


导语 |腾讯文档 SmartSheet 视图是多种视图中的一种,该模式下 FPS 仅 20 几帧(普通 Sheet 视图下 58 帧),用户体验非常卡顿。腾讯文档团队针对该问题进行优化,通过禁用取色、多卡片离屏渲染等方式实现 FPS 接近 60 帧,提升两倍多。本文将详细介绍其挑战和解决方案,并输出通用的经验方法。希望本文对你有帮助。
目录
1 前言
2 增量渲染
3 分析火焰图
4 禁用取色
5 减少搜索结果匹配
6 避免使用 clone
7 多卡片离屏渲染
7.1 多卡片 vs 整屏
7.2 实现
8 文本缓存
9 最后
前言
腾讯文档智能表格是一种拥有多视图的新型表格。智能表格也是一个天然的低代码平台,只要使用开放的增删改查 API 就能实现一个后台管理系统,利用提供的各种视图将数据展示出来。它本质上是一个在线数据库,拥有更丰富的列类型和视图。智能表格可以让一份数据多种维度展示。目前已经有表格视图、看板视图(SmartSheet 视图)、画册视图、甘特视图、日历视图等。
除了最被熟知的表格视图之外,SmartSheet 看板视图以卡片的形式来展现,非常适合做一些运营活动和项目管理,从而开始得到关注。看板视图可以根据单选列作为分组依据,进行卡片的一个聚合分组展示。卡片的高度是不固定的,只有当前列有内容才会展示出来。下图是腾讯文档智能表格 SmartSheet 看板视图的无封面版本和有封面版本:
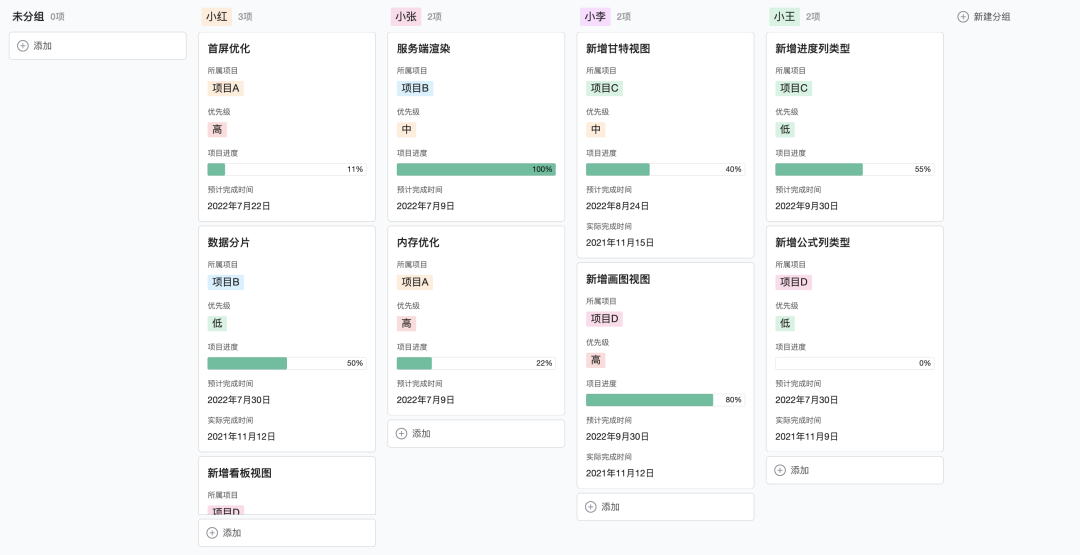
SmartSheet 看板视图上线后,10 w 单元格场景下的 FPS只有 20 多帧,比起Sheet 视图的 58 帧差距比较大,用户体验非常卡顿。
