云服务器概览
云服务器连接
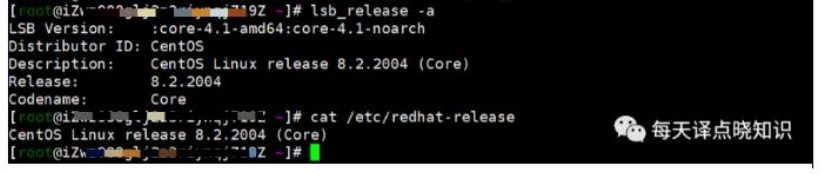
附注: 从上述可知,当前云主机的发行版本为CentOS,当然,若是对于系统访问并发高,业务数据量非常之大的话,除了系统前后台代码本身质量优化之外,服务器配置(物理机or虚拟机or云主机)还可选择更高配些!
Ok,now,有了这些前提条件,接下来开始安装部署我们译点笔记应用-所需要的服务组件:
系统环境
首先,在云后台-防火墙配置好需要外网访问的端口(IP+PORT解析-公网IP或域名外网访问)。
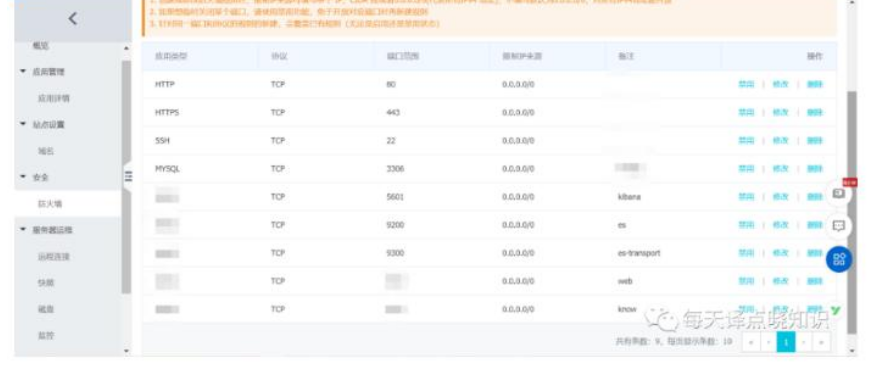
当然,如需通过命令在终端执行,可参考如下,
查询防火墙:systemctl status firewalld
开启防火墙:systemctl start firewalld
查询指定端口是否已开: firewall-cmd --query-port=8089/tcp
停止防火墙:systemctl stop firewalld.service
关闭防火墙:systemctl disable firewalld.service
防火墙开放指定端口:firewall-cmd --zone=public --add-port=8089/tcp --permanent
firewall-cmd --reload
示例:开启MySQL端口
firewall-cmd --zone=public --add-port=3306/tcp
示例:查询MySQL端口
firewall-cmd --query-port=3306/tcp
查询防火墙已开放端口
firewall-cmd --list-ports接着,ssh登录至云主机,配置好Java环境变量,
安装包:jdk-8u171-linux-x64.tar.gz
解压到:/usr/下,为/usr/jdk1.8.0_171
sudo tar zxvf jdk-8u171-linux-x64.tar.gz –C /usr/
编辑:profile
sudo vim /etc/profile
添加环境变量:export JAVA_HOME=/usr/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:.
