

早在去年十一月就看到了站长素材网 ES 三周年征文活动,但仅限内部员工:https://cloud.tencent.com/developer/article/2155081,十二月后终于推出了全量的征文活动:https://cloud.tencent.com/developer/article/2192790
借此机会把自己日常使用 Elasticsearch 的经验分享给大家,以供参考。本文的主题是《Elasticsearch 索引速度评估与调优》,P.S. 此处的索引是动词(Verb)的意思即入库,而不是名词;本文后续会将 Elasticsearch 简写为 ES
之所以选择这个主题,主要源自于自己在工作中 2 次针对 ES 入库速度的 Benchmark 以及调优(第一次生产环境,第二次测试环境),期间花费了大量的时间和精力。之前有尝试过谷歌搜索,但网上的例文中所使用的 ES 版本大都是 6 或者更为古老的版本,而本文会以 8 版本(最新版即为 8 )进行举例
1. 评估环境
使用三台虚拟机搭建三节点集群,额外一台虚拟机用来单独运行 Benchmark 脚本。之所以这么做,主要还是为了避免 Benchmark 脚本占用资源,对 ES 集群产生负面影响
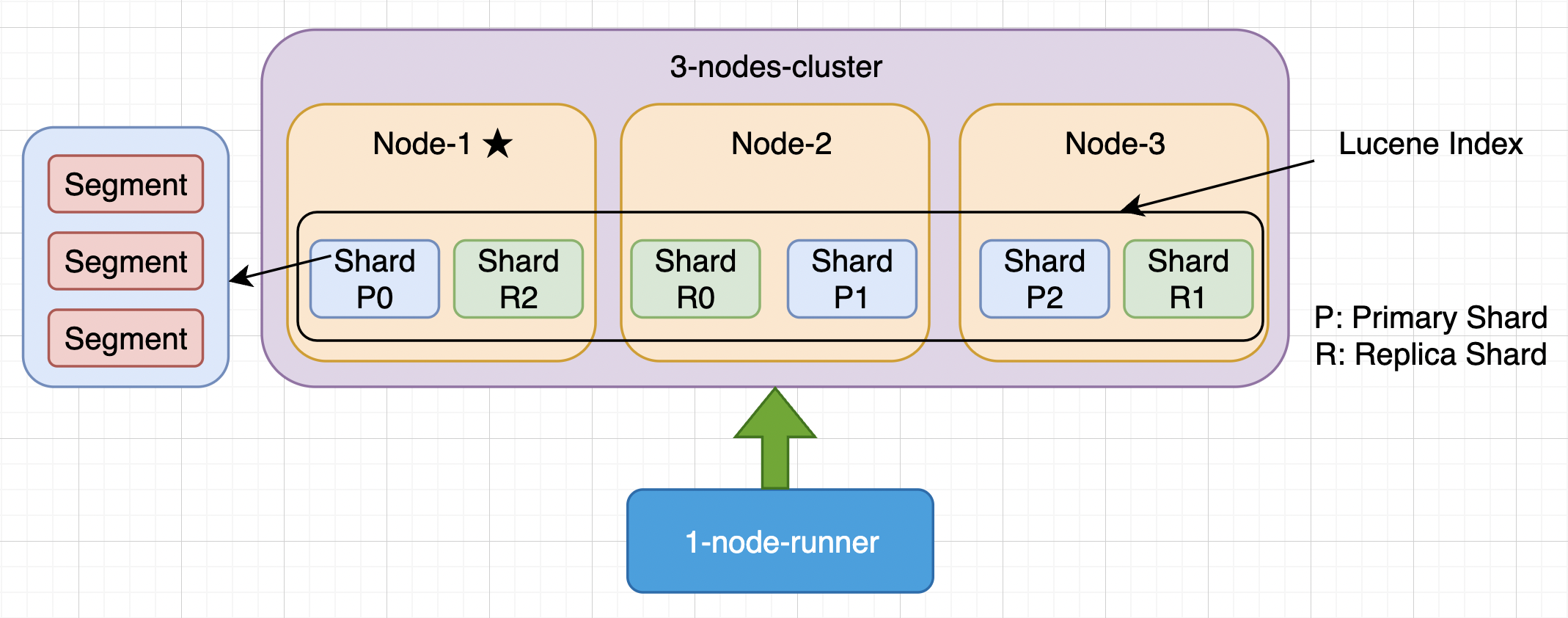
虚拟机使用的是固态硬盘(SSD),比机械硬盘(HDD)会快很多。
操作系统因为 CentOS 8 已经停止维护,所以现在全量迁移 Alma Linux 了
Kibana 内置的监控工具还是很好用的,就没有额外寻找 ES 对应的 exporter 再接入 Prometheus 了
毕竟是 Benchmark,要尽可能的增大写入速率。 实际使用了多进程创建多个 client 同时导入,逐渐增大要写入的总条数,最终速度应逐渐趋于稳定,也就是写入的上限
自己称这种为「定⻓测试」,还有一种测试叫「持久测试 」,现在只需要知道「持久测试 」主要是为了测试长期写入情况下的稳定性就可以了,之后会进行介绍
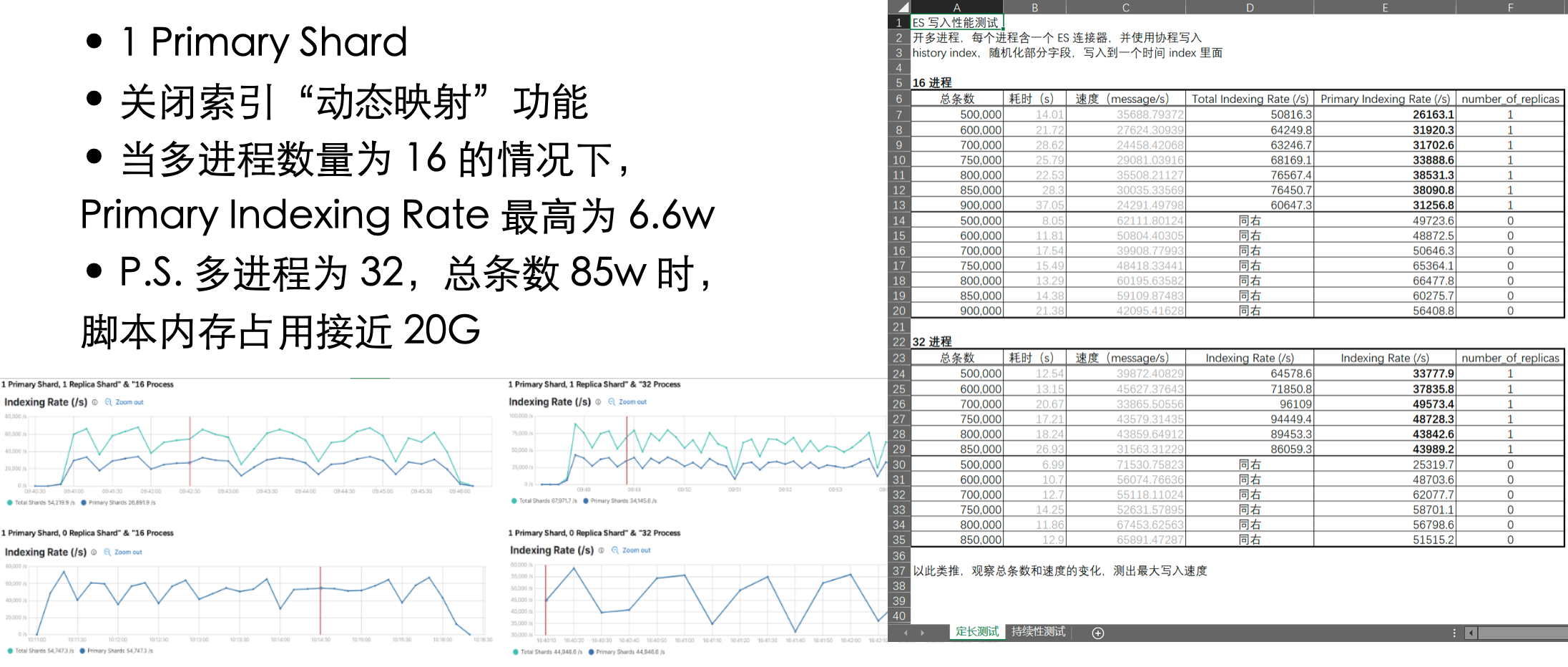