FPS (Frames Per Second) 就是每秒钟画面的更新次数。理论上 FPS 越高,动画就会越流畅。由于大多数设备屏幕刷新率都是 60 次 / 秒,所以一般来说 FPS 为 60 帧的时候最流畅,此时每帧的消耗时间约为 16.67 ms。如果 FPS 低于 30 帧,就会出现明显的卡顿和不流畅。所以腾讯文档团队优化的重点目标是:尽量将每一帧的耗时降低到 16.67 ms。
增量渲染
Smart Sheet 看板是多种视图中的一种。它主要是多个分组来组成的,每个分组又包括了多个卡片。滚动的时候包括左右分组滚动、分组内卡片上下滚动两种。
先来了解渲染层的实现,Smart Sheet 看板渲染层初始化分为4个阶段:
第一阶段,收集计算文本宽高、截断等等;
第二阶段,收集各种树形结构的 widget,比如 textPainter、cardPainter、groupPainter 等等。
第三阶段,基于 widget 进行绘制,从根 layoutTree 开始递归子节点执行 painter 方法;
第四阶段,Konva 执行 Layer 的 batchDraw 方法,递归执行子节点的 draw 方法。
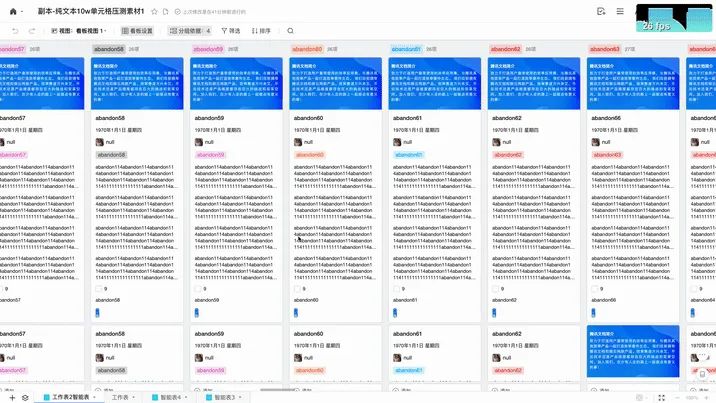
10 w 单元格不会将全部卡片都给绘制出来。因为它一方面会导致绘制时间过长,另一方面存放绘制信息占用的内存太多。
所以只会收集可视区域内的 widget 进行绘制。在滚动的时候,会计算出需要销毁的卡片和需要新增的卡片,然后开始销毁前面的节点,重新创建新的节点,进行增量渲染。对应上面的第 2、3 步,但此时只会收集增量的 Painter。
