

本文主要介绍在win10上如何安装和使用pyspark,并运行经典wordcount示例,以及分享在运行过程中遇到的问题。
jdk下载链接,建议按照1.8版本,高版本会出现兼容性问题。
https://www.oracle.com/java/technologies/downloads/#java8-windows
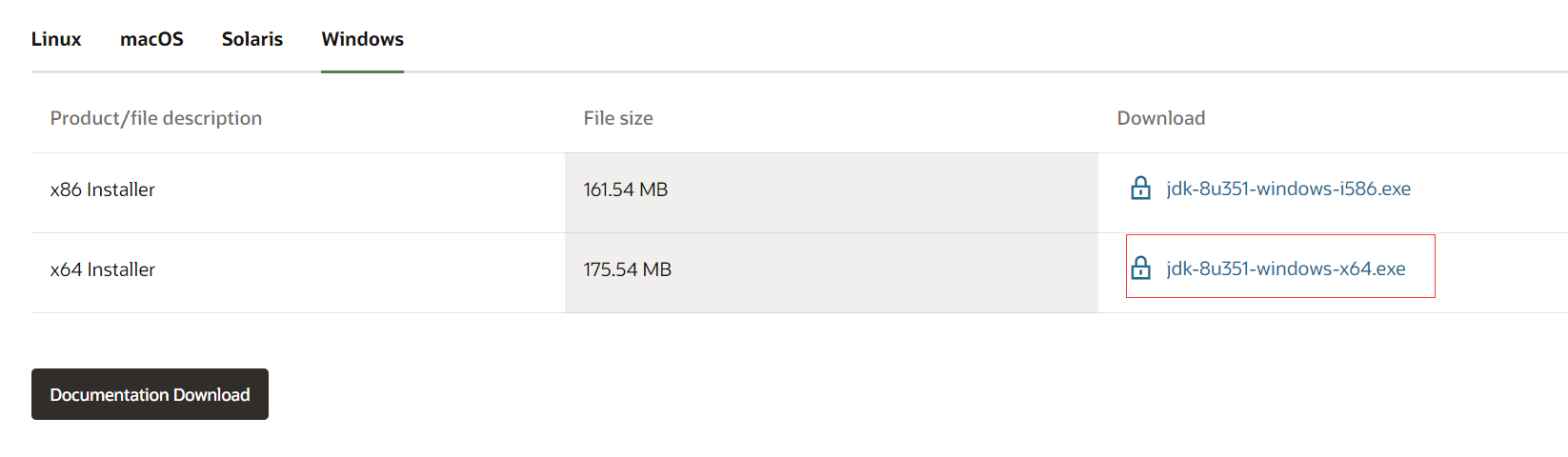
我安装在C:\Program Files\Java\jdk1.8.0_271
配置环境变量:设置--高级系统设置--系统属性--高级--环境变量--系统变量
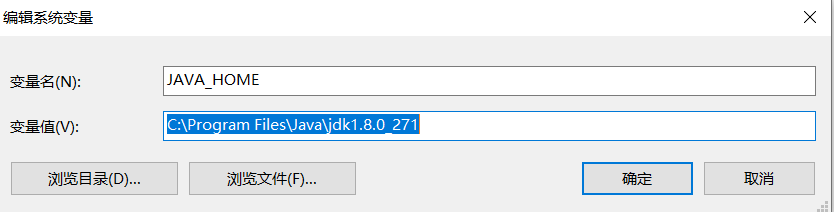
编辑系统变量--新建JAVA_HOME
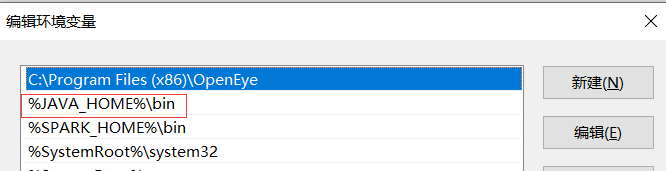
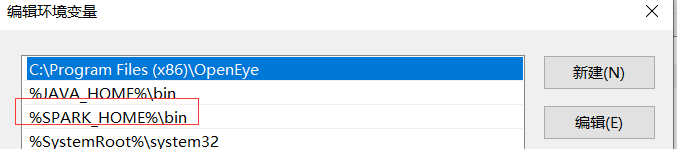
编辑环境变量Path--添加%JAVA_HOME%\bin
配置成功在cmd运行 java -version

