

前段时间,基于“类付款码”的原理,通过手机二维码+人脸设备摄像头实现了IoT设备通信互联,有感兴趣的小伙伴可以私我交流一下,其中涉及了一些二维码的基础知识和底层原理,我们一起来看一下~
二维码又称二维条码,常见的二维码为QR Code(QR全称Quick Response),是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据类型。
二维条码/二维码(2-dimensional bar code)是用某种特定的几何图形按一定规律在平面(二维方向上)分布的、黑白相间的、记录数据符号信息的图形;在代码编制上巧妙地利用构成计算机内部逻辑基础的“0”、“1”比特流的概念,使用若干个与二进制相对应的几何形体来表示文字数值信息,通过图象输入设备或光电扫描设备自动识读以实现信息自动处理:它具有条码技术的一些共性:每种码制有其特定的字符集;每个字符占有一定的宽度;具有一定的校验功能等。同时还具有对不同行的信息自动识别功能、及处理图形旋转变化点。(信息来源于百科词条)
最初在1994年由日本DENSO WAVE公司腾弘原团队发明,后来DENSO WAVE 公司宣布,不行使本公司就标准QR码拥有的专利权(专利第2938338号),目前,QR码已经在国家标准和国际标准中实现标准化,任何人都可以随意查看该标准。
条形码或称条码(英语:barcode):是将宽度不等的多个黑条和空白,按照一定的编码规则排列,用以表达一组信息的图形标识符。常见的条形码是由反射率相差很大的黑条(简称条)和白条(简称空)排成的平行线图案。
进入上个世纪60年代之后,日本迎来的高速增长期,经销食品、衣料等种类繁多的商品的超市开始在城市中出现。
