理(2.4.1),接着分享实现(2.4.2)、实验结果(2.4.3),最后得出小结(2.4.4)。
GPT-3的核心卖点是:仅仅需要zero-shot或者few-shot就能在下游不同任务上表现得很好,并且在很多非常困难的任务上也有惊艳的表现。
到GPT-3之前,LM 已经取得了巨大的成功,例如初代 GPT、BERT 的 Pre-training + Fine-tuning, 以及 GPT-2 所展现的 Zero-shot 能力。但是,当模型结构是 task-agnostic 的时候,前述 LMs 仍然需要特定任务的数据集和特定任务的 Fine-tuning(即便强大如GPT-2在某些任务上也需要Fine-tuning )。这是在 GPT-3 之前 LMs 最大的缺点(尽管已经很强了,但是目标要大一点)。解决这一缺陷的必要性如下:
从实用角度来看,对于每一项新任务都需要一个有标注的大数据集,这限制了语言模型的适用性(尽管在我们看来,标注数据是不可避免的,但GPT-3团队的目标很大)。更糟糕的是,对于很多应用前景很广泛的任务,例如语法纠错、生成抽象概念的示例、评论story,很难收集一个大型的监督训练数据集,特别是当每个任务都要重复这样的步骤。
在有标注数据上 Fine-tuning 得到的大模型其在 Out-of-distribution(OOD)数据上泛化性不一定更好, 因为模型过度偏向fine-tuning数据分布(回想下初代 GPT 为什么要在 Fine-tuning 阶段加入 Pre-training LM的损失)。因此,Fine-tuning 模型在特定 Benchmark上的性能,即使名义上是人类水平,也可能是被夸大了实际性能。
对于人类这个智能体而言,其不需要大量的有监督的数据集去学习绝大多数 NLP 任务。简短的几个示例足以使人类以合理的能力执行新任务。如果 LM 能到达类似的能力,那么将会极大地增加其通用性。
作者认为,解决该缺陷的主要思路是:
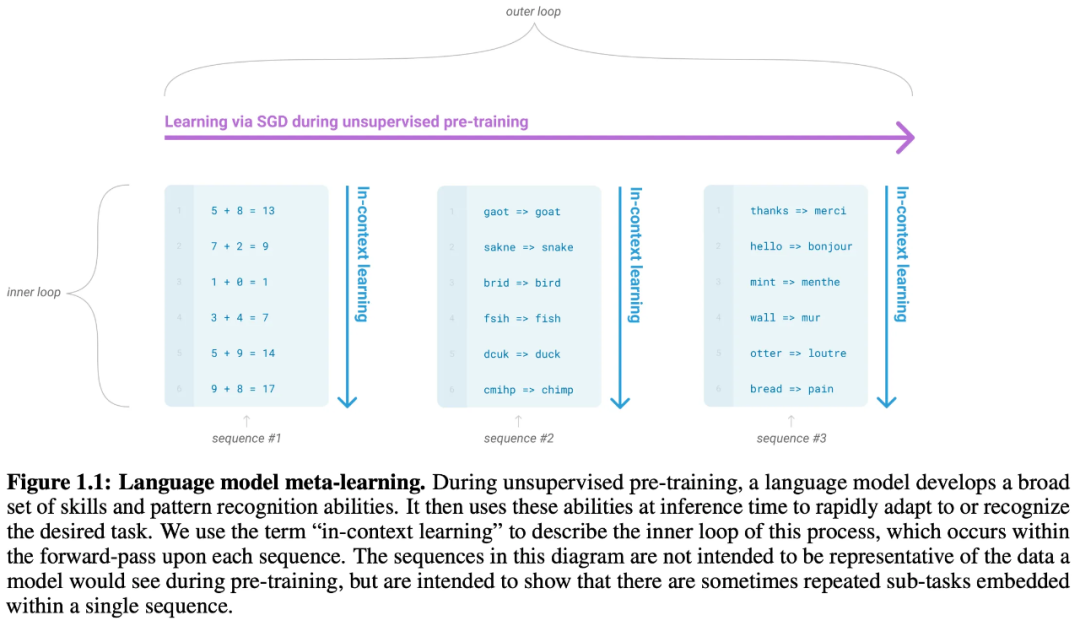
借用 meta-learning(元学习)的思想。这在 LM 背景下的含义是:在 Pre-training 期间让模型学习广泛的技能和模式识别能力,而在推理期间利用这些技能和能力迅速适配到期望的任务上。如下图所示:
以 MAML 算法为例,meta-learning 的目的是找到模型
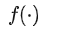
的参数
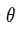
的最优初始化值 meta-initialization , 使模型能从 meta-initialization 开始迅速应用到其它任务中。其优化过程分为内循环(inner loop)和外循环(outer loop),其中内循环(inner loop)是针对子任务进行学习,而外循环(outer loop)是对 meta-initialization 进行更新。