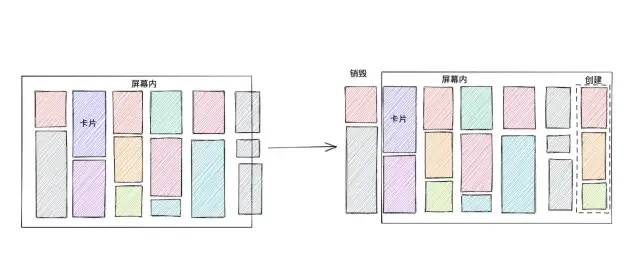
分析火焰图
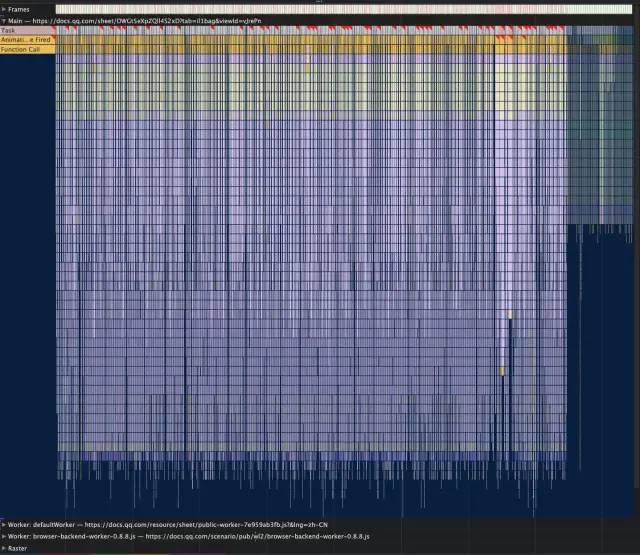
首先需要知道滚动的时候主要是耗时在哪里。打开 Chrome 的 Performance 选项,选择最左边的实心圆录制,在页面上用鼠标滚动。最后生成了下面这份火焰图,可以看到有很多红色倒三角,说明这里出现了一些很耗时的操作。
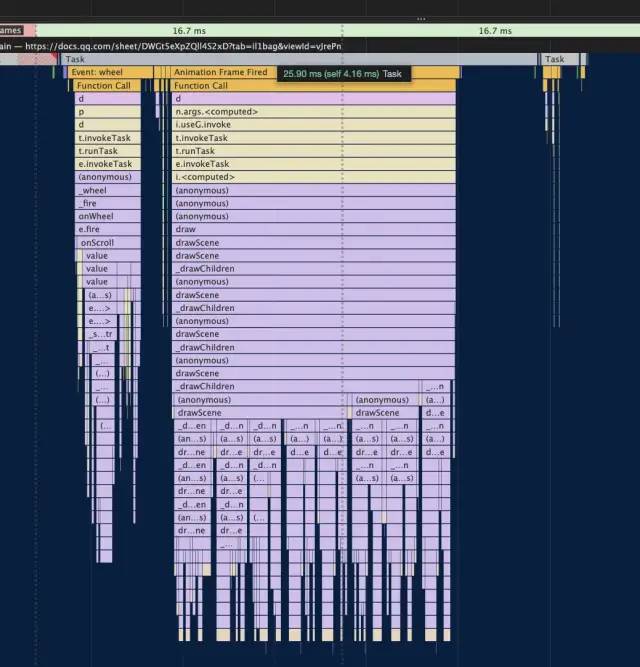
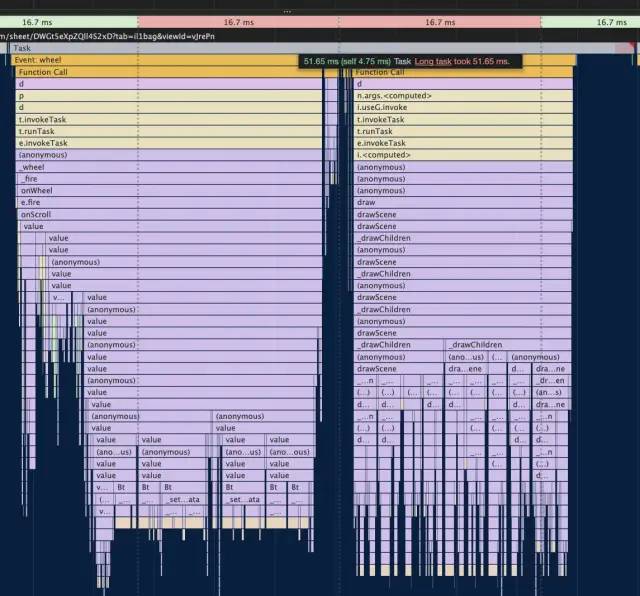
放大这个火焰图,可以看到其中的一个 Task 的耗时,也就是一帧的耗时。可以看到两种情况,后者明显比前者耗时多太多了。
Task1:
Task2:
那滚动的时候渲染层做了哪些事情呢?主要是下面几步:
第一步,对原来的分组设置偏移量;
第二步,计算新的可视区域,包括需要销毁、创建的分组和卡片;
第三步,收集分组或者卡片的 widget;
第四步,基于 widget 进行绘制,主要是创建 Konva 节点,添加子节点等;
第五步,触发 Layer 的 batchDraw 方法,遍历子节点进行绘制。
禁用取色
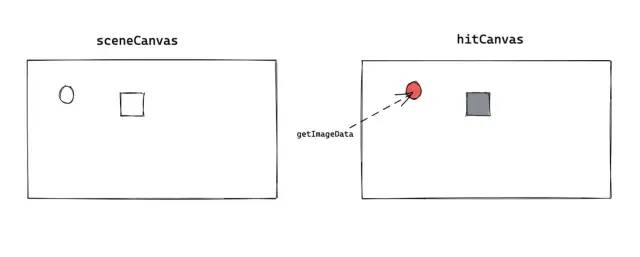
可以从上面看到 getImageData 耗时非常多,那为什么滚动的时候会用到 getImageData 呢?这就不得不说到 Canvas 的事件系统了。
Canvas 不像 DOM 一样拥有事件系统,所以无法直接知道当前点击的是哪个图形,需要开发者自己实现一套事件系统。简单来说,就是知道某个坐标点当前对应的是什么图形。