为了解决很多场景需要手动录入繁杂工作负担,条形码(一维码)运营而生,通过光感读取条形码,名称、价格等信息可以直接显示在出纳机(计算机)上,后被广泛应用于商业、邮政、图书管理、仓储、工业生产过程控制、交通等领域的一种自动识别技术,具有输入速度快、准确度高、成本低、可靠性强等优点,在当今的自动识别技术中占有重要的地位。
定义:
常用的一维码的码制(类型)包括:EAN码、39码、交叉25码、UPC码、128码、93码,ISBN码,及Codabar(库德巴码)等。
EAN 码:是国际通用的符号体系,是一种长度固定、无含意的条码,所表达的信息全部为数字,主要应用于商品标识 39码和128码:为国内企业内部自定义码制,可以根据需要确定条码的长度和信息,它编码的信息可以是数字,也可以包含字母,主要应用于工业生产线领域、图书管理等。Code 39 码,是用途广泛的一种条形码,可表示数字、英文字母以及“−”、“.”、“/”、“+”、“%”、“$”、 “”(空格)和“*”共 44 个符号,其中“*”仅作为起始符和终止符。既能用数字,也能用 字母及有关符号表示信息。信息全部为数字,主要应用于商品标识。
93码:是一种类似于39码的条码,它的密度较高,能够替代39码。 25码:主要应用于包装、运输以及国际航空系统的机票顺序编号等。 Codabar码:应用于血库、图书馆、包裹等的跟踪管理。 ISBN:用于图书管理。
其他类型参考条形码-维基百科
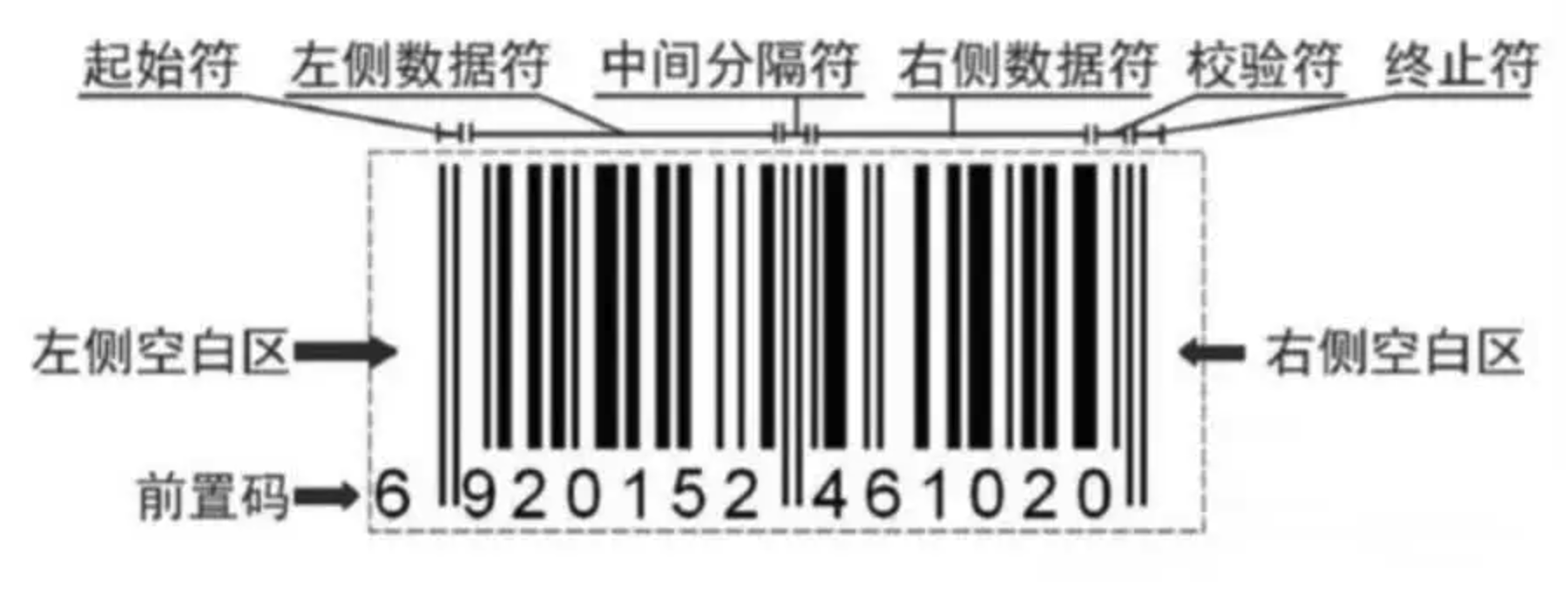
一个完整的条码的组成次序依次为:静区(前)、起始符、数据符、(中间分割符,主要用于EAN码)、(校验符)、终止符、静区(后),如上图:
要将按照一定规则编译出来的条形码转换成有意义的信息,需要经历扫描和译码两个过程。