换言之,如果找到一组参数 meta-initialization , 从它开始来学习多个任务,如果每个任务都能学好,那么它就是一组不错的初始化参数,否则就对其进行更新。而LM与 meta-learning 相似,其内循环就是对大语料中包含的多个子任务(回顾GPT-2)中的每一个进行学习(即语言建模),作者将其称为 In-context learning , 而外循环则是对整个语料的建模,即语料中包含多个子任务,模型在整个大语料上一直以语言建模的目标进行优化其实就是在找 meta-initialization 。而GPT-2其实也在尝试 In-context learning,其使用 Pre-training LM 的输入作为任务规范的一种形式,模型以自然语言指令或任务演示示例为条件,然后通过预测一下步将发生什么来完成任务的更多示例。并且 GPT-2 已经展示了 In-context learning 的一些能力,证明了这是一个有希望的方向。GPT-2 在一些任务上的能力还远不及 Fine-tuning 。
另一个方向是扩大模型参数量的规模,从初代 GPT 到 BERT,再到 GPT-2 ,这一趋势证明随着模型参数量的扩大,模型的能力也随之提高。由于 In-context learning 涉及从大规模语料中将许多技能和任务吸收到模型参数中,因此 In-context learning 的能力可能会随着规模的扩大而表现出类似的强劲增长。笔者认为:
(a)小规模语料是有偏的,且其中包含的任务和每个任务的样本量少,不足以学到足够的“技能”和“任务”,即在预训练中无法得到足够多的知识泛化到实际场景中的任务;
(b)因此需要扩大语料的规模,而扩大语料中的规模需要有足够多的参数来记住语言建模中学到的“技能”和“任务”,如果参数量不够,那么随着 Pre-training 的进行,模型又要尝试记住所有“技能”和“任务”,但又无法完全记住,因此可能会对找到 meta-initialization 带来困难;
(c)另外,可以回到第 2.3.1 GPT-2 原理那节从解决 LM 缺陷的角度思考。
上述第一点从 Meta-learning 的角度揭示了 LM 的背后的机理,以及背后 In-context learning 的概念,并以GPT-2所展现的能力来证明 In-context learning 的有效性;第二点说明近些年来提升参数规模所带来的提升是大势所趋。因此,GPT-3所带来的改进有两点:继续扩大参数规模;继续扩大语料的规模;想到那句话:重剑无锋,大巧不工。
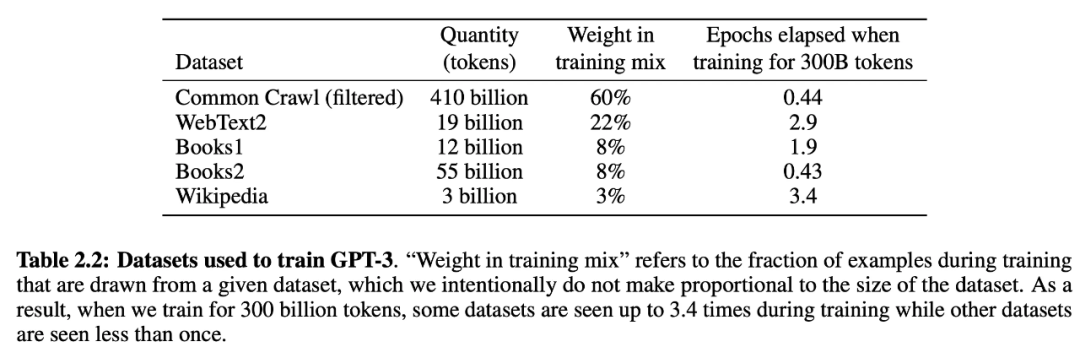
GPT-3共训练了5个不同的语料,分别是低质量的 Common Crawl,高质量的WebText2,Books1,Books2 和 Wikipedia,GPT-3 根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到。整个语料的规模为 45TB,数据集统计如下表所示:
GPT-3 的模型结构和初代 GPT 和 GPT-2 相同,但参数量直接提升至 175 Billion(初代目:1.17亿;二代目15.42亿;三代目:1750亿)。