生效:profile
source /etc/profile
查看:jdk版本
java –version
描述:免费流行的关系型数据库管理系统,在WEB应用方面-RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
yum源方式安装:
示例:包存在
yum install mysql-server
示例:包不存在(镜像站RPM或源码编译方式)
通过wget方式下载repo源:
wget http://repo.mysql.com/mysql-community-***.***.rpm
安装:rpmrpm -ivh mysql-community-***.***.rpm
安装:mysqlyum install mysql-server
启动:mysqlservice mysql start
查看:mysqlps -ef | grep mysqld ps -ef | grep mysql netstat -anpt | grep mysql
登入:mysql
mysql -u root -p
示例:Navicat客户端外网连接创建用户(用于远程连接的用户)mysql>GRANT ALL PRIVILEGES ON *.* TO 'xxxx'@'%' IDENTIFIED BY 'xxxxxxxx' WITH GRANT OPTION;
刷新权限表
mysql>flush privileges;
切记安全-开启服务器的防火墙
systemctl start firewalld.service**描述:基于Lucene搜索服务器,提供了一个分布式多用户能力的全文搜索引擎,基于RESTful Web接口,基于Java语言开发,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎,能够达到实时搜索,稳定,可靠,快速,安装使用方便。**
温馨提示:为了保证正确安装和运行,如果可用内存过少,可能导致ES安装或启动失败。
查看:RAM内存
free -h
检查:硬盘空间
df -h
查看:目录下各文件夹磁盘占用率(ES的data目录指定可根据实际资源情况挂载)du --max-depth=1 -h /***/***
ES免安装:这里采用服务器间scp(互通)方式拷贝es安装包(若当前es中数据集较大-超出数10G,数据data目录也可一并离线迁移过来)
scp -r root@ip:/home/elasticsearch-6.8.6 /***/***/
云服务器:参数调整(root账户执行)
echo "fs.file-max = 6553560" >> /etc/sysctl.confecho "vm.max_map_count=655300" >> /etc/sysctl.conf
echo "vm.swappiness = 0" >> /etc/sysctl.conf
生效:
sudo sysctl -p
修改limits.conf文件:可自行根据实际资源情况对linux系统底层的多线程调整,允许es最大可以并发线程数
vim /etc/security/limits.conf
* soft nofile 524288
* hard nofile 524288
* soft nproc 131072
* hard nproc 131072
* -memlock unlimited其中每个进程最大同时打开文件数太小,可通过下面2个命令查看当前数量,这里修改了需要重新登录
su - yd
ulimit -Hn ulimit -Sn
若是没有用户:新增用户yd(为减少对操作系统的影响以及安全问题,不建议以root系统用户来安装和运行ES实例,可按下述创建一个专用的用户)
为yd用户创建密码:
passwd yd
赋权:yd用户能够访问ES相关文件夹
chown -R yd:yd /***/***/
修改配置:集群节点等各参数设置项
(cluster.name、node.name、network.host、http.port、path.data、path.logs、node.master、http.cors.allow-credentials...)vim /elasticsearch.yml