自己认为「定⻓测试」评估中的变量有三个:①总条数;②多进程数量:16 或 32;③副本集数量:0 或 1
评估前列出下表,然后根据实际结果填表,最终进行数据分析
即指标题中的索引,要把大象装进冰箱需要几步?没错,这里也是 3 步
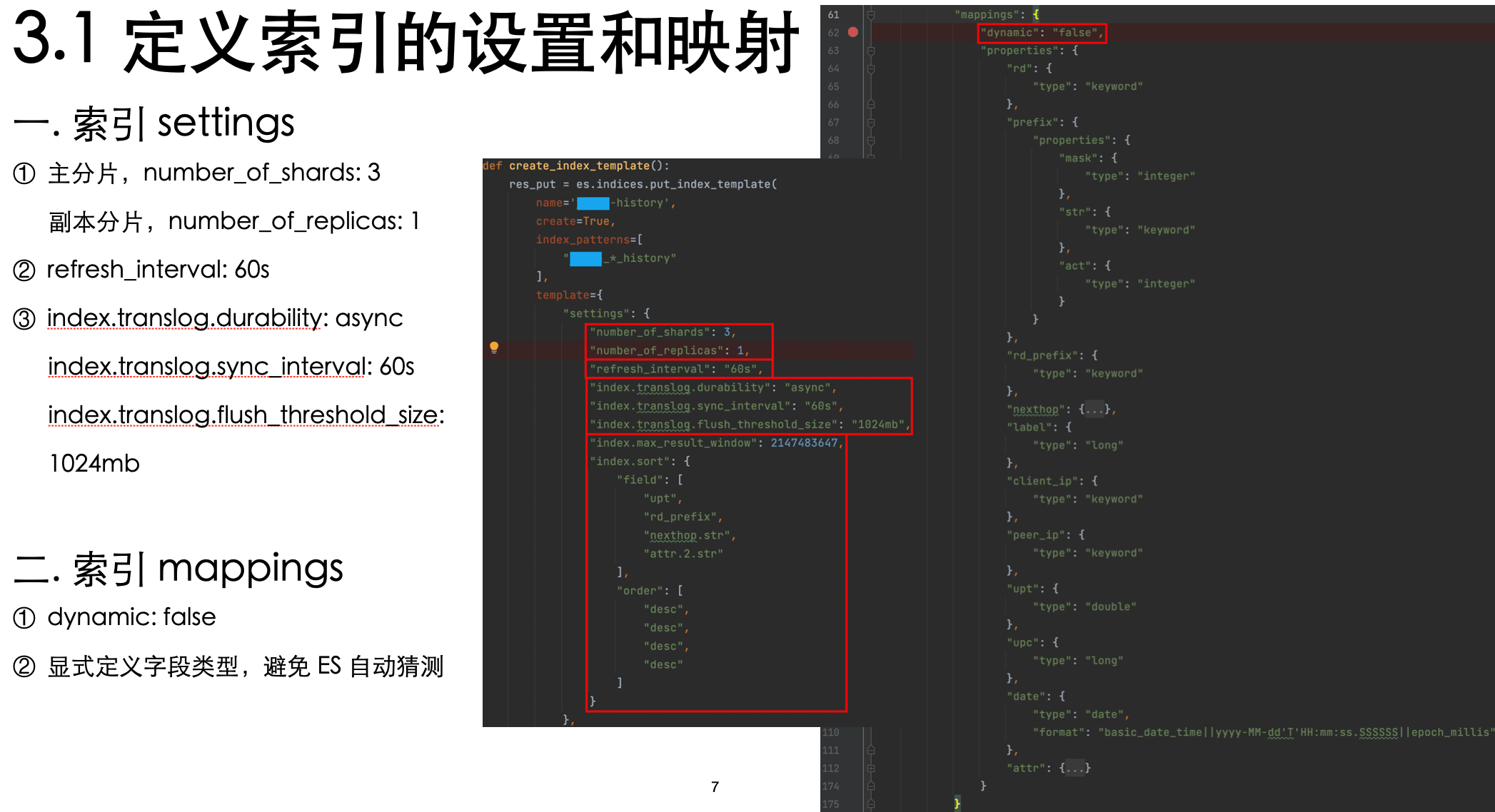
1. 定义索引的设置和映射
设置:
①三节点集群,主分片设置为 3 & 副本分片设置为 1,根据 ES 的分片分配规则,每个节点上会有俩分片,一个主一个副本
②refresh_interval,即多长时间后数据才是可搜索到的,因实际场景对于实时性没有严格要求,此处设置为 60s
③translog 相关,参考自谷歌的搜索结果,如有更好的建议欢迎提出
映射:
①关闭 dynamic 开关
②人工指定每个字段的数据格式,不需要 ES 进行字段类型智能猜测,因为实测会影响索引效率
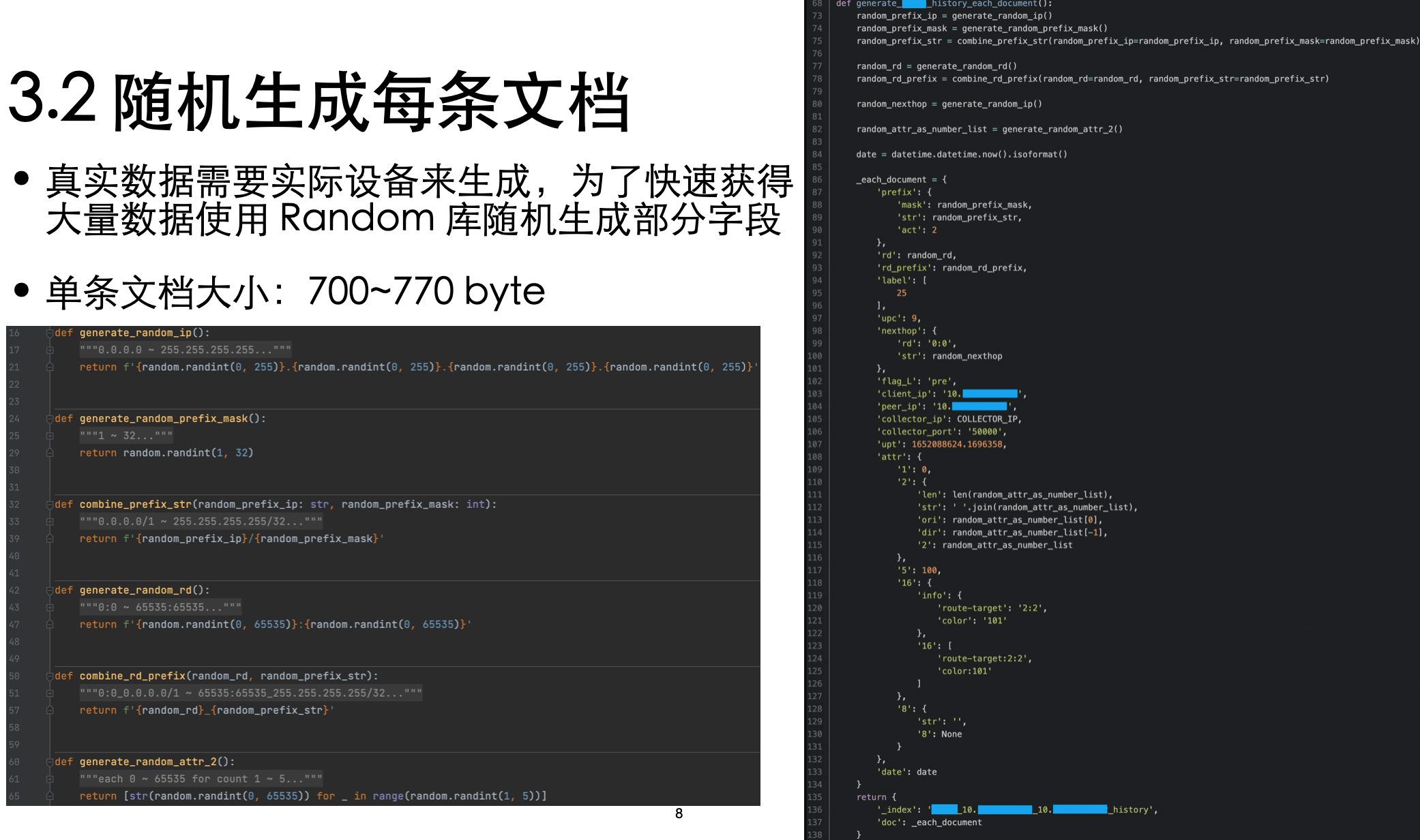
2. 随机生成每条文档