LM Pre-training

如上图所示,与传统的 Pre-training + Fine-tuning 不同(图右),GPT-3(图左)Pre-training 之后直接进行推理,且支持三种推理方式,即 Zero-shot,One-shot 和Few-shot。三种推理方式具体如下:Zero-shot只输入任务描述和提示词(Prompt);One-shot输入任务描述,1 个示例和 Prompt;Few-shot 输入任务描述,K
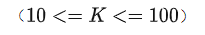
个示例和 Prompt。

作者在一个简单的任务上(去掉单词中被随机添加的符号,例 s.u!c/c!e.s s i/o/n = succession)对比了不同参数规模的模型和在推理时是否有Prompt的结果。可以得出的结论有三个:
(a)扩大参数规模有助于提升模型利用 In-context Information 的能力;
(b)Prompt有助于提升模型学习任务的能力;
(c)Few-shot > One-shot > Zero-shot。
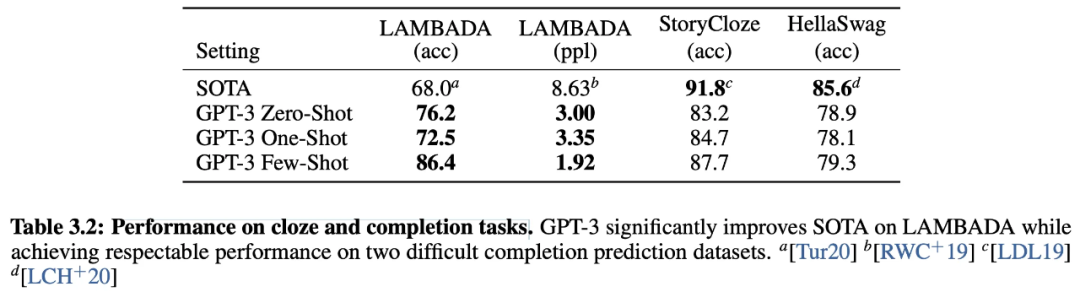
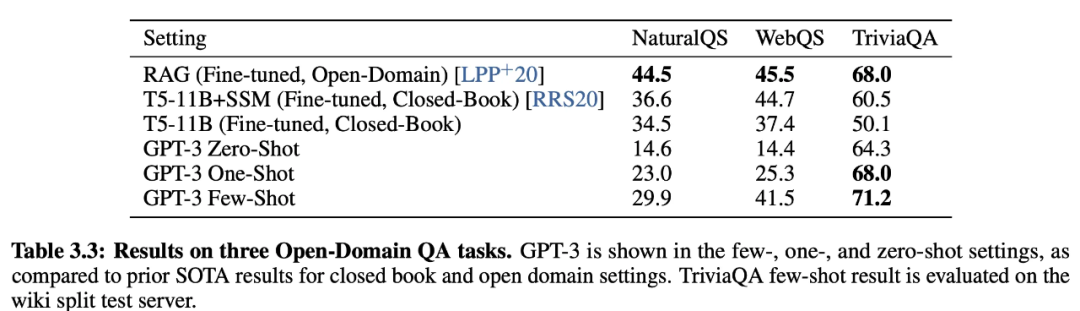
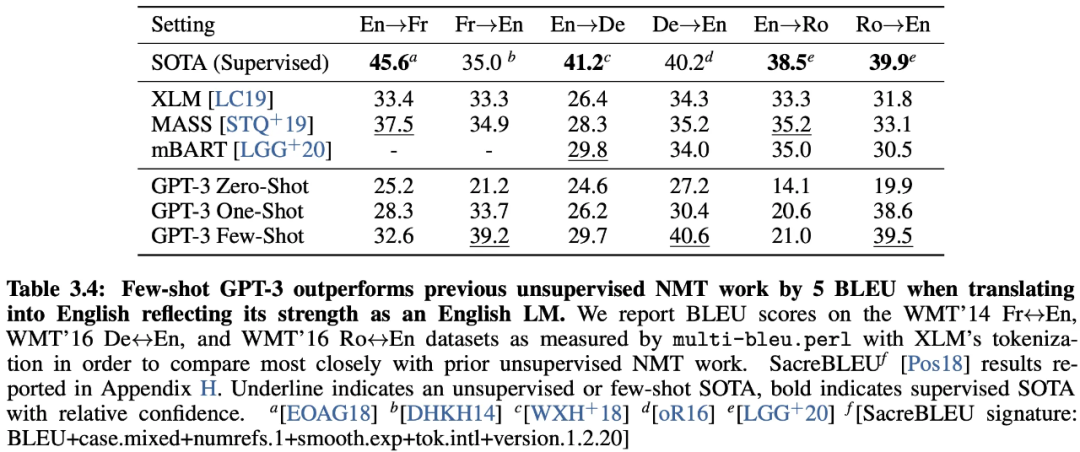
在 GPT-3 的年代,其表现也可以用惊艳来形容。它在大多数 LM 数据集中,超过了绝大多数的 Zero-shot 或者 Few-shot 的 SOTA 方法。此外,在许多复杂的 NLP 任务中也超过了 Fine-tuning 后的 SOTA 方法,例如闭卷问答、模式解析、机器翻译等。最后,它在一些其他的任务上也取得非常震惊的效果,如进行数学加法、文章生成、编写代码等。
然而 GPT-3 也存在一系列的问题,比如对于一些命题没有意义的问题,GPT-3 不会判断命题有效与否,而是推理一个没有意义的答案出来。由于 45TB 海量数据中没有针对种族歧视、性别歧视、宗教偏见等内容进行排除,因此 GPT-3 生成的文章会包含这类敏感内容。
初代GPT | GPT-2 | GPT-3 | |
|---|---|---|---|
时间 | 2018年6月 | 2019年2月 | 2020年5月 |
参数量 | 1.17亿 | 15.4亿 | 1750亿 |
预训练数据量 | 5GB | 40GB | 45TB |
训练方式 | Pre-training + Fine-tuning | Pre-training | Pre-training |
序列长度 | 512 | 1024 | 2048 |
# of Decoder Layers | 12 | 48 | 96 |
Size of Hidden Layers | 768 | 1600 | 12288 |