物体的颜色是由其反射光的类型决定的,白色物体能反射各种波长的可见光,黑色物体则吸收各种波长的可见光,所以当条形码扫描器光源发出的光在条形码上反射后,反射光照射到条码扫描器内部的光电转换器上,光电转换器根据强弱不同的反射光信号,转换成相应的电信号。根据原理的差异,扫描器可以分为光笔、CCD、激光三种。电信号输出到条码扫描器的放大电路增强信号之后,再送到整形电路将模拟信号转换成数字信号。白条、黑条的宽度不同,相应的电信号持续时间长短也不同。
译码器通过测量脉冲数字电信号0、1的数目来判别条和空的数目,通过测量0、1信号持续的时间来判别条和空的宽度。此时所得到的数据仍然是杂乱无章的,要知道条形码所包含的信息,则需根据对应的编码规则(例如:EAN-8码),将条形符号换成相应的数字、字符信息。最后,由计算机系统进行数据处理与管理,物品的详细信息便被识别了。

随着普及,新的问题出现:条形码的容量有限,英文数字最多只能容纳20个字符
有了新的诉求:
当时负责QR码研发负责人,也就是二维码之父-原昌宏,思考:条形码只能横向(一维)存储信息,相比之下,如果能纵横排列,就可以容纳更多信息。并且要在这个基础上,做到便于读取。于是就有了后来的二维码。

二维码之父-原昌宏
这里也叫做二维码的码制,常见的码制有:
QRCode、汉信码、PDF417二维条码(opens new window)、Datamatrix二维条码、Code 49、Code 16K、Code one等。样例如图所示:



传统的条形码只能处理20位左右的信息量,与此相比,QR码可处理条形码的几十倍到几百倍的信息量。
另外,QR码还可以支持所有类型的数据。(如:数字、英文字母、日文字母、汉字、符号、二进制、控制码等)。一个QR码最多可以处理7089字(仅用数字时)的巨大信息量。
QR码使用纵向和横向两个方向处理数据,如果是相同的信息量,QR码所占空间为条形码的十分之一左右。(还支持Micro QR码,可以在更小空间内处理数据。)

QR码是日本国产的二维码,因此非常适合处理日文字母和汉字。