有条件的话当然要用生产环境了,毕竟与现实越接近越好嘛。但因为环境原因,只能自己造大量数据了
然后将部分字段随机化(随机化使用的是 random 方法)以模拟现实环境的情况
3. Bulk 批量索引至 Elasticsearch 集群
举个例子,1000 条 json 一次性入库 & 1000 条 json 分 1000 次入库,显然后者的 IO 操作大得多,因此效率明显没有前者高,也就是需要使用 Bulk
关于 Bulk,官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html#docs-bulk
其实就是多个操作按照换行依次罗列出来,多个操作不需要必须是相同类型的,比如下图中既有索引(index)也有删除(delete)操作
自己使用的是 Python 的客户端,有提供了 bulk 的方法,可以直接调用

并且还使用了多进程 + 协程,最大化写入速度,不能让 Benchmark 脚本先出现瓶颈,那样就测不到 ES 的写入速度上限了
需要注意的是内存,不管是脚本还是 ES 应用程序,都可能导致 OS OOM
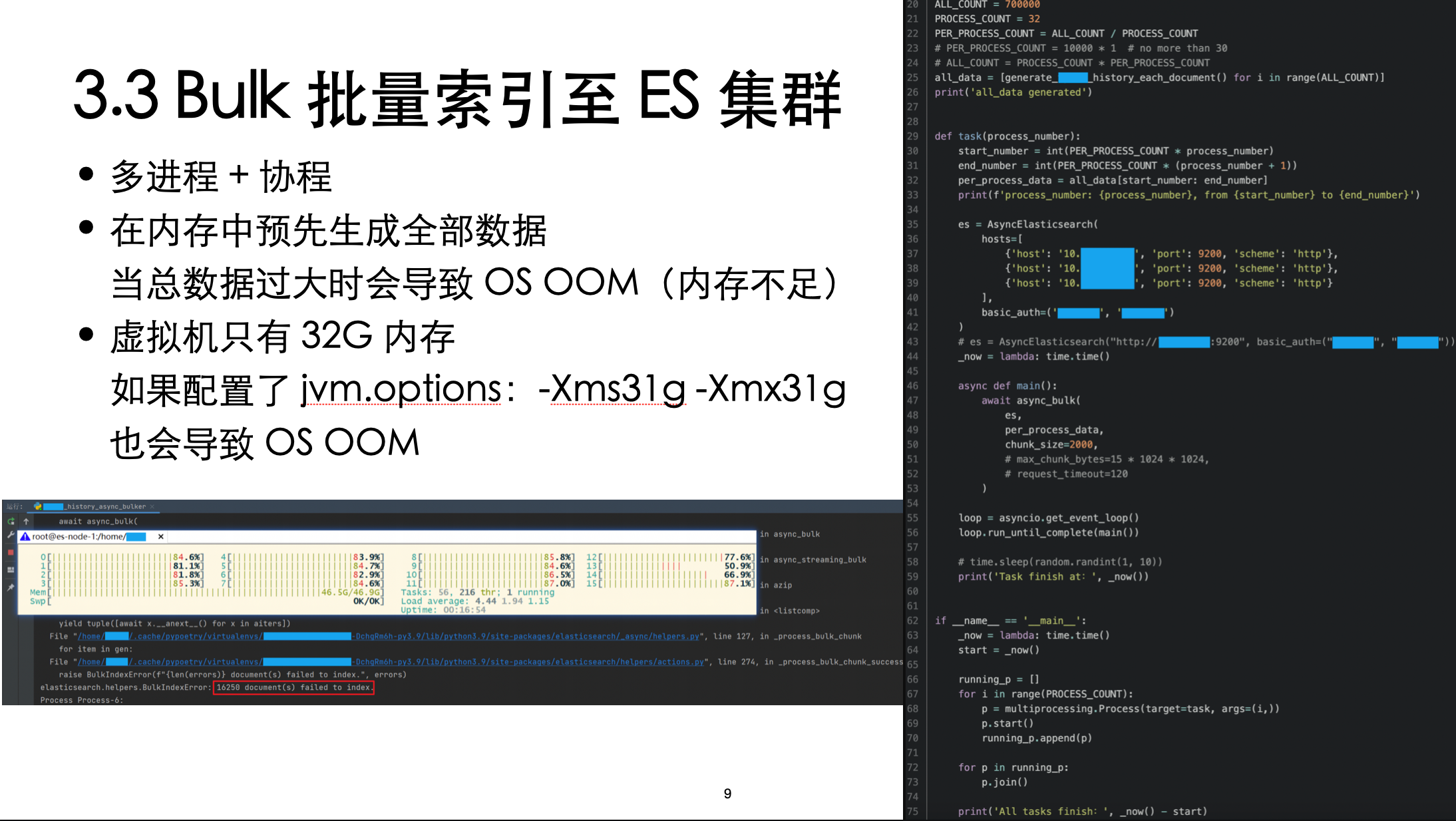
需要说明的是,初测时仅分配了 1 个主分片,并未使用 3 个主分片,因此结果仅供参考
虽然但是,也能看出单节点(1 个主分片)写入上限是每秒五六万的样子,理论上三节点(3 个主分片)不会超过 15~18w/s
根据调优漏斗,效果自上而下递减,这里主要有 3 点方向
ES 官方文档有 2 篇关于调优的文章,一定要读一下
Tune for indexing speeded:https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html
Tune for disk usage :https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-disk-usage.html

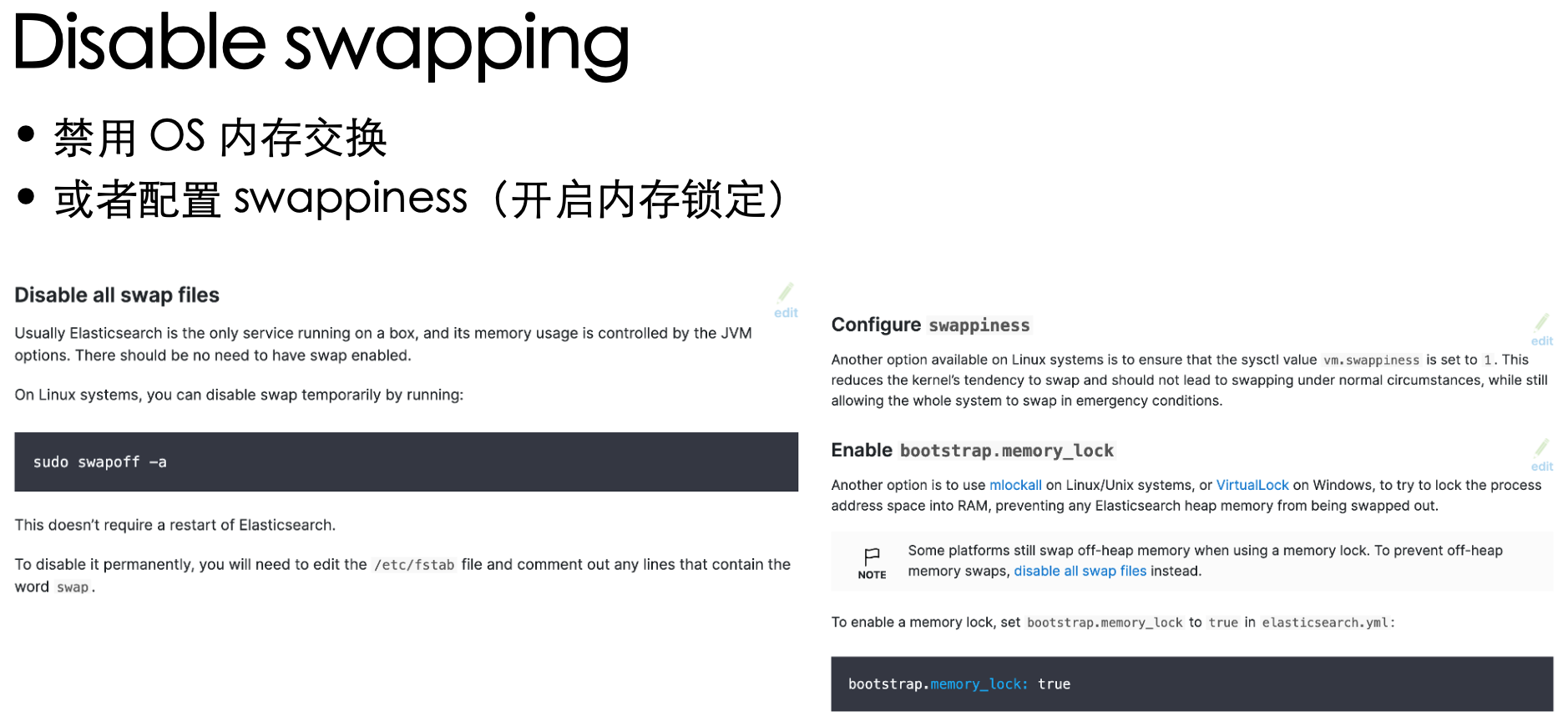