InstructGPT 是为解决 LM 有时不能遵循用户意图而诞生的。“不能遵循用户意图”表示LM 可能会生成不真实、有毒或对用户毫无帮助的输出。主要原因是 LM 的训练目标是预测下一个 token 而不是有帮助地和安全地遵循用户的指令。换句话说,这些模型与其用户没有对齐。这是由于模型的偏见性和数据中存在的一些有毒内容导致模型会输出无用的、有毒的输出(LM并没有对输出是否无用、是否有毒的监督)。因此,InstructGPT 要做的就是是模型的输出符合人类的意图。这种改进是十分有必要的,尤其是当 LM 被部署在多个应用场景中时。具体而言,InstructGPT 的优化目标有三个(3H):
为了解决上述问题,Fine-tuning 步骤又回到了 InstructGPT,但与传统的 Fine-tuning 不同。在具体介绍 InstructGPT 之前,本章将先介绍几个 Preliminary knowledge,分别是 Instruct Learning 和 Prompt Learning,Deep Reinforcement Learning from Human Preferences (RLHF) 和 PPO 算法。
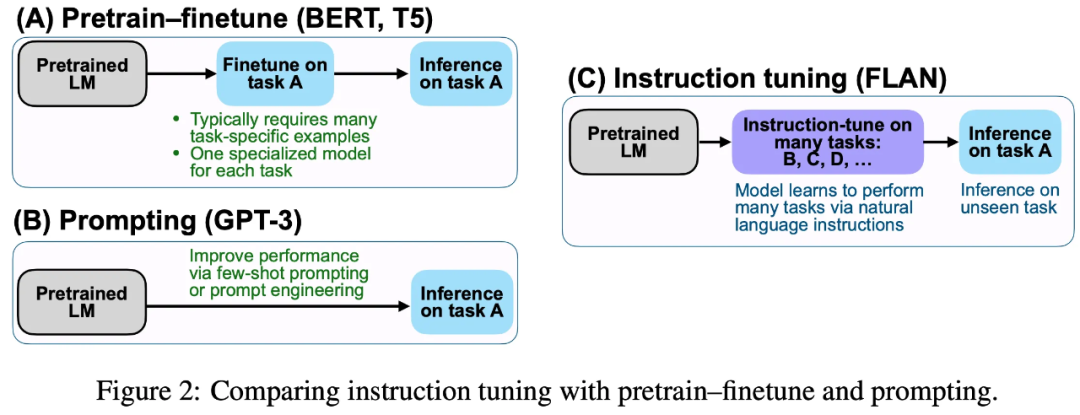
Instruct Learning 是由 Google 提出。(接下来引自外部解读)Instruct Learning 和 Prompt Learning 的目的都是去深入挖掘已经具备的知识(回顾GPT-2和GPT-3在大规模语料中学到的“技能”和“任务”),并激发出更强的能力。不同的是,Prompt 是激发LM 的补全能力,例如根据上半句生成下半句,或者是 Cloze;而 Instruct Learning 是激发语言模型的理解力,通过给出明显的指令,让模型去做出正确的行动。通过如下例子来理解两种学习方式:
Instruct Learning 原文对传统Fine-tuning、Prompt Learning和Instruction tuning的对比:
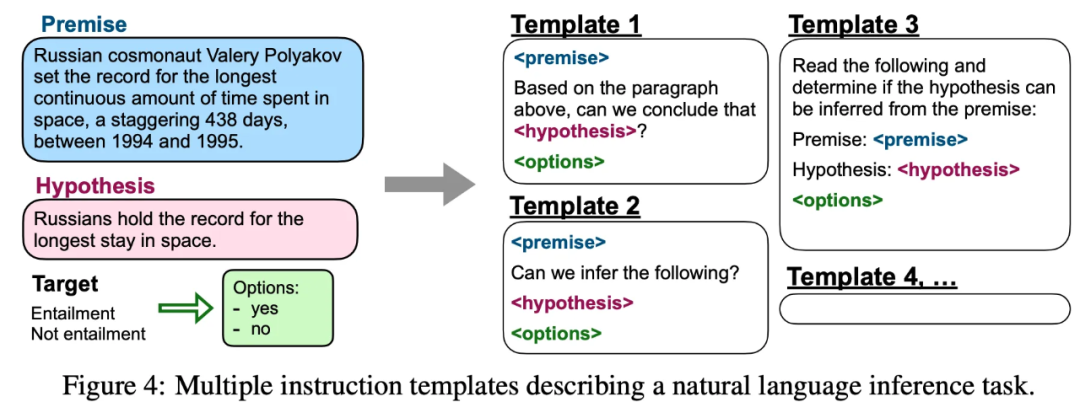
Instruct-tuning 的一些模版,如下图:
Instruct-tuning 的 Zero-shot 效果如下图所示:
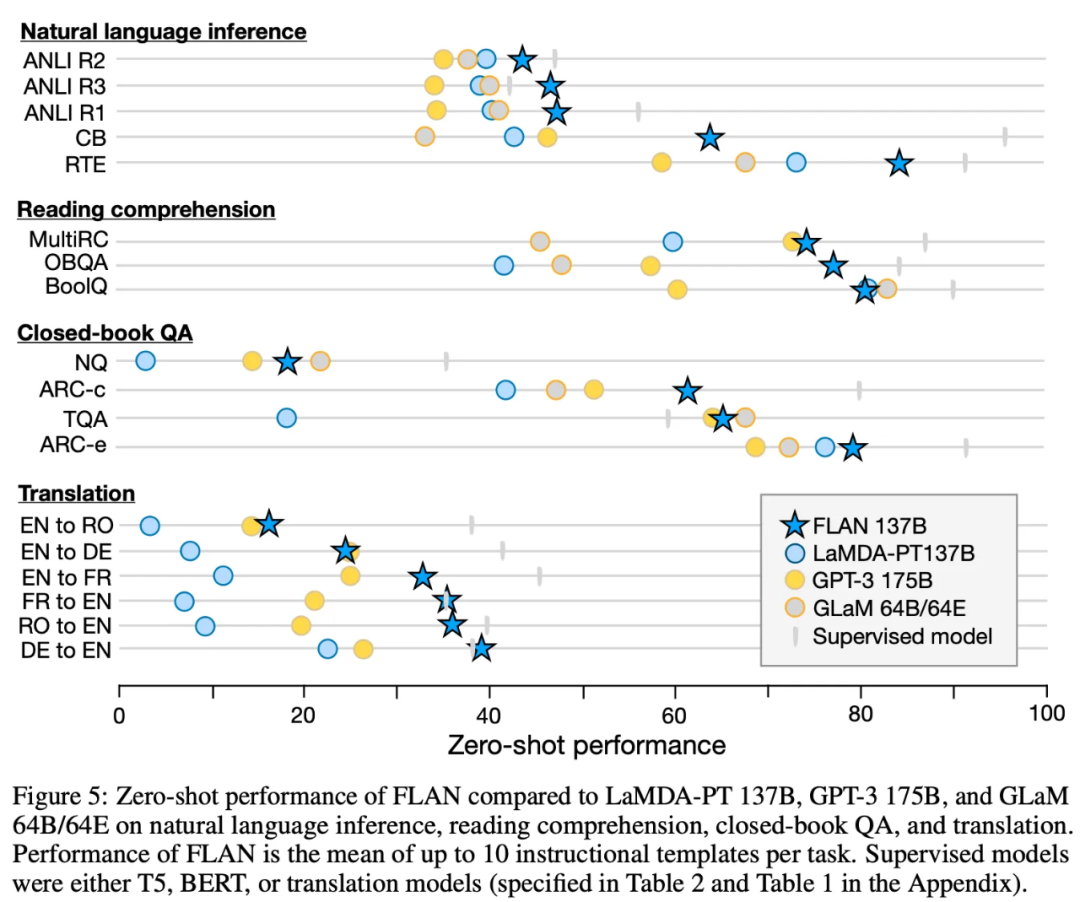
从实验效果来看,1370亿参数的 FLAN(Pre-training + instruction tuning)比 1750亿参数的 GPT-3 在各个任务上效果要好,甚至在某些任务上(Translation)比全监督的算法要好,体现了 Instruction tuning 在激发/激活 LM 潜力方面和泛化能力的优越表现。
个人认为,Instruction learning 能够进一步将任务编码到模型参数中,在 inference 的时候,模型能够根据Instruction 中的任务描述,输出与任务相关的结果。其实 LM 本身是生成式模型, Prompt Learning 其实是通过使模型在生成答案的时候 condition on Prompt 来区分任务,本质上还是强化了模型的补全能力,而 Instruction learning使模型condition on 对任务更丰富的描述,从而加强对任务的理解。