QR码字集规格定义是按照日本标准“JIS第一级和第二级的汉字”制定的,因此在日语处理方面,每一个全角字母和汉字都用13比特的数据处理,效率较高,与其他二维码相比,可以多存储20%以上的信息。
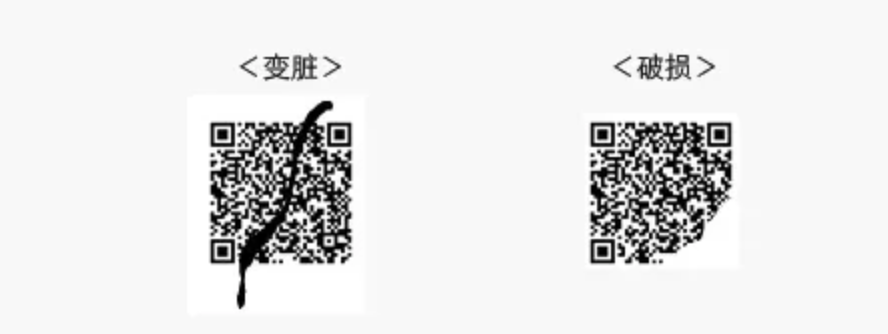
QR码具备“纠错功能”,即使部分编码变脏或破损,也可以恢复数据。数据恢复的单位是“码字”(是组成内部数据的单位,在QR码的情况下,每8比特代表1码字。) 根据变脏和破损程度的不同,也存在无法恢复的情况。
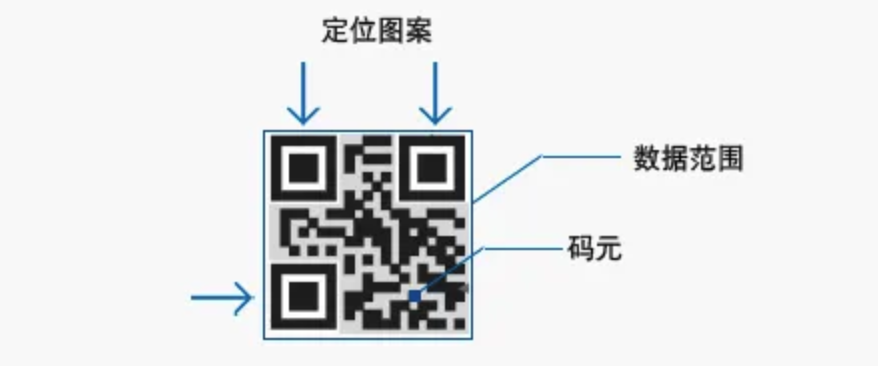
QR码从360°任一方向均可快速读取。原因在于QR码中的3处定位图案,可以帮助QR码不受背景样式的影响,实现快速稳定的读取。
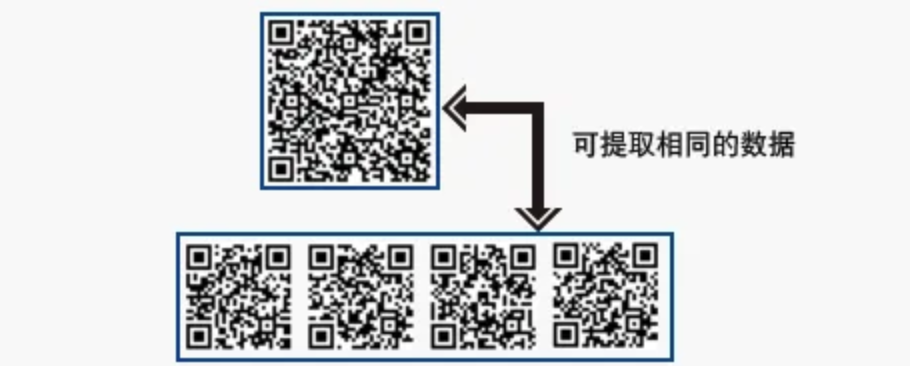
QR码可以将数据分割为多个编码,最多支持16个QR码。使用这一功能,还可以在狭长区域内打印QR码。另外,也可以把多个分割编码合并为单个数据。
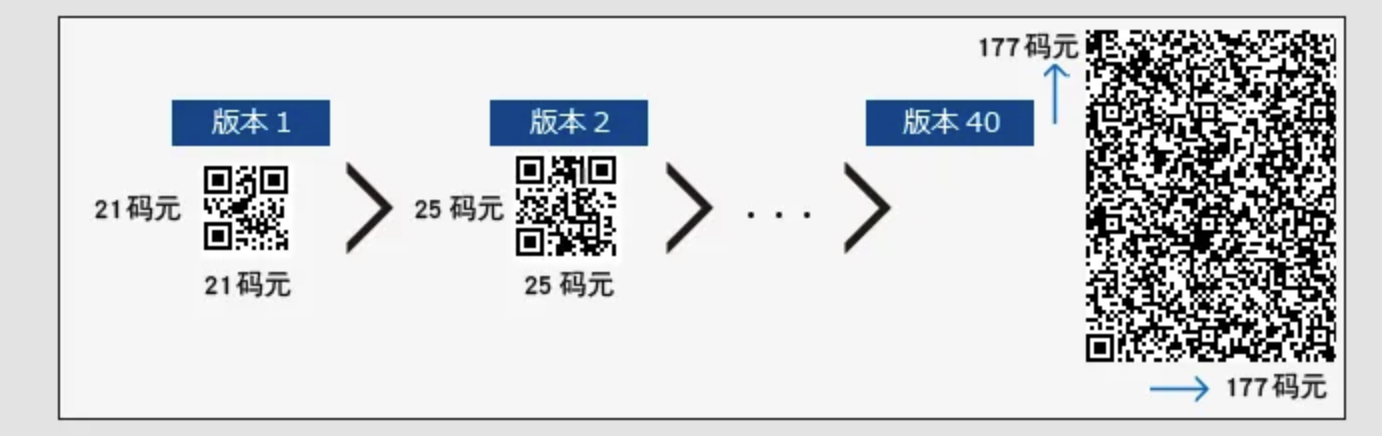
QR码设有1到40的不同版本(种类),每个版本都具备固有的码元结构(码元数)。(码元是指构成QR码的方形黑白点。)
“码元结构”是指二维码中的码元数。从版本1(21码元×21码元)开始,在纵向和横向各自以4码元为单位递增,一直到版本40(177码元×177码元)。
QR码的各个版本结合数据量、字符类型和纠错级别,均设有相对应的最多输入字符数。也就是说,如果增加数据量,则需要使用更多的码元来组成QR码,QR码就会变得更大。
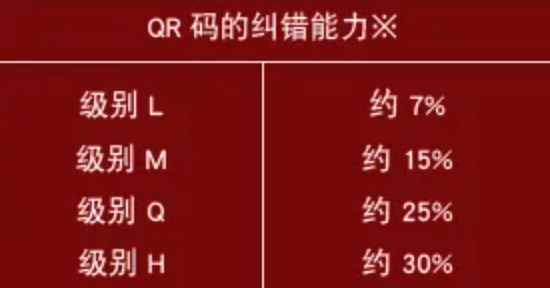
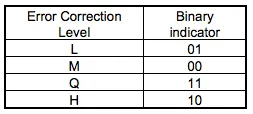