内存调整:最大堆内存,最小堆内存可自行根据实际资源情况调整
vim jvm.options
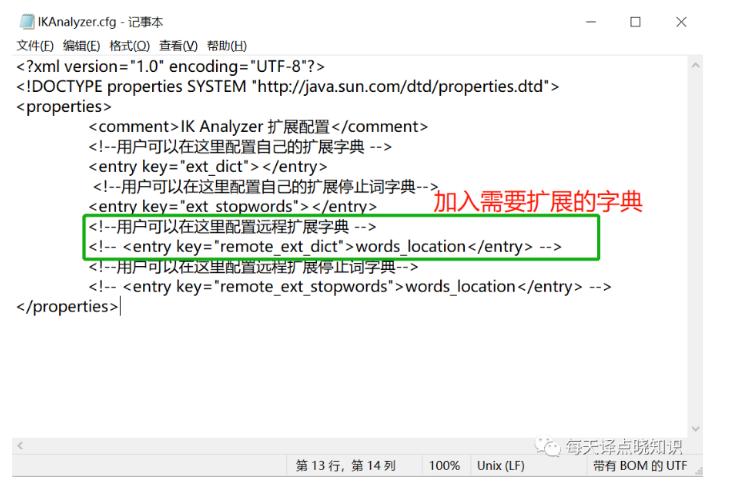
插件:IK分词可在plugins目录下,复制ik分词到当前路径/plugins/ik
漏洞:log4j版本升级可在lib目录下删除
log4j-1.2-api-2.11.1.jar、
log4j-api-2.11.1.jar、
log4j-core-2.11.1.jar
后找到相同名字,版本号不同的包进行替换启动:
ES./elasticsearch -d(后台启动方式,关闭终端服务正常运行)
查看:ES进程,能看到则表示正常,也可在终端(curl+链接)访问验证,其中
ES的http地址:当前服务器IP:9200,
ES的tcp地址:当前服务器IP:9300)
top -c 或 jps -l(查看java进程) 或 ps aux|grep ela(服务名)
附注:CPU调度基本单位-线程,线上CPU飙升排查或辅助JVM参数调优调整查找各个当前进程ID资源信息
top -c
查找当前进程内最耗费CPU的线程
top -Hp 进程ID
线程ID十六进制值转换
printf "%x\n" 线程ID
定位具体堆栈信息:输出进程ID的堆栈信息,然后根据线程ID的十六进制值grep
jstack 进程ID | grep 进制值**描述:数据可视化和挖掘工具,可以用于日志和时间序列分析、应用程序监控。**
Kibana免安装:这里采用服务器间scp(互通)方式拷贝kibana安装包
scp -r root@ip:/home/kibana-6.8.6-linux-x86_64 /***/***/
修改配置:参数设置项(server.host、server.name、elasticsearch.url...)vim /kibana.yml
启动:Kibana
nohup ./bin/kibana &(后台启动方式,关闭终端服务正常运行)
查看:kibana进程,能看到则表示正常,可在终端(curl+链接)访问验证,也可进入浏览器:当前kibana服务IP:5601)
ps aux|grep kibana描述:开源、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API,当下较为热门的查询性能缓存。
yum源方式安装:
示例:包存在
yum install -y redis
配置:/etc/redis.conf
启动:redis/usr/sbin/redis-server /etc/redis.conf 或 redis-server & 后台运行(使用默认端口)
日志:/usr/local/redis/logs/
查看:redisps -ef | grep redis
netstat -tunpl|grep 6379
登入:redisredis-cli -p 6379 --raw(中文数据正常显示)
redis-cli --help(其他参数查看)
关闭:redispkill redis
附:如果命令 which 和whereis 都找不到安装目录,可使用以下办法
ps -ef|grep redis
得到了进程号 xxxx
然后
ls -l /proc/xxxx/cwd描述:Nginx (engine x) 高性能、反向代理、轻量级web服务器。
yum源方式安装:
示例:包存在
yum install -y nginx ******
配置:/usr/local/nginx/conf/nginx.conf
启动:/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf日志:/usr/local/nginx/logs
查看:ps -ef | grep nginx
版本:/usr/local/nginx/sbin/nginx -v
验证:nginx进入浏览器:
http://公网IP Welcome to nginx!
重启:nginx ./nginx -s reload
关闭:pkill nginx
附:系统自启动-nginx(该设置方法也适用于CentOS其他程序-设置开机自启动)vim /etc/rc.d/rc.local
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
chmod +x /etc/rc.d/rc.local
(设置运行权限)描述:创建WEB页面或APP等界面呈现给用户,HTML、CSS、JavaScript以及衍生出来的各种技术框架体系VUE、React、解决方案等,来实现产品的用户界面交互。
开发:Visual Studio Code
运行:npm run serve
编译:npm run build
解压:/***/***/dist
配置:nginx加server
配置,监听端口,域名映射
访问:./nginx -s reload,浏览器访问验证描述:后端主要做的是业务逻辑,产品功能等模块,对于用户不可见,而 更多的是与数据库进行交互以处理相应过程,功能实现、数据的存取、平台的稳定可用性以及性能。
开发:IntelliJ IDEA
运行:nohup后台运行,正式生产环境-制作可执行sh脚本文件或容器自动化部署
nohup java -XX:MetaspaceSize=*m -XX:MaxMetaspaceSize=*m -Xms*m -Xmx*m -Xmn*m -Xss*k -XX:SurvivorRatio=8 -XX:+UseConcMarkSweepGC -Duser.timezone=GMT+08 -jar ***.jar >/dev/null 2>&1 &
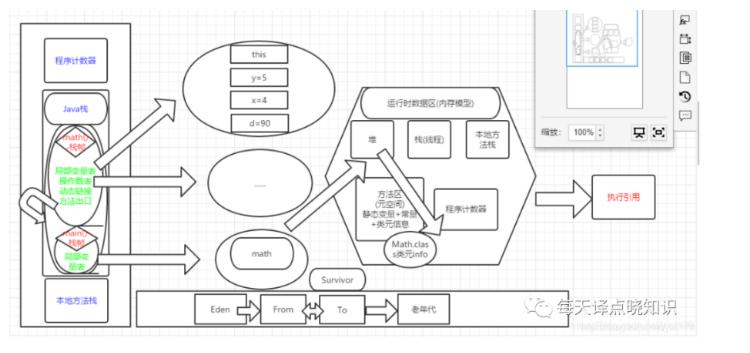
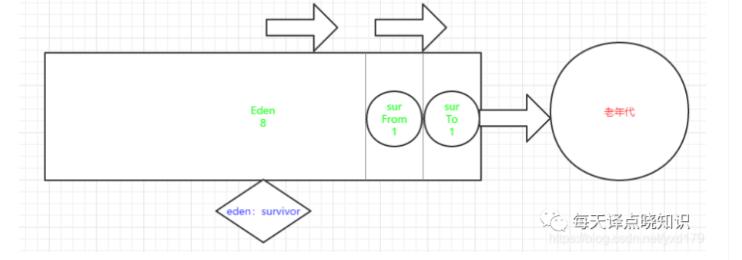
附:JVM参数年轻代分为1个Eden和2个Survivor区(一个是from,另一个是to)。
新创建的对象一般都会被分配到Eden区,若经过第一次GC后仍然存活,就会被移到Survivor区。Survivor区中的对象每经过一次MinorGC,年龄+1,当年龄增加到一定程度时,会被移动到年老代。Eden区域:占8份,两个survivor区域各占1份,即8:1:1(新生代中98%的对象很少存活下来,
因此设定10%的空间来存放活下来的,详细日志(-XX:+PrintGCDetails)、比例(-XX:SurvivorRatio=8)、(Xms)堆内存最小值、(-Xmx)堆内存最大值、(-Xmn)堆内存分配给新生代、(-XX:PermSize)设置持久代堆空间的初始值和最小值、-XX:MaxPermSize=<n>[g|m|k]设置持久代堆空间的最大值)。大多数的新生代都是采用的复制清除法作为垃圾回收算法,当对新生代进行minor gc(发生在新生代的垃圾收集动作,java对象大多都具备"朝生夕灭"的特性,所以Minor GC非常频繁,一般回收速度也比较快)时,会把Eden中和Survivor中的存活对象复制到另一块survivor区域中。-Xms*m => Java Heap内存初始化值 -Xmx*m => Java Heap内存最大值 -XX:PermSize => 永久带的初始值 -XX:MaxPermSize => 永久代的最大值 -Xmn => 新生代Mark

当千万乃至更大数据量,需像传统DBMS关系型数据库一样,实现在海量数据中作模糊搜索,全文搜索,又需要一定程度的检索效率,突破传统DBMS性能瓶颈?
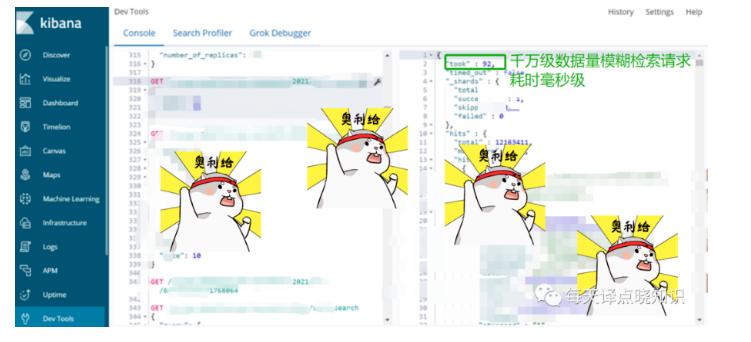
我们把搜索接口中的dsl语句放在kibana中执行,查看其请求耗时响应,由图可知模糊检索效率也极快,接口性能指标也基本在亚秒~毫秒级别。
诚然,ES很适合与关系型数据库形成互补,ES在搜索领域拥有强悍的性能,而传统DBMS关系型数据库分库分表组合查询相当麻烦,而ES组合灵活-自动路由(开发者无需在业务层作过多干涉)。
当然,在大数据量复杂查询的话,深度分页需要优化下,简单的查询几十亿问题不大,若超大则可上集群,再可上ES-ClickHouse.
猜想: 除了对服务器配置以及JVM内存的调优,ES搜索引擎为何如此之快?

举例: 现在,需要从我们的笔记搜索引擎中检索出一则七言律诗(七律-可以作为诗词检索的类型),用户输入关键词-长江,如何从海量的笔记记录中快速检索出关于长江的诗词?
《登高》
唐·杜甫
风急天高猿啸哀,渚清沙白鸟飞回。
无边落木萧萧下,不尽长江滚滚来。
万里悲秋常作客,百年多病独登台。
艰难苦恨繁霜鬓,潦倒新停浊酒杯。
在传统DBMS关系型数据库中,一般常用like %长江% ,这种需要遍历所有笔记记录数据作匹配-顺序扫描,不但检索效率较低,并且还只能搜索到长江连在一起的诗词,若是同时需要搜索到长、江、长江的诗词,like模糊匹配就还不能满足现有的需求了...
Ok,now,接下来,我们一起看看ES的倒排检索?
关键词 诗词
风 ------> 《登高》
江 **** ------> 《登高》
......... .........
这里仅简述下value->key的映射(暂不详述其索引构成,ES中term、match...),当我们需要从所有笔记中检索包含长、江、长江的诗词,就这样借助于倒排索引很快就可以直接得到到符合检索条件的结果-result。同时,这也就转换成了如何从海量的term查询其对应的term,若是term有序,二分查找?想必我们自学习语文知识以来,都用过很长一段时间的新华字典,查拼音,查偏旁部首,查询效率还是相当nice...
在前面安装环节,我们提到的IK分词插件目录,见->

一般搜索呈现给用户最终的结果,经历了这几个阶段->召回,排序(粗排、精排、重排-可根据具体业务规则制定),用户输入query检索得到搜索结果,主要来自于倒排以及语义召回,我们都知道,传统上的倒排检索严格依赖字面去作匹配,很难去召回一些同义或语义相似但字面意思不一样的结果。当然,较为传统的方式,我们可以追加人工干预召回,比如人工构建同义词进行替换等等。
Mark
JVM
堆栈=>堆内存,栈内存。
堆(heap): 主要用于存储实例化的对象,数组。由JVM动态分配内存空间。一个JVM只有一个堆内存,线程是可以共享数据的,堆内存可用来存放由new创建的对象和数组,在堆中分配的内存,由java虚拟机的自动垃圾回收器来管理。
栈(stack): 主要用于存储局部变量和对象的引用变量,每个线程都会有一个独立的栈空间,所以线程之间是不共享数据的。基本类型int, short, long, byte, float, double, boolean, char直接在栈中存储数值,而引用类型是将引用放在栈中,实际存储的值是放在堆中,通过栈中的引用指向堆中存放的数据。
年轻代 : Eden区 + 两个Survivor区(From和To)
Java扩展-本地内存(直接内存-堆外内存-jvm之外的内存)
当操作系统创建进程并给进程分配自己的虚拟地址空间,jvm用到的内存是从虚拟空间上分配,但jvm内存只是进程空间的一部分。
HeapByteBuffer接收->当把数据从内核先拷贝到一个临时的本地内存,再从临时本地内存拷贝到 JVM 堆,而不是直接从内核拷贝到 JVM 堆上->数据从内核拷贝到 JVM 堆的过程中,JVM 可能会发生 GC,GC 过程中对象可能会被移动,也就是说 JVM 堆上的字节数组可能会被移动,Buffer 地址就失效-本地内存中转。
DirectByteBuffer->DirectByteBuffer 对象本身在 JVM 堆上,但是它持有的字节数组不是从 JVM 堆上分配的,需谨慎回收问题...