如介绍 GPT-3 时提到的,45TB 的语料中不能保证没出现敏感的句子,如种族歧视、辱骂等。而 LM 实际上是对训练数据集分布的拟合。这实际上直接影响了 LM 在内容生成上的质量。此外,我们不希望模型只受到数据的影响,我们希望输出结果是可控的,要保证生成的内容是有用的,真实的,和无害的。所以,我们应该有一个机制,来鼓励模型输出和人类偏好一致的结果,比如避免输出带有种族歧视、辱骂的语句;再比如生成的内容要有具有流畅性和语法正确性;生产的内容还需要是有用的、真实的。
因此, RLHF 就是通过用人类的偏好(人工标注输出的质量分数)训练一个奖励模型(Reward model), 来指导 LM 的训练。RLHF 的流程如下图所示。
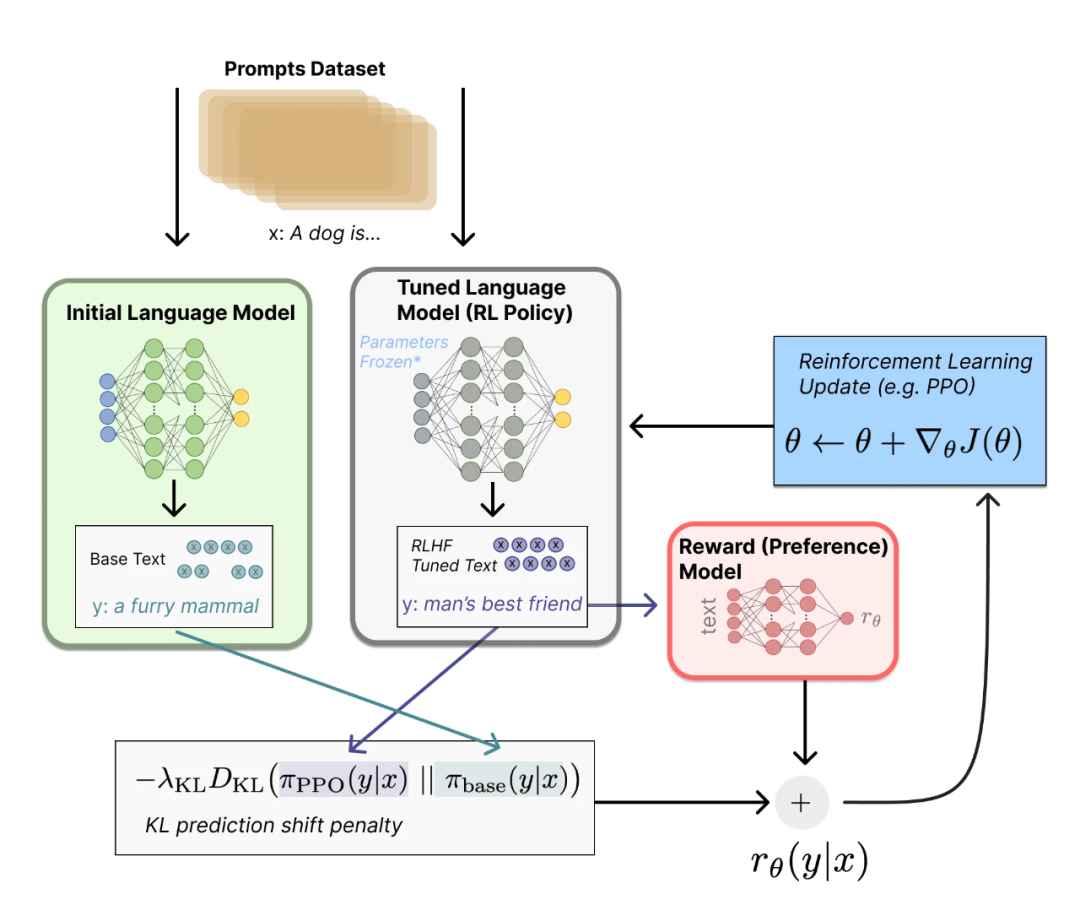
上图中的一些概念:
Initial Language Model:Pre-trianing 或者 Instruct tuning 后的模型;
Tuned Language Model:Initial Lanugage Model 的副本,将在 RLHF 中更新参数,也是RL中的Policy;
Policy:是给Tuned LM(例如GPT-3)输入文本后输出结果的过程;
Action Space:全词表,大约 50K;
Observation Space:输入的文本序列空间;
Reward Function:一个打分模型 Reward Model,和一个 KL 的梯度惩罚项
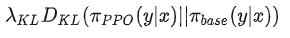
,目的是为了使Policy的输出文本不要和 Initial LM 差太多,防止模型为了迎合 Reward 模型输出不连贯的文本或着胡言乱语。
RLHF 首先人工收集LM的输出答案,并对输入输出对进行打分标注来训练 Reward Model ; 然后,在RLHF期间,将 Prompts Dataset 中的每一个样本分别输入到 Initial LM 和 Policy 中,得到两个输出
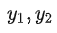
,将
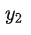
输入到 Reward Model 中得到评分
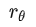
,然后加上梯度惩罚项避免 Policy 的输出与Initial LM 的差距太大。因此,得到 Reward Function的输出结果
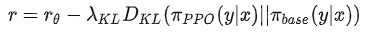
。然后根据
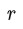
利用 Update rule,即 PPO 算法更新 Policy 的参数
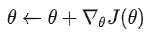