下载链接:https://spark.apache.org/downloads.html
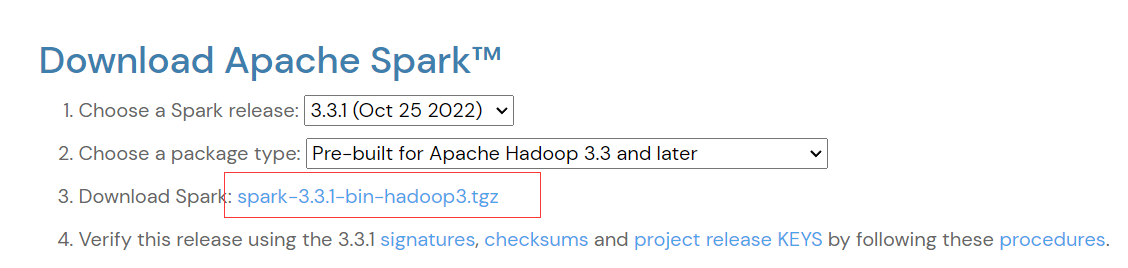
下载后解压,我的文件地址:D:\program\spark-3.3.1-bin-hadoop3
配置环境变量:设置--高级系统设置--系统属性--高级--环境变量--系统变量
编辑系统变量--新建SPARK_HOME
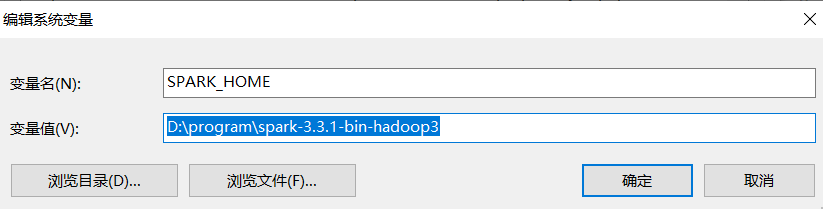
编辑环境变量Path--添加%SPARK_HOME%\bin
配置完成,在powerShell输入spark-shell
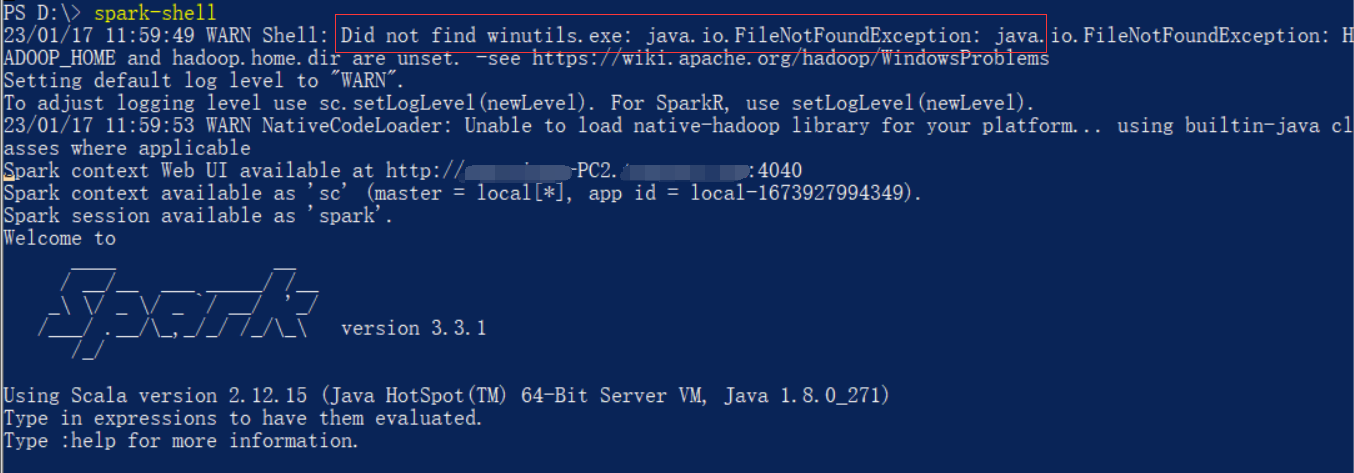
注意里面有个错误提示Unable to load native-hadoop library for your platform,先不管后续会解决。
pyspark安装比较简单,直接pip安装即可。

这里建议使用conda建新环境进行python和依赖库的安装
注意python版本不要用最新的3.11
否则再后续运行pyspark代码,会遇到问题:tuple index out of range
https://stackoverflow.com/questions/74579273/indexerror-tuple-index-out-of-range-when-creating-pyspark-dataframe
pip3 install pyspark
pip3 install py4j
pip3 install psutil
pip3 install jieba配置完成,在命令行下python-->import pyspark成功说明安装成功。
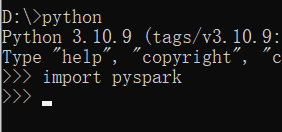
或者power shell中直接运行pyspark
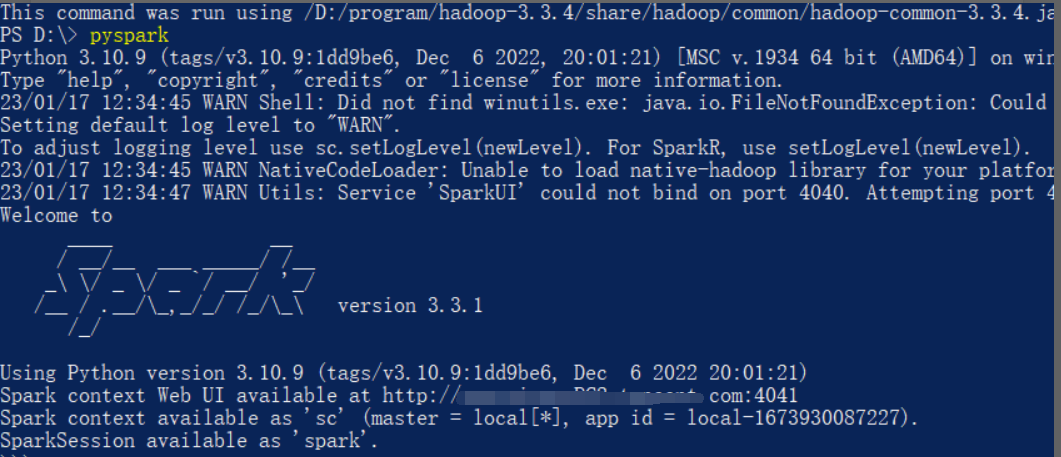
下载链接:https://hadoop.apache.org/releases.html

如果解压遇到权限问题,需要使用管理员身份运行:

解压后同样在需要配置环境变量
配置环境变量:设置--高级系统设置--系统属性--高级--环境变量--系统变量
编辑系统变量--新建HADOOP_HOME
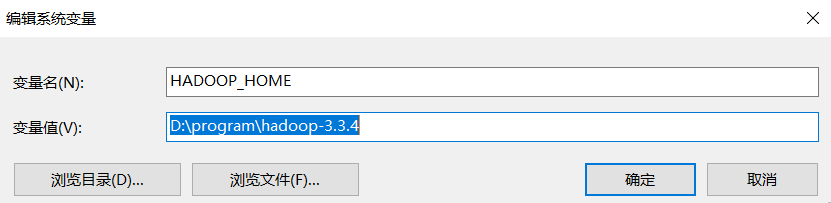
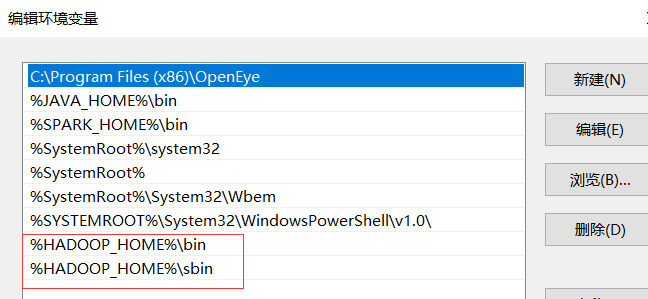
编辑环境变量Path--添加%HADOOP_HOME%\bin 和%HADOOP_HOME%\sbin
进入Hadoop的配置目录etc\hadoop,打开文件hadoop-env.cmd,修改Java的安装路径,如果Java安装在Program Files可以通过设置为PROGRA~1解决空格报错的问题
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_271
配置成功后在power shell执行hadoop version