Konva 为了能够根据坐标点匹配到触发的元素,采用了色值法——也就是在内存里面的 hitCanvas 里面绘制一模一样的图形,给这个图形加一个随机填充色,生成一个 colorKey。然后以这个 colorKey 作为 key,Shape 作为 value,存了起来。
事件触发时通过 hitCanvas 的 getImageData 方法拿到 colorKey,进一步拿到对应的 Shape。
我们在自己电脑本地执行了 1000 次 getImageData,发现耗时非常多。在滚动的时候,很容易触发大量调用 getImageData。
Navigated to file xx getImageData 1000次: 250.051025390625 ms Navigated to file xx getImageData 1000次: 245.02587890625 ms Navigated to file xx getImageData 1000次: 245.637939453125 ms Navigated to file xx getImageData 1000次: 254.847900390625 ms
怎么避免调用 getImageData 呢?我们来翻翻 Konva 的源码。
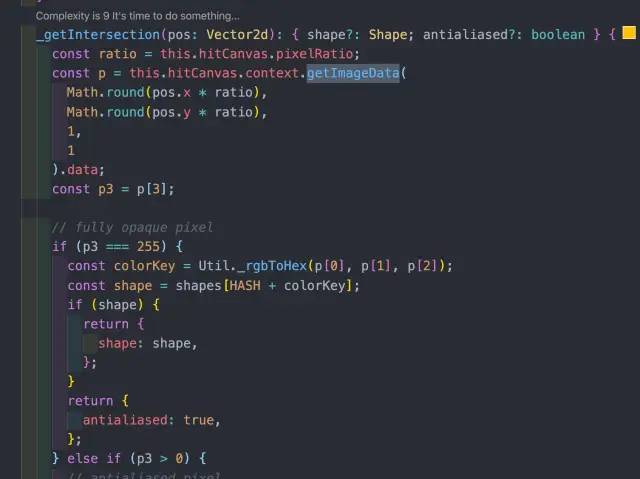
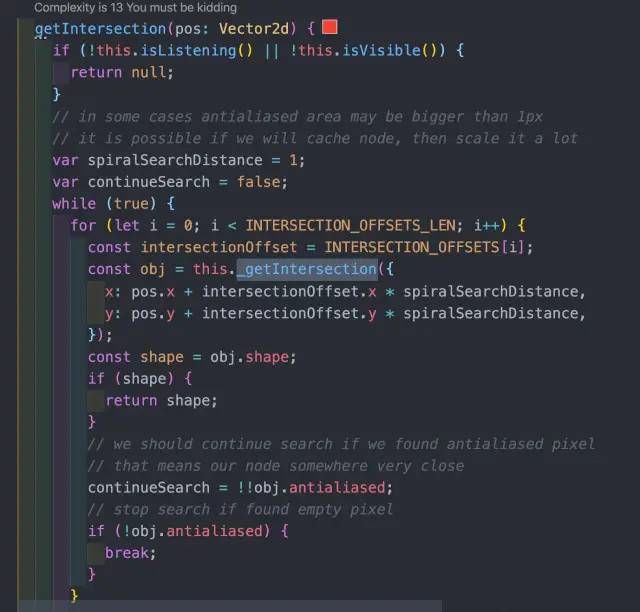
滚动的时候,触发的是 wheel 事件。只需要在滚动的时候设置 layer 的 isListening 为 false 即可。等滚动结束后再设置回来,所以这里是 debounce 的逻辑。
减少搜索结果匹配
前面我们说过,渲染层在渲染的时候会进行收集,在滚动的时候由于可能会有搜索结果高亮的存在,所以也要计算当前卡片是否匹配搜索结果。如果匹配了,那就设置背景色。
但如果在没有启动搜索的时候,不应该遍历 layoutTree,而是应该直接返回。提前返回,可以节省大约 2 ms 的搜索高亮收集时间。
避免使用 clone
很多文本和矩形有共同属性,所以我们原本是先创建了一个节点,使用的时候通过 clone 的方式复用,然后用 setAttrs 来设置新的 config。
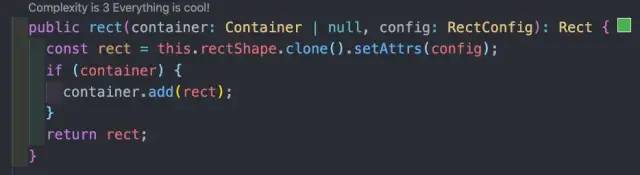
但 clone 的实现比较复杂。可以理解成进行了一次深拷贝,会带来一些性能损耗。

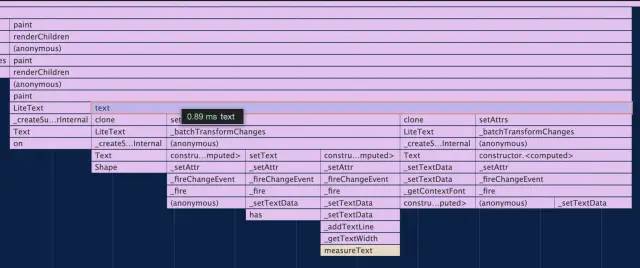
这里不够优雅,可以提前缓存通用的 config 值,然后直接使用 new 来创建节点。
从图上可以看到,很明显耗时下降了。

当我们优化到这一步发现:在没有出现新的卡片时,滚动的耗时已经非常少了,基本上耗时都在绘制阶段。
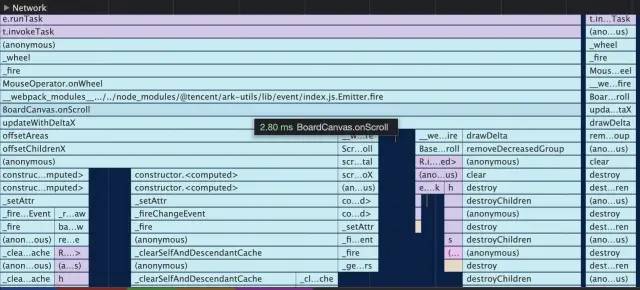
绘制阶段的耗时达到了 13 ms 之多。
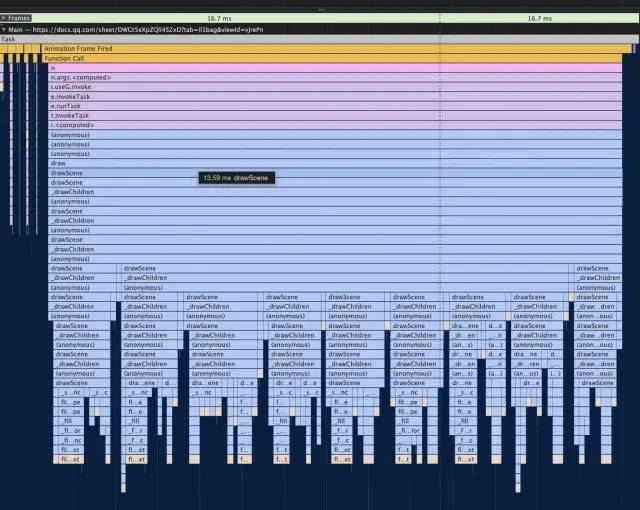
多卡片离屏渲染
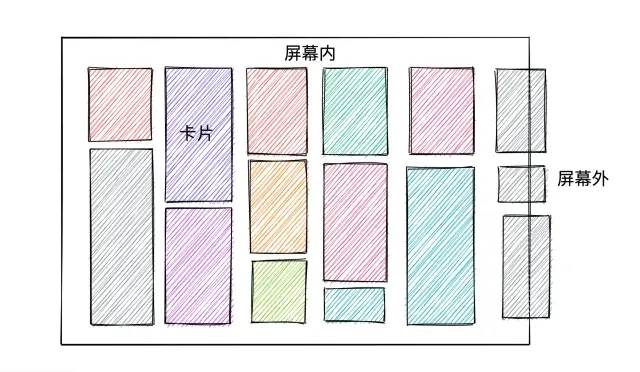
绘制阶段要怎么去优化耗时呢?页面滚动的时候,每次其实只移动了一小段距离,只有这部分是新增的。那也就意味着前面大部分都是不变的,只是增加了一些偏移量,如果能够对其进行复用,那肯定可以大大减少耗时。
离屏渲染是 Canvas 的一种普遍的优化手段。比如腾讯文档团队的 Sheet 和 Word 都有离屏渲染,思路都是在滚动的时候,通过 drawImage 来复用前面已经绘制的部分,然后再绘制增量的部分,这样可以减少大量文本的绘制。
Smart Sheet 相比 Sheet 和 Word 来说会特殊一些,腾讯文档团队使用了 Konva 这个框架,它自身封装了一套渲染逻辑,所以对于 Word 这种离屏渲染来说,实现起来比较麻烦。
因此,针对看板的情况,可以针对多个卡片做离屏渲染。多个卡片离屏渲染比整屏离屏渲染更有优势。
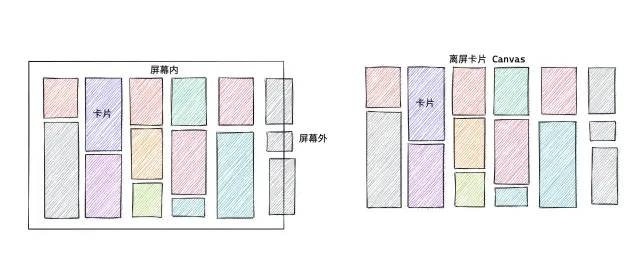
看板滚动主要有两种情况:
第一种,没有出现新的分组和卡片,当前只是在可视区域的卡片内滚动;
第二种,出现了新的分组和卡片,涉及到了节点的销毁和新增。
对于第一种情况来说,此时没有新增卡片,多卡片离屏渲染只需要把离屏 Canvas 里面的内容绘制到主屏就行了。但整屏离屏渲染依然会去多渲染增量部分,因为它是以整个屏幕为纬度的;对于第二种情况来说,两者都需要绘制增量部分的卡片,所以理论上消耗是一样的。
但在快速滚动的情况下,大部分时间都是没有出现新的分组的,大概率是在可视区内的几个分组移动,所以这种情况下,如果使用整屏渲染,就不得不多去渲染一个分组。
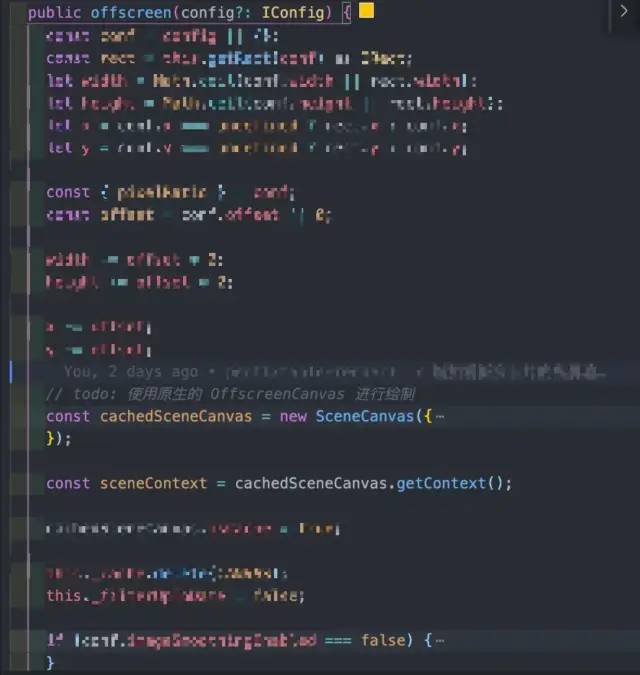
在创建 Group 的时候,增加一个 offscreen 选项,它会多创建一个离屏 Canvas。也就是 offscreenCanvas,这个 canvas 会根据主屏的 Group 里面的子元素来先绘制一遍。