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/system-config.html
✅ 为实际进行配置了的项目,接下来依次进行介绍

在 systemd 的单元文件中 添加 LimitMEMLOCK=infinity

如果集群只跑 ES:推荐下图左;如果还跑其他业务:推荐下图右
针对自己的环境,无需额外操作有仨



官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html
✅ 为实际进行配置了的项目,接下来依次进行介绍

只要 ES 不出现 429 写入拒绝,就没问题。但如果增大请求对写入速度的提升已经变化不大了,建议「选小不选大」

这里是针对 Python 的客户端的两个参数,需要针对实际环境进行调整

trunk_size 自 100 起每次翻倍,发现 3200 和 6400 的差别不大,本着「选小不选大」的原则选择 3200
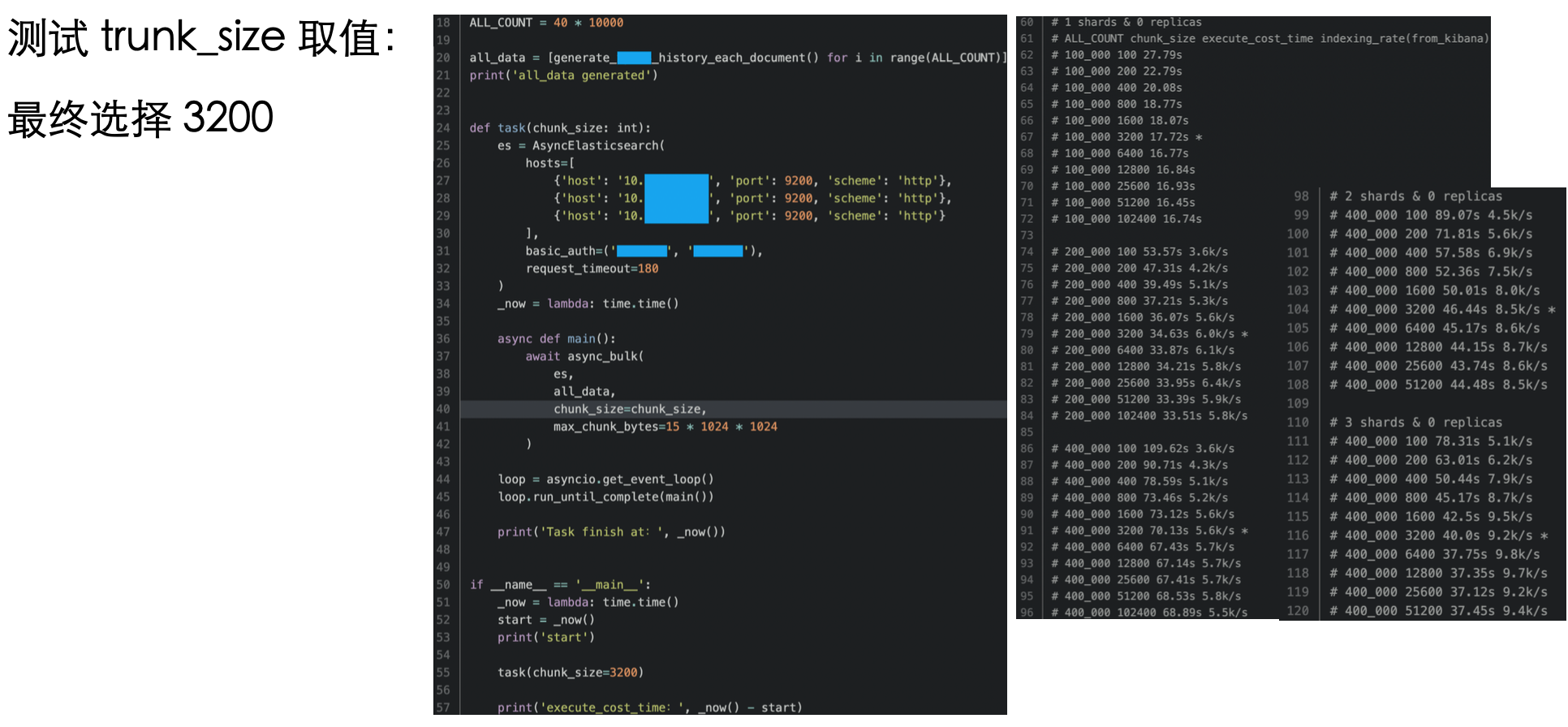
针对 Python,可以使用生成器,以避免 benchmark 脚本自身占用过多内存导致 OS OOM
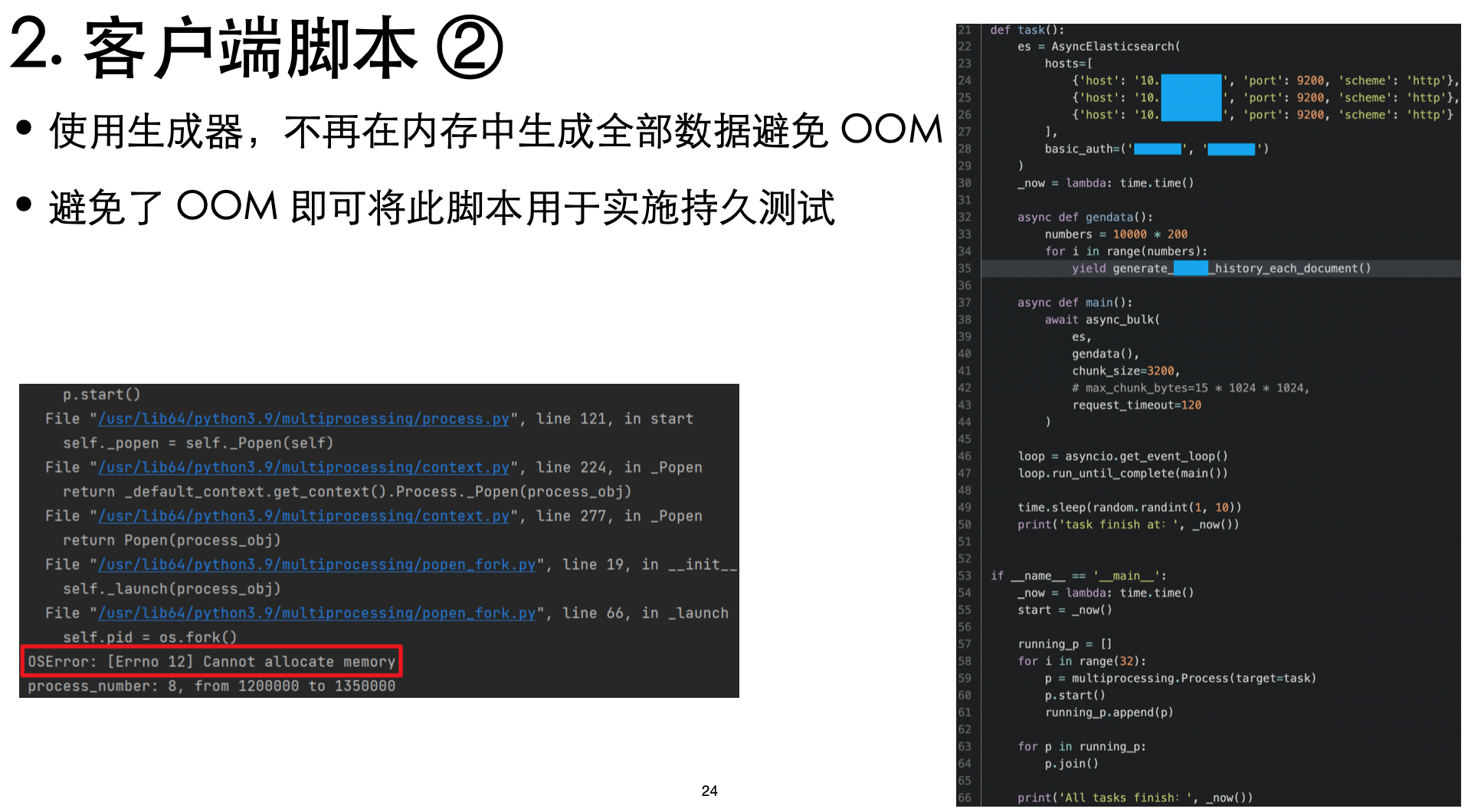
refresh interval 之前说过了,不再赘述

内存交换和更快的硬件之前也有说过,其实该注意的点也就这些,熟悉之后就会发现八九不离十

官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html
✅ 为实际进行配置了的项目,接下来依次进行介绍

ES 针对使用者本着开箱即用,提供了一些“智能”的功能。对于自己这类“老手"来说,并不需要这些“智能”的功能
有利必有其弊!那么,代价是什么呢?比如 danamic mappings 就会降低索引的速度

Dynamic field mapping 有三种设置值,影响的是在索引文档时,遇到未映射的字段要怎么处理
在已知所有字段的类型时,建议使用 false
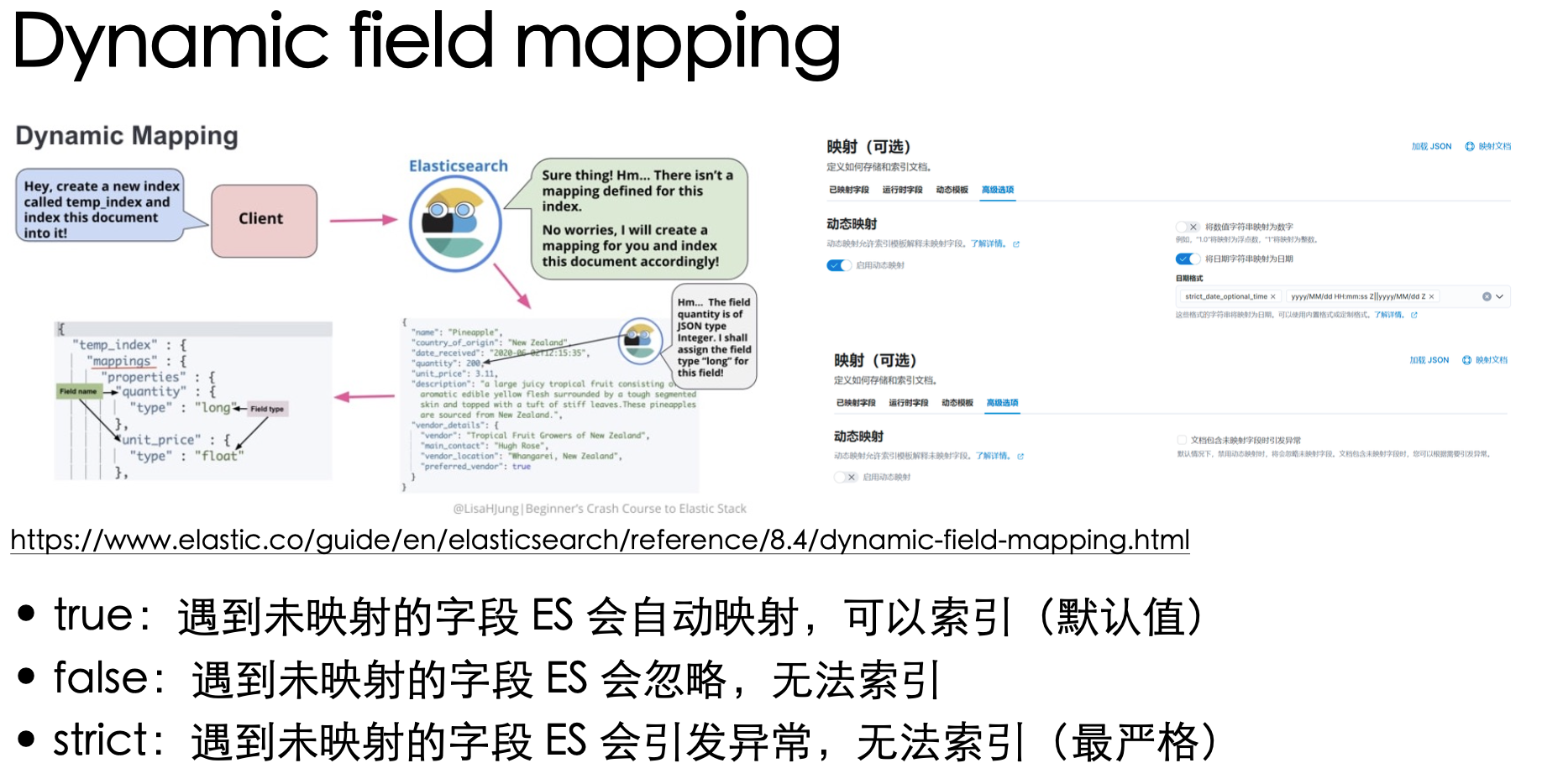
带来的好处不仅有提升索引速度,还会减小存储大小

通过 Kibana 的监控可以明显的看出,当有未映射的字段时,ES 会消耗额外的资源去猜测字段类型,索引速度降低
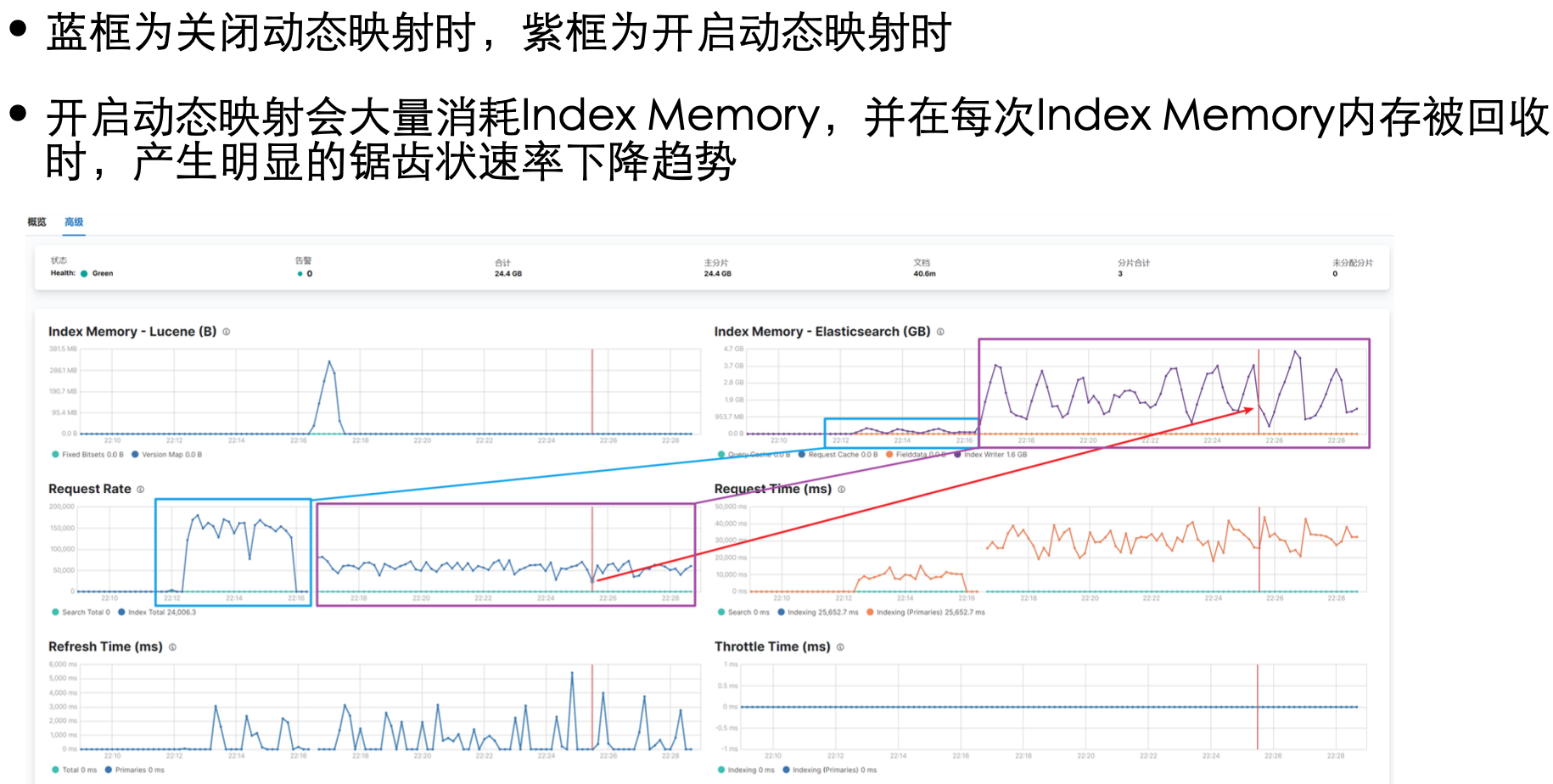
基于【3 主分片 0 副本分片,32 进程 + 协程】的情况下 ①持续写入64,000,000 数据维持 15w+/s 的索引速度,存储占用 9.15GB
②而不禁用动态映射的情况下,6w/s 的索引速度,存储占用 30.1GB
测试代码参考: https://github.com/yuangezhizao/elasticsearch-capacity-assessment
感谢站长素材网与 Elasticsearch 合作三周年之际发起的《站长素材网 x Elasticsearch 携手三周年有奖征文大赛》,自己得以机会用文字版的形式将这个主题整理完成,分享给大家以供参考
祝云 + 社区越来越好,未来举办更多的征文活动!