QR码具有“纠错功能”。即使编码变脏或破损,也可自动恢复数据。这一“纠错能力”具备4个级别,用户可根据使用环境选择相应的级别。调高级别,纠错能力也相应提高,但由于数据量会随之增加,编码尺寸也也会变大。
用户应综合考虑使用环境、编码尺寸等因素后选择相应的级别。 在工厂等容易沾染赃物的环境下,可以选择级别Q或H,在不那么脏的环境下,且数据量较多的时候,也可以选择级别L。一般情况下用户大多选择级别M(15%)。
恢复率:相对比全部码字的比率
纠错级别的比率,是指全部码字与可以纠错的码字的比率。 例如,需要编码的码字数据有100个,并且想对其中的一半,也就是50个码字进行纠错,则计算方法如下。纠错需要相当于码字2倍的符号(RS编码),因此在这种情况下的数量为50个×2=100码字。因此,全部码字数量为200个,其中用作纠错的码字为50个,所以计算得出,相对于全部码字的纠错率就是25%。这一比率相当于QR码纠错级别中的“Q”级别。
RS编码:QR码的纠错功能是通过将RS编码附加到原数据中的方式实现的。RS编码是应用于音乐CD等用途的数学纠错方法。它能以字节为单位进行纠错,适合用于错误位置会集中的突发错误。
例如,需要输入的数据为100位的数字时,通过以下步骤来选定。
1.假设要输入的数据种类为“数字” 2.从“L”“M”“Q”“H”中选择纠错级别。(假设选择“M”) 3.查看下表,先从数字列找出数字为100以上且接近100的,其次找出纠错级别“M”,两者交叉的部分就是最佳版本。
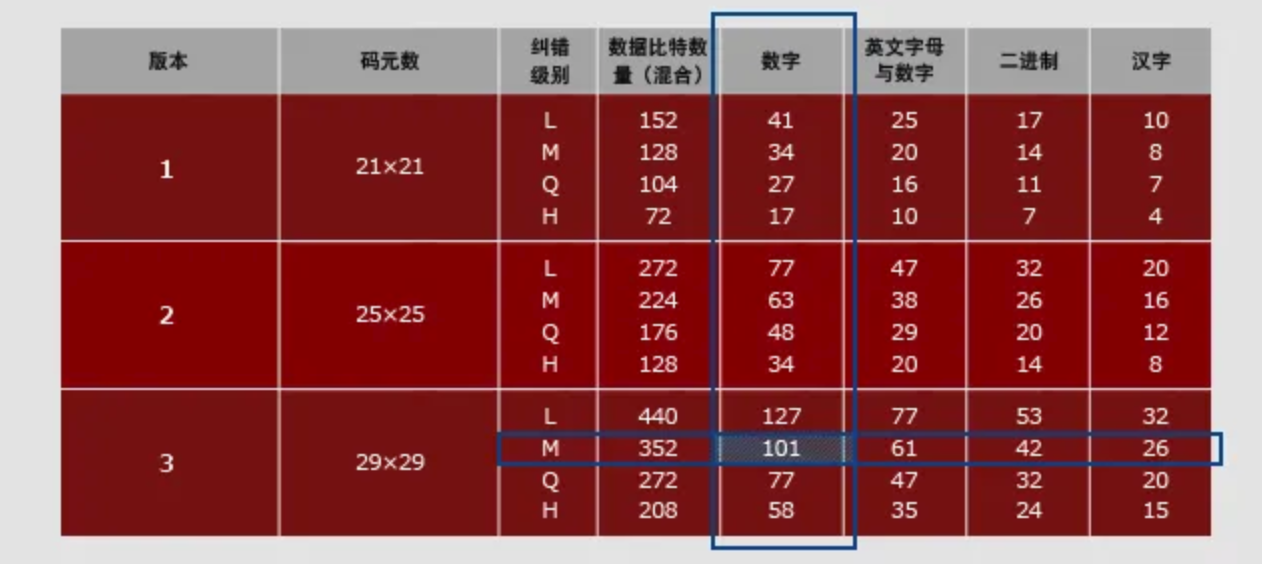
问题:面对不同混合字符的数据怎么办?参考:https://www.qrcode.com/zh/about/version.html

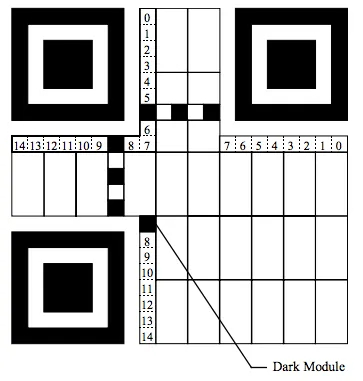
二维码结构图示意图
(1)位置探测图形、位置探测图形分隔符、定位图形:
用于对二维码的定位,对每个QR码来说,位置都是固定存在的,只是大小规格会有所差异; 这三个定位图案有白边即位置探测图形分隔符,之所以三个而不是四个,因为三个就可以标识一个矩形了
(2)校正图形
规格确定,校正图形的数量和位置也就确定了,Version 2以上(包括Version2)的二维码才需要这个。
(3)格式信息
表示该二维码的纠错级别,分为L、M、Q、H,存在于所有的尺寸中,用于存放一些格式化数据的。
(4)版本信息
即二维码的规格,QR码符号共有40种规格的矩阵(一般为黑白色),从21x21(版本1),到177x177(版本40),每一版本符号比前一版本 每边增加4个模块。在 >= Version 7以上,需要预留两块3 x 6的区域存放一些版本信息。
(5)数据和纠错码字
实际保存的二维码信息,和纠错码字(用于修正二维码损坏带来的错误)。

二维码内容:123456
首先,先把位置探测图形图案画在三个角上。(无论Version如何,这个图案的尺寸就是这么大7*7)
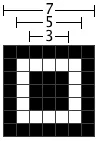
(2)绘制校正图形( 5*5)
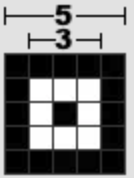
关于Alignment的位置,可以查看[QR Code Spec]的第81页的Table-E.1的定义表(下表是不完全表格)
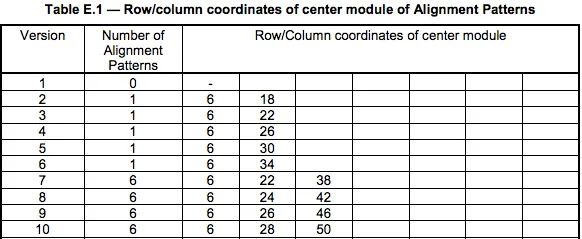
下图是根据上述表格中的Version8的一个例子(6,24,42)
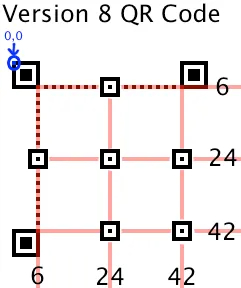
(3)绘制定位图形
接下来是定位图形的线。
再接下来是格式信息,下图中的蓝色部分。
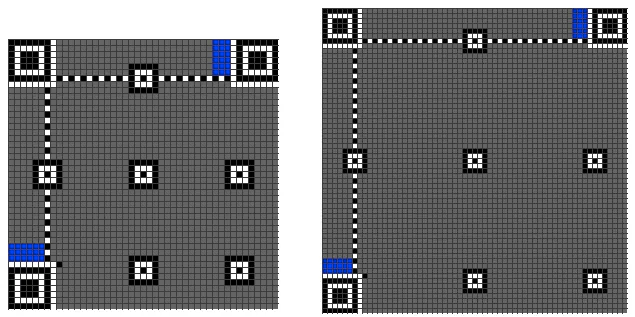