,在 InstructGPT 中,update rule 还包括原始 LM 的目标。
RL实际上就是 Agent 在一个状态 s 下选择下一个动作a, 获得奖惩r,而我们的优化目标是希望选择动作的 Policy 使得总体收益期望最大。对于一组模型参数 θ 可以得到一组轨迹序列的概率分布
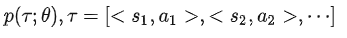
(想象一下GPT答案的生产过程)。对于一条轨迹 r,可以得到 Reward 的期望为
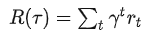
,其中
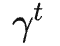
是权重因子,例如远期奖励不重要,
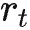
是相应时间步的 Reward 。PPO 的目标是最大化 Reward 的期望,因此可得目标函数为:
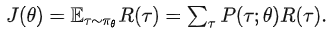
最大化上述目标则采用梯度上升:
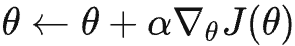
求解上述梯度
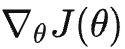
:
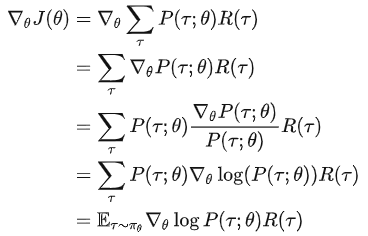
在 InstructGPT 中,上式中的
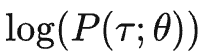
对应输入序列 x 后输出序列 y 的概率。
在了解了 Instruct learning、RLHF 和 PPO 后,我们就不难理解 InstructGPT 的实现过程(下图)。
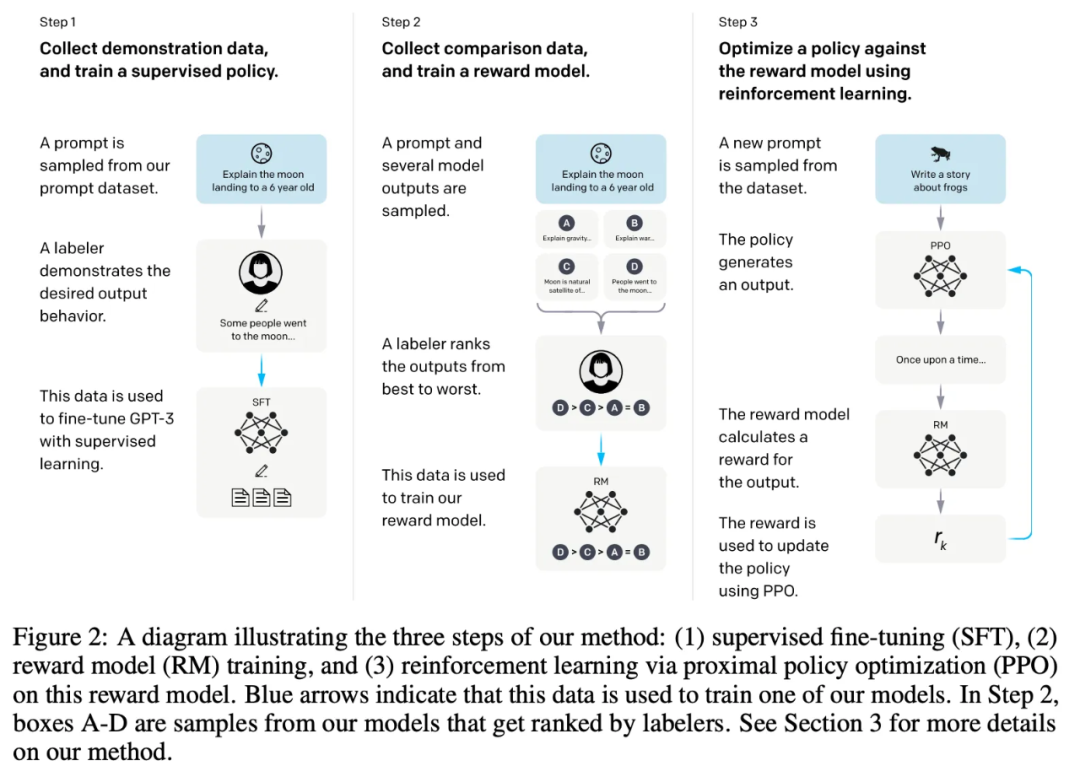
如上图所示,InstructGPT 的训练分成3步,每一步的数据也有差异,下面我们分别介绍它们。
SFT数据集是用来训练第1步有监督的模型。在这一步中将使用采集的新数据,按照GPT-3 的训练方式对 GPT-3 进行微调。因为 GPT-3 是一个基于提示学习的生成模型,因此 SFT 数据集也是由提示-答复对组成的样本。SFT数据一部分来自使用 OpenAI 的的用户,另一部分来自 OpenAI 雇佣的40名标注人员。所有的标注人员都经过了仔细的培训。标注人员在构造这个数据集中的工作是根据内容自己编写指令。
RM数据集用来训练第2步的奖励模型,我们也需要为 InstructGPT 训练设置一个奖励目标。这个奖励目标不必可导,但是一定要尽可能全面且真实的对齐我们需要模型生成的内容。很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT先让模型生成一批候选文本,让后通过标注人员根据生成数据的质量对这些生成内容进行排序。
训练步骤如下:
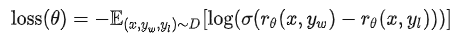
,其中
是标注人员更偏好的输出;
与 GPT-3 的输出相比,标注人员明显更喜欢 InstructGPT 输出。13亿参数的InstructGPT 的输出明显优于1750亿参数的GPT-3。1750亿参数的InstructGPT 的输出在 85±3% 的时间内优于 1750亿参数的GPT-3 输出,在 71±4% 的时间内优于 few-shot 1750亿参数的GPT-3。InstructGPT 模型能更可靠地遵循指令中的明确约束。
InstructGPT 模型在真实性方面比 GPT-3 有所改进。在 TruthfulQA 基准测试中,InstructGPT 生成真实且信息丰富的答案的频率大约是 GPT-3 的两倍。
InstructGPT 与 GPT-3 相比毒性略有改善。InstructGPT 模型显示了 RLHF 微调对分布之外的指令的有前景的泛化。作者定性地探究了 InstructGPT 的功能,发现它能够遵循指令来总结代码,回答有关代码的问题,有时还会遵循不同语言的指令,尽管这些指令在微调分布中非常罕见。相比之下,GPT-3 可以执行这些任务,但需要更仔细的prompt,并且通常不会遵循这些领域的说明。这个结果表明,InstructGPT 能够泛化到“遵循指令”的概念。即使在获得很少直接监督信号的任务上,也会保持一定的对齐。
InstructGPT会降低模型在通用 NLP 任务上的效果,作者在PPO的训练的时候讨论了这点,虽然修改损失函数可以缓和,但这个问题并没有得到彻底解决。
有时候InstructGPT 还会给出一些荒谬的输出:虽然 InstructGPT 使用了人类反馈,但限于人力资源有限。影响模型效果最大的还是有监督的语言模型任务,人类只是起到了纠正作用。所以很有可能受限于纠正数据的有限,或是有监督任务的误导(只考虑模型的输出,没考虑人类想要什么),导致它生成内容的不真实。就像一个学生,虽然有老师对他指导,但也不能确定学生可以学会所有知识点。
尽管取得了重大进展,但 InstructGPT 模型远未完全对齐或完全安全;它仍然会在没有明确提示的情况下生成有毒或有偏见的输出、编造事实以及生成色情和暴力内容。但机器学习系统的安全性不仅取决于底层模型的行为,还取决于这些模型的部署方式。为了支持 API 的安全,OpenAI 提供内容过滤器以检测不安全的回答,并监控滥用情况。
在2.6.1,我们会先介绍ChatGPT的实现,然后在2.6.2节补充分享GPT系列的其它成员。之后在章节2.6.3 ,我们对前面的所有分享进行初步回顾——从初代 GPT 到 ChatGPT 的进化。最后,在章节2.6.4聊聊开发者们感兴趣的ChatGPT 缺陷。
终于可以聊ChatGPT 了。ChatGPT 基本遵循了与 InstructGPT 相同的训练方式,有差异的地方只有两点:
在此,我将 Blog 中的原文翻译后引用在此:
“我们使用来自人类反馈的强化学习(RLHF)来训练这个模型,使用与InstructionGPT 相同的方法,但数据收集设置略有不同。我们使用有监督的微调训练了一个初始模型:人工智能训练师提供对话,他们扮演用户和人工智能助手的双方角色。我们让训练师获得模型书面建议,以帮助他们撰写回复。我们将这个新的对话数据集与 InstructGPT 数据集混合,并将其转换为对话格式。
为了创建强化学习的奖励模型,我们需要收集比较数据,其中包括两个或多个按质量排序的模型响应。为了收集这些数据,我们进行了 AI 训练师与聊天机器人的对话。我们随机选择了一个模型撰写的消息,抽样了几个备选的答案,并让 AI 培训师对其进行排名。使用这些奖励模型,我们可以使用近端策略优化对模型进行微调。我们对这个过程进行了多次迭代。ChatGPT从 GPT-3.5 系列中的一个模型进行了微调,该系列于 2022 年初完成了训练。ChatGPT 和 GPT 3.5 在 Azure AI 超级计算基础设施上进行了训练。”
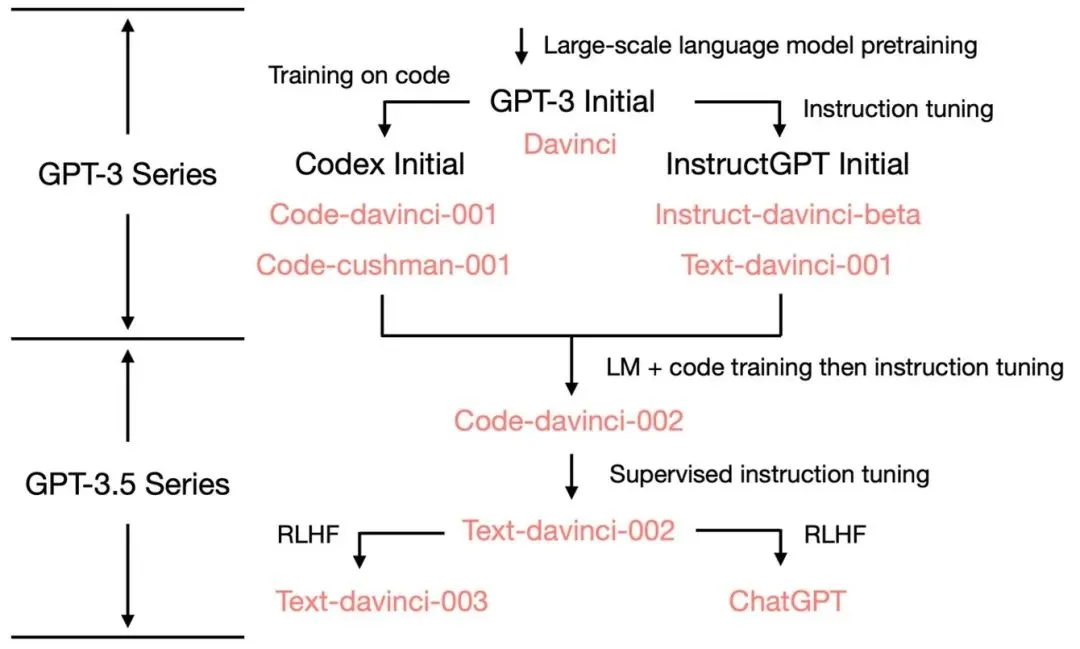
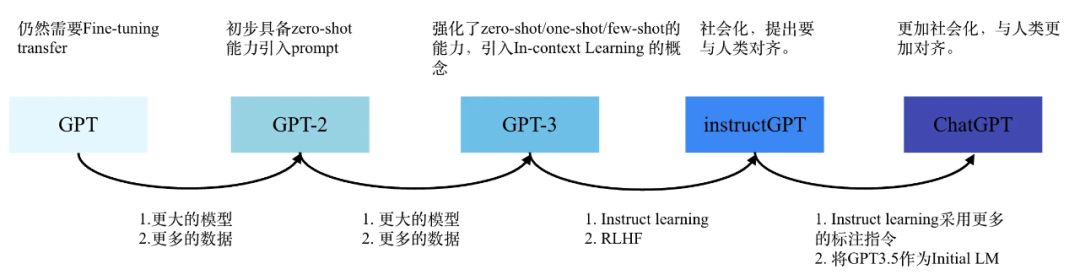
网上某 Blog 中总结了从 GPT-3 衍生的 GPT 家族的其它成员,文中还全面客观地总结和剖析了 ChatGPT 的各项能力来源。如下图所示,作为 ChatGPT Initial LM 的 GPT-3.5是在原始 GPT-3 的基础上,增加 code 语料和经过 instruct tuning 后得到的。
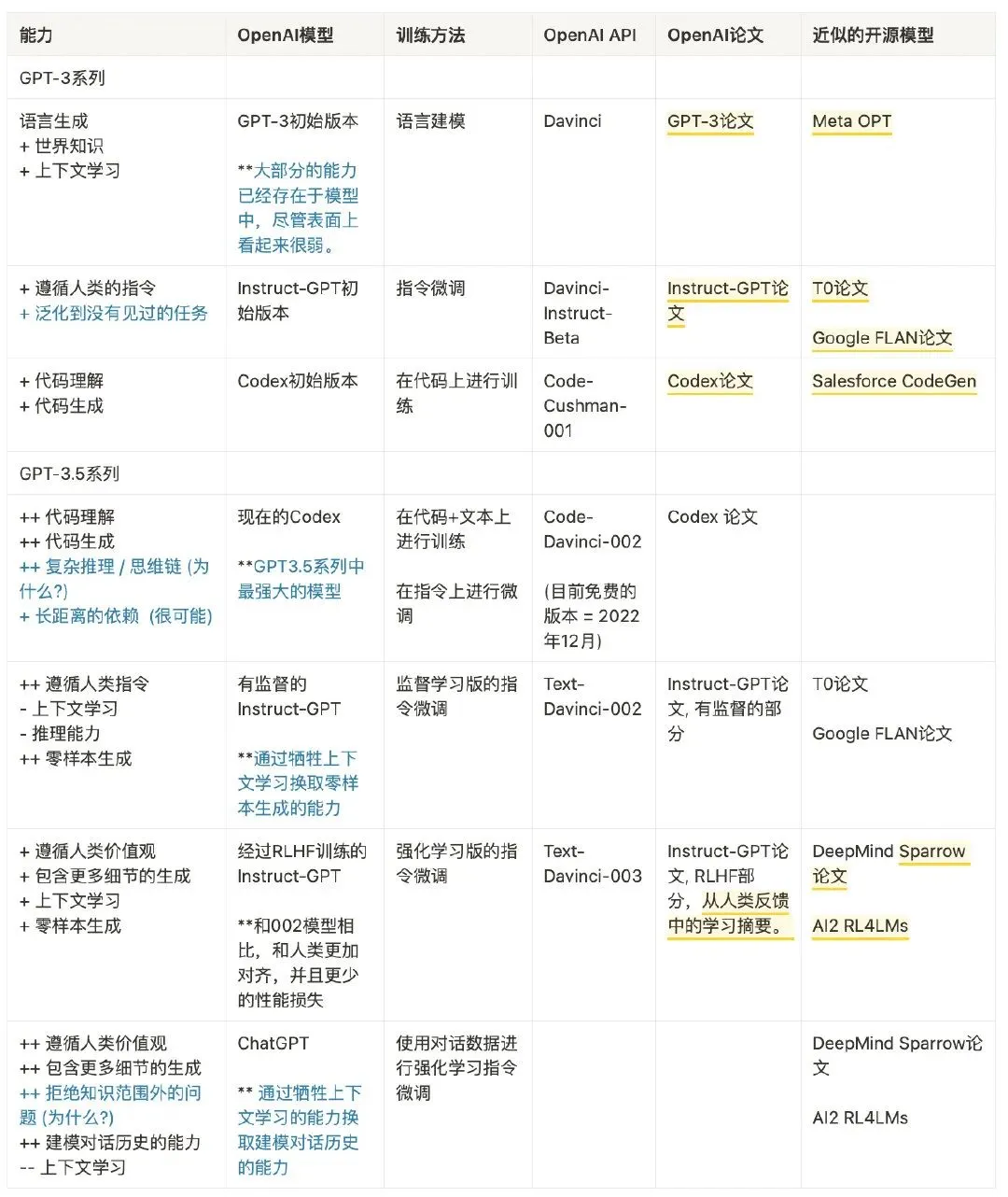
该 Blog 中还整理了 GPT-3 到 ChatGPT 以及这之间的迭代版本的能力和训练方法,如下图:
来自 ChatGPT 官方给出的缺陷:
网友给出的缺陷例子基本被包含在官方给出的5个方面的缺陷中。上面1所说的缺点就是网友们吐槽的“一本正经说瞎话”。比如用户给 ChatGPT 一个 Prompt:“宫廷玉液酒”,ChatGPT 会给出如下回答:“宫廷玉液酒是一种传统的中国白酒。它通常是由大米、小麦...”。然而我国根本没有宫廷玉液酒这种酒。再比如问 ChatGPT:“秦始皇摸电线会怎么样”,ChatGPT 给出的回答里竟然包含这样一句话:“电线是由英国科学家艾伦图灵在1870年代发明的”。这明显说明 ChatGPT 不是一个完全可靠的知识库。
第二点提到训练模型更加谨慎会导致它拒绝正确回答的问题,身边同事确实遇到过这类案例。比如让 ChatGPT 推荐书籍,有时会拒绝回答但有时会回答。这可能也和第2条缺陷相关。
第三点的含义可能是 RLHF 和 Instruct Learning 限制了模型可能的输出范围,而使模型小心地输出与人类尽可能对齐的答案。而与人类对齐的能力来自于人类制作的数据集和人类标注训练的 Reward Model,其实这种方式本身就是有偏的。并且模型可能会因此不敢回答从海量语料中学到的知识。缺陷3现象很普遍,作者的解释也很明确;缺陷4的原因应该是 ChatGPT 没有认知能力,这一点将在3.1.4中讨论。
缺陷五,个人认为虽然 GPT 系列通过大模型、大语料上的 LM 在不断提高下游任务的泛化性,但目前仍然无法保证 RLHF 中 Reward 模型的泛化性。