这里软件安装以及完毕,但是运行代码过程中会报错HADOOP_HOME unset

解决步骤:
1. winutils.exe
winutils:
由于hadoop主要基于linux编写,winutil.exe主要用于模拟linux下的目录环境。当Hadoop在windows下运行或调用远程Hadoop集群的时候,需要该辅助程序才能运行。
下载对应版本的 winutils(我的hadoop是3.3.4,winutils下载的3.0.0),把下载到的bin文件夹覆盖到Hadoop安装目录的bin文件夹,确保其中含有winutils.exe文件
https://github.com/steveloughran/winutils
2. hadoop.dll
把hadoop/bin下的hadoop.dll放到C:/windows/system32文件夹下
到此就可以正常运行代码了。
但是我的笔记本通过以上过程后,在运行过程中遇到问题:
org.apache.spark.SparkException: Python worker failed to connect back.
https://blog.csdn.net/weixin_43290383/article/details/120775584
解决方案:
增加环境变量:
key: PYSPARK_PYTHON
value: C:\ProgramData\Anaconda3\envs\spark310\python.exe
有些文档说value可以直接设置为python,我的笔记本测试不行,必须设置为python路径
统计分词词频
# -*- coding: utf-8 -*-
import jieba
from pyspark.context import SparkContext
def word_count():
# 读取数据,创建弹性式分布数据集(RDD).<class 'pyspark.rdd.RDD'>
data = spark.textFile(r"docs.txt")
# 读取中文停用词
with open(r'stopwords-zh.txt', 'r', encoding='utf-8') as f:
s = f.readlines()
stop = [i.replace('\n', '') for i in s]
# reduceByKey函数利用映射函数将每个K对应的V进行运算
# 分词并统计词频
data = data.flatMap(lambda line: jieba.cut(line, cut_all=False)). \
filter(lambda w: w not in stop). \
map(lambda w: (w, 1)). \
reduceByKey(lambda w0, w1: w0 + w1). \
sortBy(lambda x: x[1], ascending=False)
# data.foreach(lambda x: print(x))
# print(data.collect())
# 写入文件
data.saveAsTextFile(r"D:\result.txt")
# 输出前100个高频词汇
print(data.take(100))
if __name__ == '__main__':
# 实例化一个SparkContext,用于连接Spark集群
# 第一个参数“local”表示以本地模式加载集群
# 第二个参数“WordCount”表示appName,不能有空格
spark = SparkContext("local", "WordCount")
word_count()直接在命令行运行
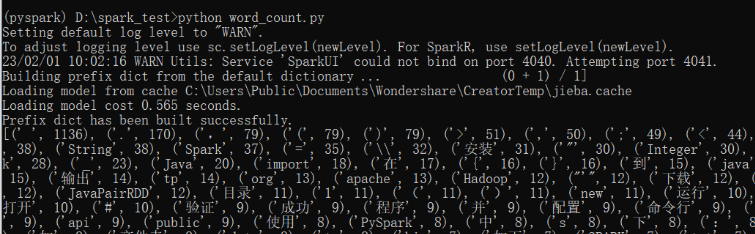
如果在pycharm中运行,需要进行环境配置,以及在环境在环境变量中,记得将spark和hadoop的环境变量也加入
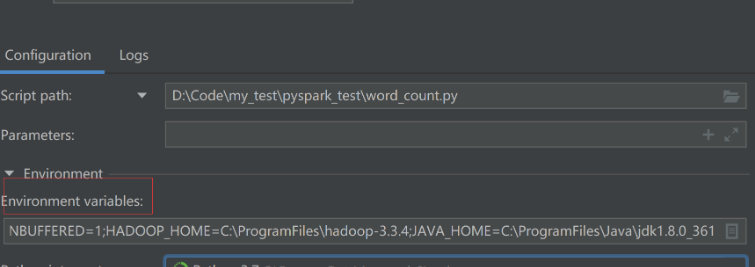
参考
https://yxnchen.github.io/technique/Windows%E5%B9%B3%E5%8F%B0%E4%B8%8B%E5%8D%95%E6%9C%BASpark%E7%8E%AF%E5%A2%83%E6%90%AD%E5%BB%BA/#%E5%AE%89%E8%A3%85PySparkhttps://blog.csdn.net/whs0329/article/details/121878162
https://cloud.tencent.com/developer/article/1701582