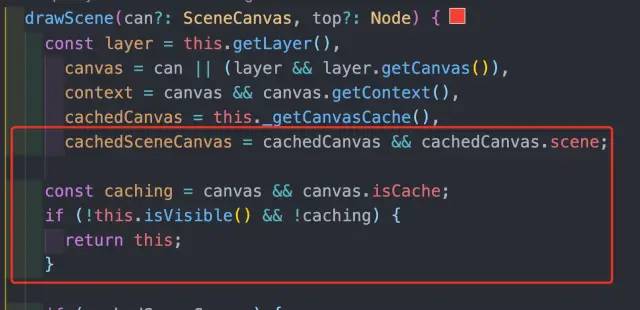
在 Group 的实际绘制方法 drawScene 方法里面,判断当前 Group 是否存在离屏 Canvas。如果存在离屏 Canvas,那就直接用 drawImage 的方式。
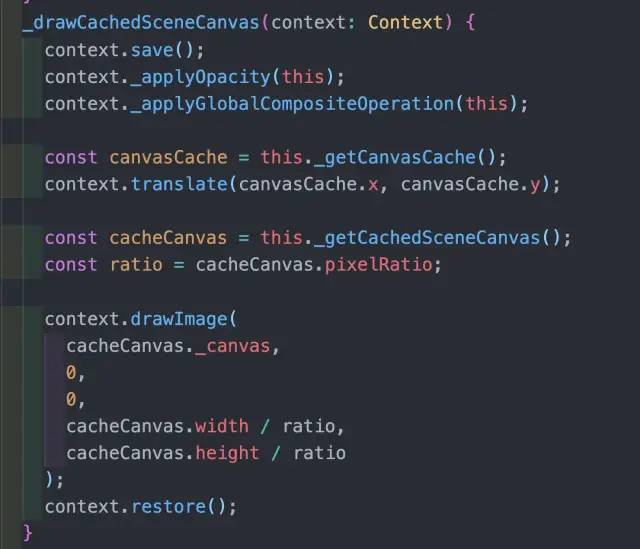
那离屏的 Canvas 什么时候失效呢?由于看板的特殊性,用户修改了某个单元格有可能造成宽高等信息的变化。所以不得不重新计算一遍,这个时候也会重新绘制。
之前的节点都会被销毁掉,然后创建新的节点。因此这个时候重新创建了新的离屏 Canvas 就不会失效了。滚动的时候同理,滚出屏幕外的节点被销毁了,新增的节点重新创建了离屏 Canvas。各位开发者可以看到最终的优化效果,绘制的耗时只有 2 ms。
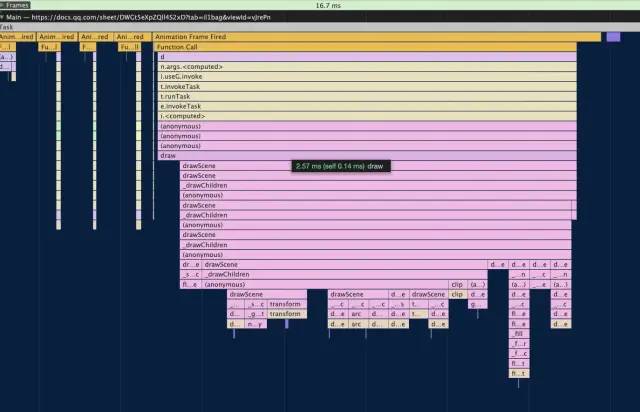
但正如前面说的,离屏渲染只是针对已经渲染好的卡片进行的。那如果滚动的时候,出现了新的卡片怎么办?这部分渲染依然会很耗时。
文本缓存
绘制可复用的部分处理完了,但是绘制增量的部分耗时依然很高,经常可以达到 20 ms 。因为它需要先收集 painter,然后去绘制 widget。收集部分耗时已经优化到很低了,但绘制部分耗时依然很高。那要怎么处理呢?
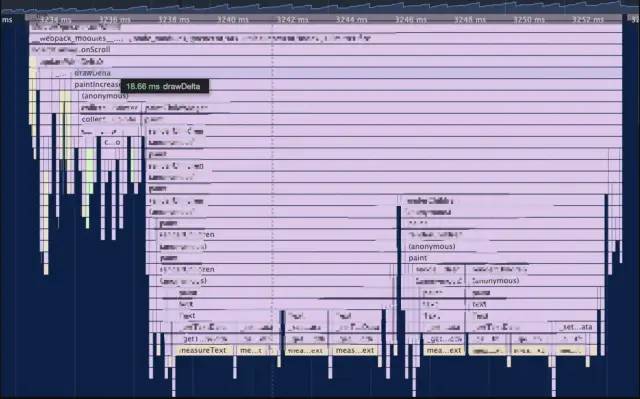
如果是在文本量不多的时候,这部分耗时已经非常低,每帧耗时降至 58 ms,但文本量大的时候耗时就增多了。从图上可以发现,耗时主要发生在文本的计算和绘制上面。那文本计算了哪些呢?
第一,如果给定文本宽度,那文本需要在哪个字符进行截断、换行;
第二,文本最后一行的后面是否需要添加省略号。
文本换行和截断,在 Konva 里面进行了非常复杂的计算。主要是对文本进行二分查找,依次找到最终需要截断的字符位置。如果有换行符,需要对换行符进行特殊处理。如果传入的截断方式是 'word',那还需要对空格和-进行特别的处理。如果传入的是 ellipsis,那需要在最后一行增加省略号。
这些复杂的计算本身会消耗一些时间,其中通过二分查找也会大量调用 measureText 方法。那要怎么处理呢?看板由于需要记录用户上次打开滚动条的位置,再次打开的时候需要跳转过去。为了避免滚动的时候,再去实时计算当前应该新增或减少哪些卡片,会在最开始的时候一次性计算好所有的卡片宽高。
卡片宽度涉及到文本、图片等宽高,也就是说最开始已经处理过文本计算,那这部分缓存起来不就好了?所以在最开始计算的时候可以把属性为 key、宽高等信息作为value 一起存入 cacheText 里面,然后在 setTextData 里面判断 cacheText 里面是否有缓存,如果有的话就不需要重新计算一遍了。
这里缓存了三个信息,分别是文本宽度、文本高度、文本子串数组(被截断分成了好几个)。
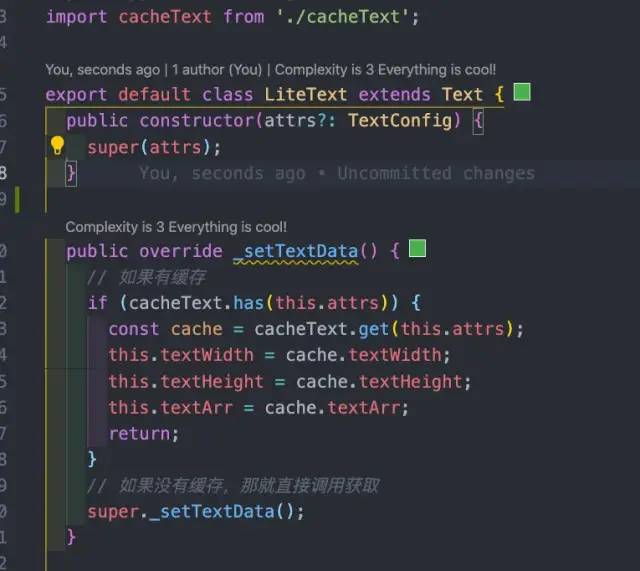
但这样还是会有一些问题:如果文本特别长的话,那 textArr 也会比较大,容易导致内存增长。我们修改策略:不存 textArr,而是存每个子串结束的 index 值(换行的 index 值)。
另外,在最开始计算的时候,只是为了算出文本的高度,绘制阶段最多只展示 4 行,超过 4 行就需要添加省略号,所以算出高度后还要判断是否超过了 4 行。如果直接用最开始计算的结果,它可能包括了超过 4 行的信息,导致绘制阶段不准确。例如存了六行,那绘制的时候需要绘制前 4 行;然而省略号是在第六行,导致在第 4 行丢失了省略号。
因此需要基于业务进一步深度定制,针对 Text 进行一次封装。为了避免动到计算换行的逻辑,我们增加了一个标志位,用于判断当前传入的 height 表示最大高度。
总结与思考
腾讯文档团队优化后的FPS接近 60 帧,从 20 多帧提升到 58 帧左右,也就是提升了两倍多。
在这期间,团队总结了相关经验:应该尽量避免滚动的时候有阻塞主线程的耗时操作。很多地方不易被发现,如深拷贝、序列化、反序列化等等。一些复杂又耗时的计算可以将计算工作的结果提前缓存起来,这样滚动的时候就可以直接从缓存里面读取了。由于这里原本就需要在加载的时候去计算这些,所以就进行了一些改造,让其支持缓存。
如果想不拖慢首屏渲染速度,还可以放到 Web Worker 里面去计算,比如多计算几个分组的文本信息。针对一些比较耗时的绘制操作可以使用离屏渲染的形式来避免重复绘制。这里还可以考虑使用原生的 Offscreen 配合 Web Worker 来发挥离屏渲染的优势。以上是本次分享全部内容,欢迎各位开发者在评论区分享交流。
你可能感兴趣的腾讯工程师作品
|微信全文搜索耗时降94%?我们用了这种方案
|腾讯工程师聊ChatGPT技术「文集」
|站长素材网开发者热门技术干货汇总
|一文读懂 Redis 架构演化之路
技术盲盒:前端|后端|AI与算法|运维|工程师文化