格式信息是一个15个bits的信息,每一个bit的位置如下图所示:(注意图中的Dark Module,会永远出现)
这15个bits中包括:
然后15个bits还要与101010000010010做XOR操作。这样就保证不会因为我们选用了00的纠错级别和000的Mask,从而造成全部为白色,这会增加我们的扫描器的图像识别的困难。

(5)添加版本信息
(版本7以后需要这个编码),下图中的蓝色部分。
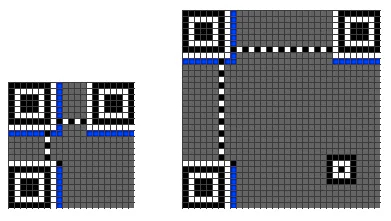
版本信息 一共是18个bits,其中包括6个bits的版本号以及12个bits的纠错码,下面是一个示例

而其填充位置如下图:
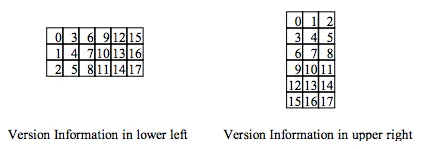
(6)绘制数据和数据纠错码
然后是填接我们的最终编码,最终编码的填充方式如下:从左下角开始沿着红线填我们的各个bits,1是黑色,0是白色。如果遇到了上面的非数据区,则绕开或跳过。

(7)转换为掩码图案
这样下来,我们的图就填好了,但是,也许那些点并不均衡,如果出现大面积的空白或黑块,会告诉我们扫描识别的困难。
所以,我们还要做Masking操作,有8个Mask你可以使用。如下所示:其中,各个mask的公式在各个图下面。所谓mask,就是和上面生成的图做XOR操作。Mask只会和数据区进行XOR,不会影响功能区。(注:选择一个合适的Mask也是有算法的)

下面是Mask后的一些样子,我们可以看到被某些Mask XOR了的数据变得比较零散了。
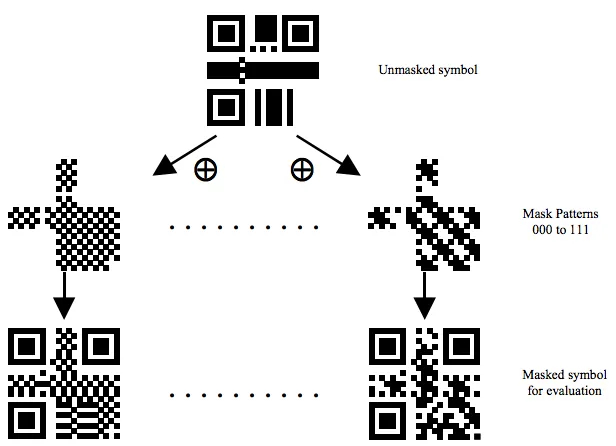
Mask过后的二维码就成最终的图了。
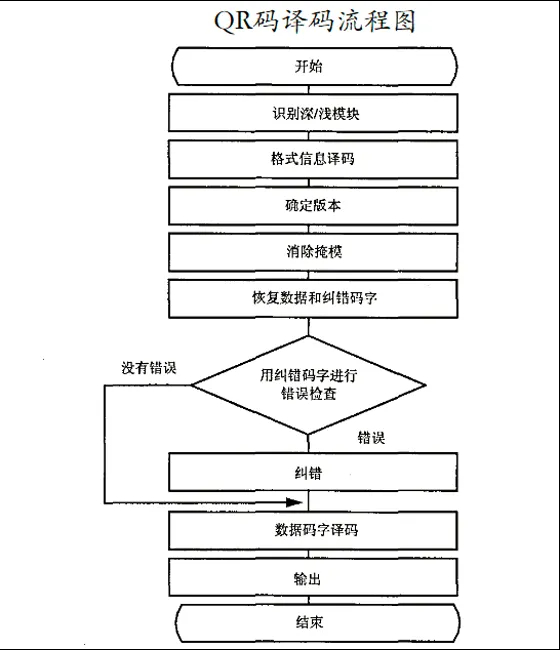
将上述编码过程反过来就是解码过程:
