

singlefilght ,在go标准库中("golang.org/x/sync/singleflight")提供了可重复的函数调用抑制机制。通过给每次函数调用分配一个key,相同key的函数并发调用时,只会被执行一次,返回相同的结果。其本质是对函数调用的结果进行复用
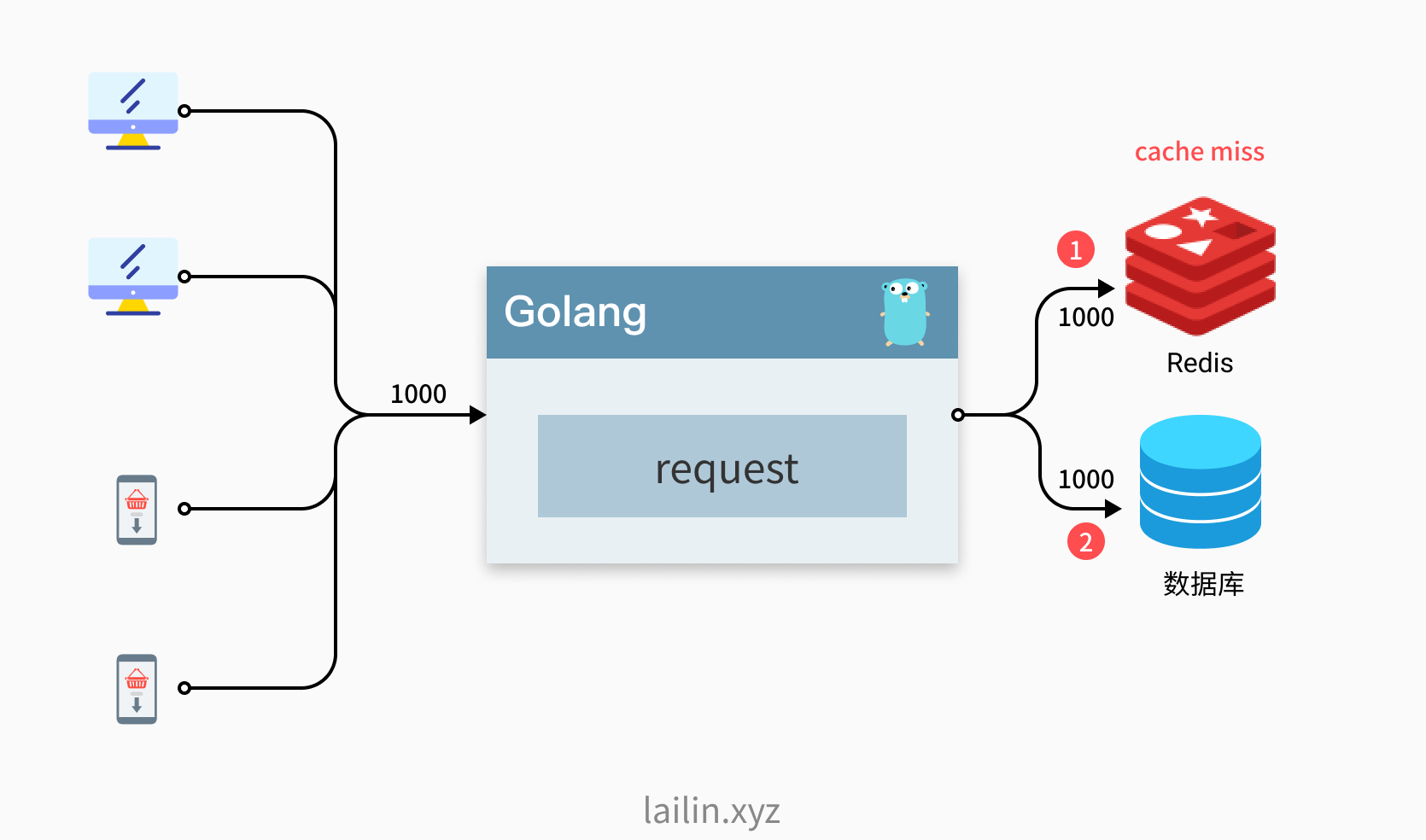
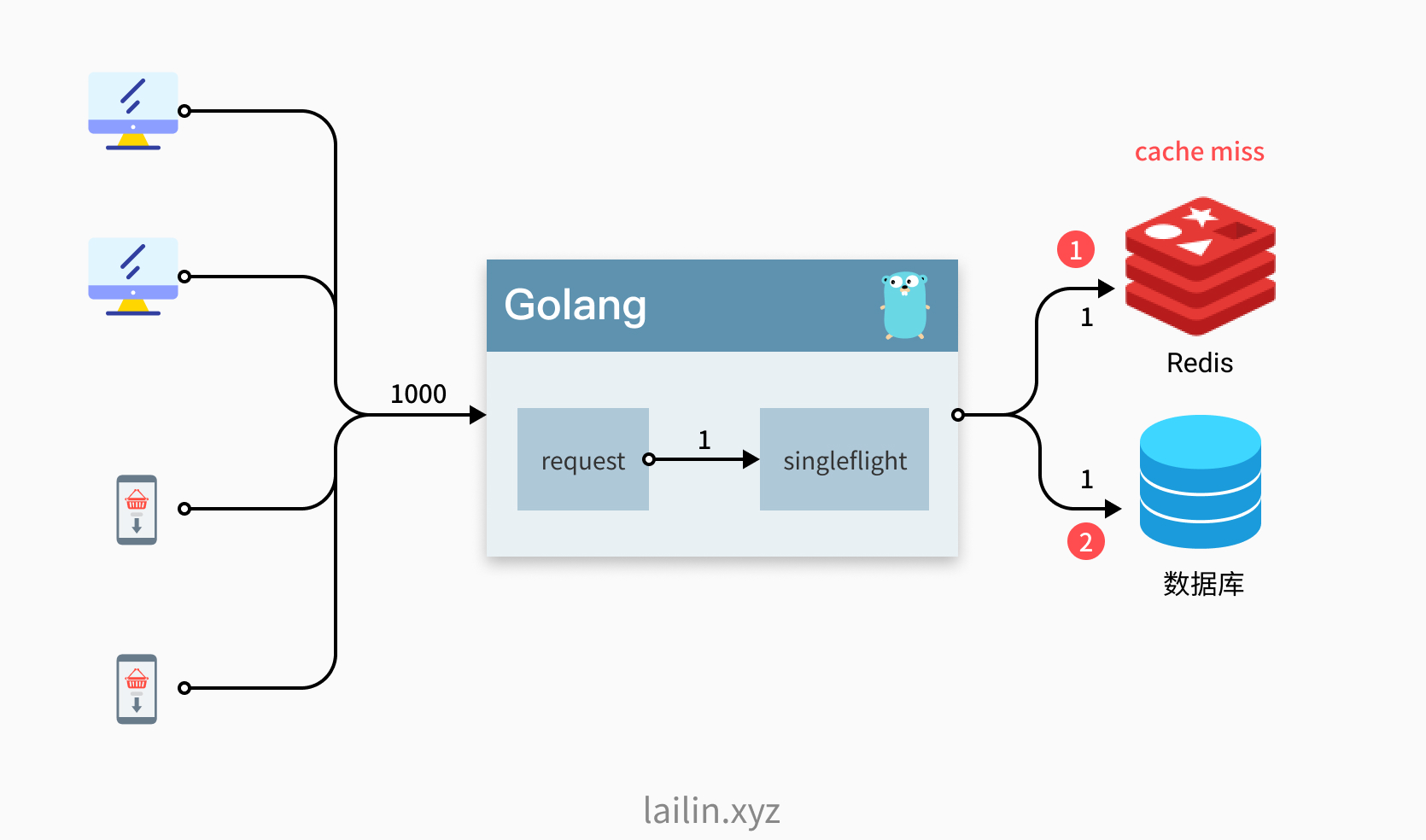
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
场景做法是使用互斥锁,但是会影响性能。通过singlefilght可以有效合并重复请求,避免数据库被打爆
与一致性hash负载均衡配合组成一个特殊的服务。用户根据key使用一致性hash请求到特定的服务机器上,服务对请求执行singlefilght后,再去请求下游,以此收束重复请求。
// 普通调用方法
func callFunc(i int) (int,error) {
time.Sleep(500 * time.Millisecond)
return i, nil
}
// 使用singleflight
// 1. 定义全局变量
var sf singleflight.Group
func callFuncBySF(key string, i int) (int, error) {
// 2. 调用sf.Do方法
value, err, shared := sf.Do(key, func() (interface{}, error) {
return callFunc(i)
})
res, _ := value.(int)
return res, err
}singleflight的本质是对某次函数调用的复用,只执行1次,并将执行期间相同的函数返回相同的结果。由此产生一个问题,如果实际执行的函数出了问题,比如超时,则在此期间的所有调用都会超时。由此需要一些额外的方法来控制
// 使用DoChan进行超时控制
func CtrTimeout(ctx context.Context, req interface{}){
ch := g.DoChan(key, func() (interface{}, error) {
return call(ctx, req)
})
select {
case <-time.After(500 * time.Millisecond):
return
case <-ctx.Done()
return
case ret := <-ch:
go handle(ret)
}
}在一些对可用性要求极高的场景下,往往需要一定的请求饱和度来保证业务的最终成功率。一次请求还是多次请求,对于下游服务而言并没有太大区别,此时使用 singleflight 只是为了降低请求的数量级,那么使用 Forget() 提高下游请求的并发。
// 另外启用协程定时删除key,提高请求下游次数,提高成功率
func CtrRate(ctx context.Context, req interface{}){
res, _, shared := g.Do(key, func() (interface{}, error) {
// 另外其一个goroutine,等待一段时间后,删除key
// 删除key后的调用,会重新执行Do
go func() {
time.Sleep(10 * time.Millisecond)
g.Forget(key)
}()
return call(ctx, req)
})
handle(res)
}使用此方法,原本要所有调用到等待第一次执行完成,现在10ms后的调用会重新开始执行,频率被限制到了最慢10ms一次。
源码:https://cs.opensource.google/go/x/sync/+/f12130a5:singleflight/singleflight.go
// Group 对外的核心结构体
type Group struct {
mu sync.Mutex // 保护 m
m map[string]*call // lazily initialized
}
// Do 执行函数, 对同一个 key 多次调用的时候,在第一次调用没有执行完的时候
// 只会执行一次 fn,其他的调用会**阻塞**住等待这次调用返回
// v, err 是传入的 fn 的返回值
// shared 表示fn的结果是否被共享
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool)
// DoChan 和 Do 类似,只是 DoChan 返回一个 channel,也就是同步与异步的区别
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result
// Forget 用于通知 Group 删除某个 key 这样后面继续这个 key 的调用的时候就不会在阻塞等待了
func (g *Group) Forget(key string){
g.mu.Lock()
if c, ok := g.m[key]; ok {
c.forgotten = true
}
delete(g.m, key)
g.mu.Unlock()
}其将调用对象封装为call ,每个key对应一个call
// call is an in-flight or completed singleflight.Do call
type call struct {
wg sync.WaitGroup
// val和err是用户调用返回的字段,(err包括panic err)
// 其在wg.done之前只被写入一次
// 在wg.done之后,只能被读取
val interface{}
err error
// 如果执行过Forget,则会被设置为true,避免重复delete
forgotten bool
dups int // 此call被额外调用的次数,也是结果被额外共享的次数(不算首次)
chans []chan<- Result //DoChan的结果数组,用于一次执行后,给所有结果传值
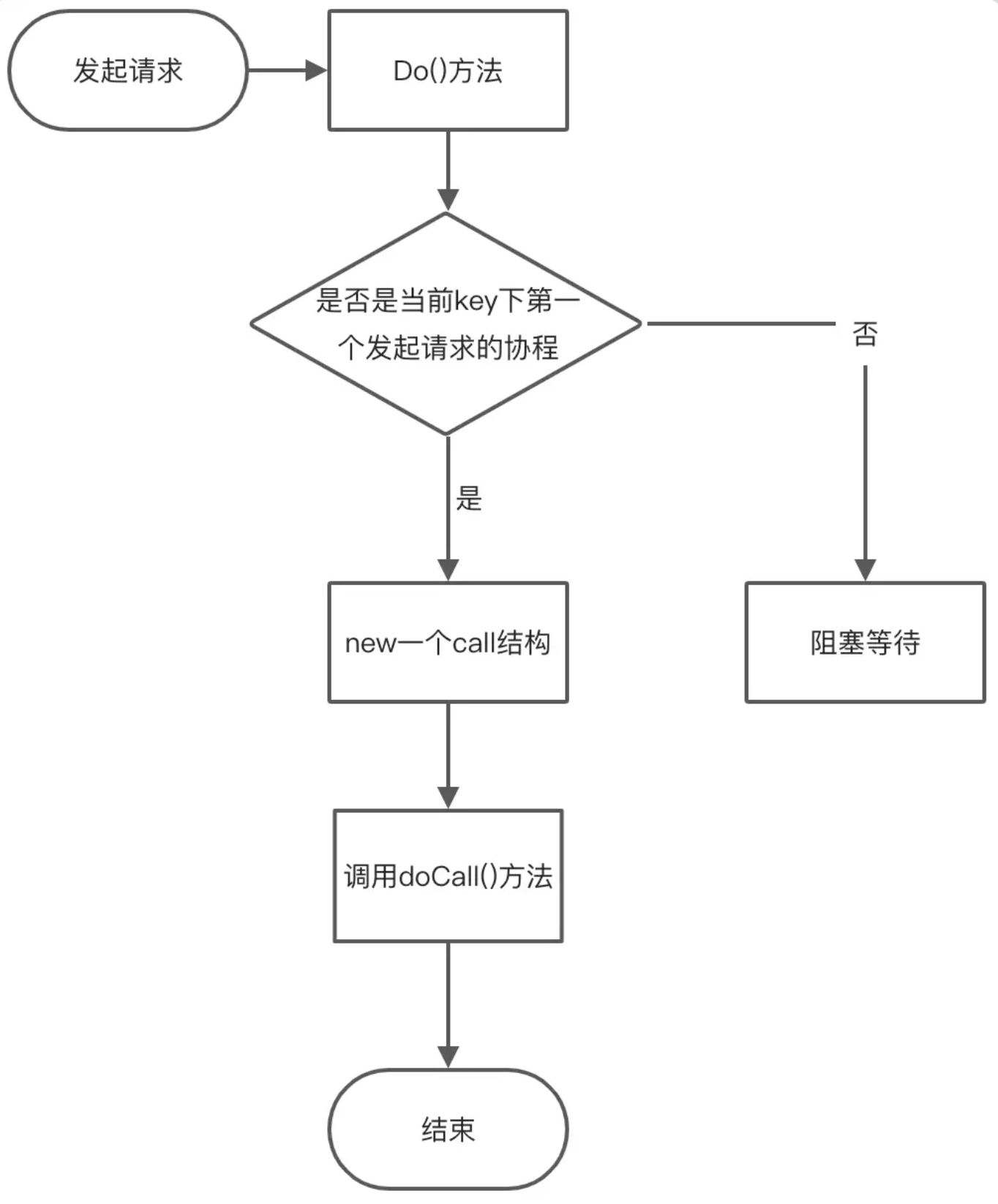
}Group.Do是核心函数
核心视图
// Do 内部没有额外的goroutine执行,故panic可以被捕获
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
// 1. 加锁并懒加载内部变量
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
// 2. 如果callMap里存在这个key,说明直接在此之前此函数**正在被调用**
// c为singleflight封装的call结构体
if c, ok := g.m[key]; ok {
c.dups++ // 2.1 记录此call被执行的次数+1
g.mu.Unlock() // 2.2 释放锁,让之后被调用的函数也进来
c.wg.Wait() // 2.3 阻塞在这里,等待函数调用完成
// 2.4 函数调用完成,进行错误处理,区分系统错误or用户错误
if e, ok := c.err.(*panicError); ok {
panic(e)
} else if c.err == errGoexit {
runtime.Goexit()
}
// 2.5 返回函数执行结果,其结果必定是共享的结果
return c.val, c.err, true
}
// 3. 首次调用,新建call
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock() // 完成对map操作
// 4. 执行fn函数,并将执行结果返回,并调用c.wg.Done(), 也会删除callMap里对应的key
g.doCall(c, key, fn)
return c.val, c.err, c.dups > 0 // c.dups代表此call被额外调用次数,>0说明结果共享
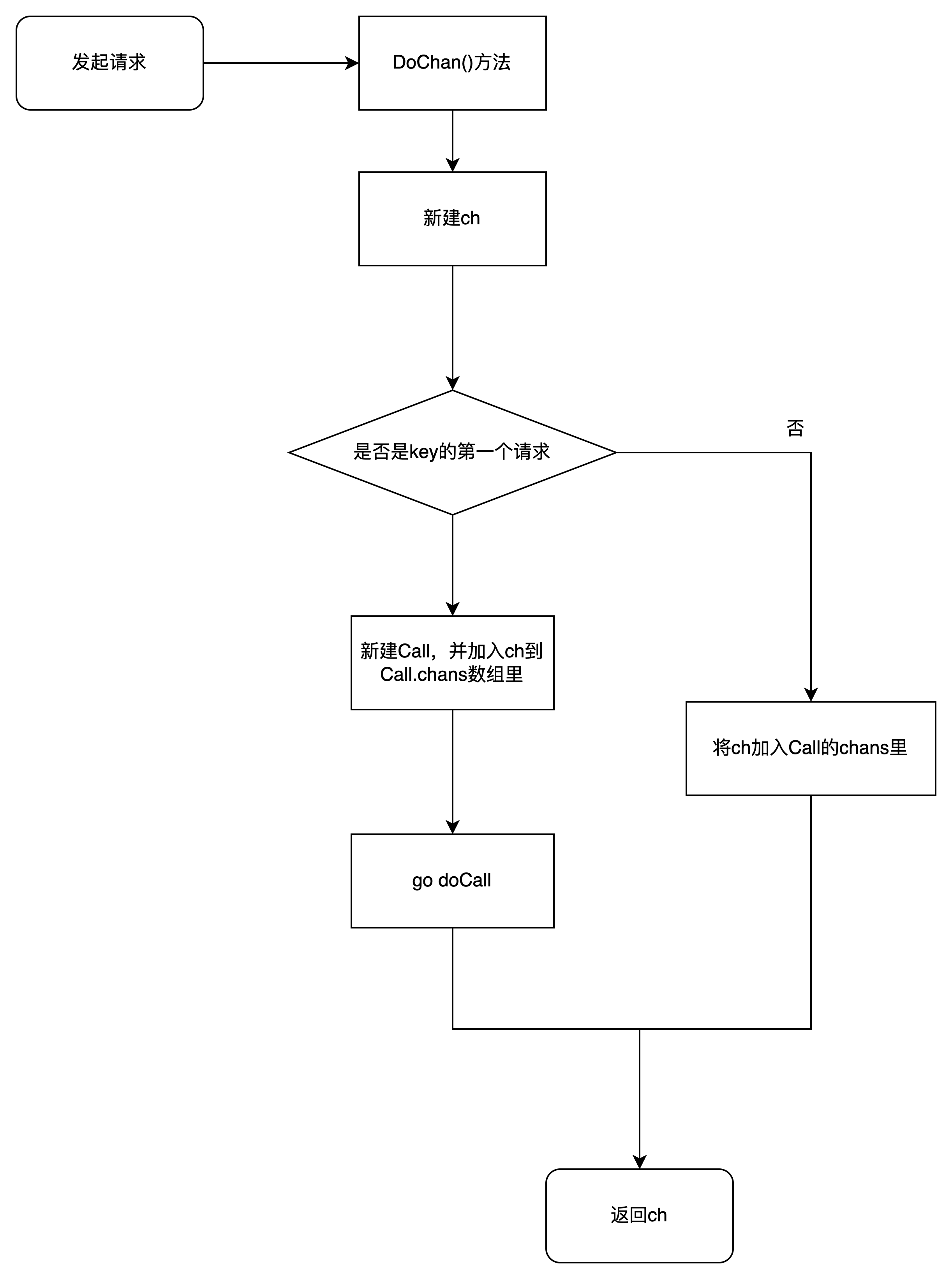
}DoChan接口返回Result类型的chan,以此提供异步调用的能力
// 给DoChan的返回封装的结果,
type Result struct {
Val interface{}
Err error
Shared bool
}
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result {
// 本次执行的结果,一次调用只有1个
ch := make(chan Result, 1)
// 1. 加锁并懒加载内部变量
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
// 2. 如果此key对应的函数已在执行
if c, ok := g.m[key]; ok {
c.dups++
// 将此结果加入call(此处的c)的结果数组
c.chans = append(c.chans, ch)
g.mu.Unlock()
return ch
}
// 3. 如果是首次执行,创建call,加入到Group的CallMap里
// 之所以是结果数组,是为了用于doCall一次执行后,给所有结果传值
c := &call{chans: []chan<- Result{ch}} // doCall内部只准写入值
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
// 4. 开goroutine通过doCall执行fn
// 执行完成后会调用c.wg.Done(), 也会删除callMap里对应的key
go g.doCall(c, key, fn)
return ch
}Group.doCall执行了fn函数,返回结果
// 原始写法,存在panic未处理和死锁问题
func (g *Group) doCall(c *call, key string, fn func() (any, error)) {
// 1. 执行
c.val, c.err = fn()
// 2. 执行完成后,立刻通知其他等待的goroutine获取结果
c.wg.Done()
// 3. 删除key,之后的函数重新执行调用
g.mu.Lock()
delete(g.m, key)
// 4. 将得到的结果写入结果数组里的每个chan
for _, ch := range c.chans {
ch <- Result{c.val, c.err, c.dups > 0}
}
g.mu.Unlock()
}上述代码是在internal/singlefilght库里的,其存在安全问题:
对于c.wg.Done() ,2种情况不会被执行:
fn()发生panicfn()内部执行runtime.Goexit()此时,其他等待返回结果的**goroutine**会一直等待,导致死锁。所以需要将**Done**操作放在**defer**里。
此外,为了避免chan因为panic 被recover而无法被写入导致死锁,需要对chan场景执行 go panic() 来确保一定被panic且不可被recover。由此,需要区分panic和Goexit,对panic进行预期的操作。
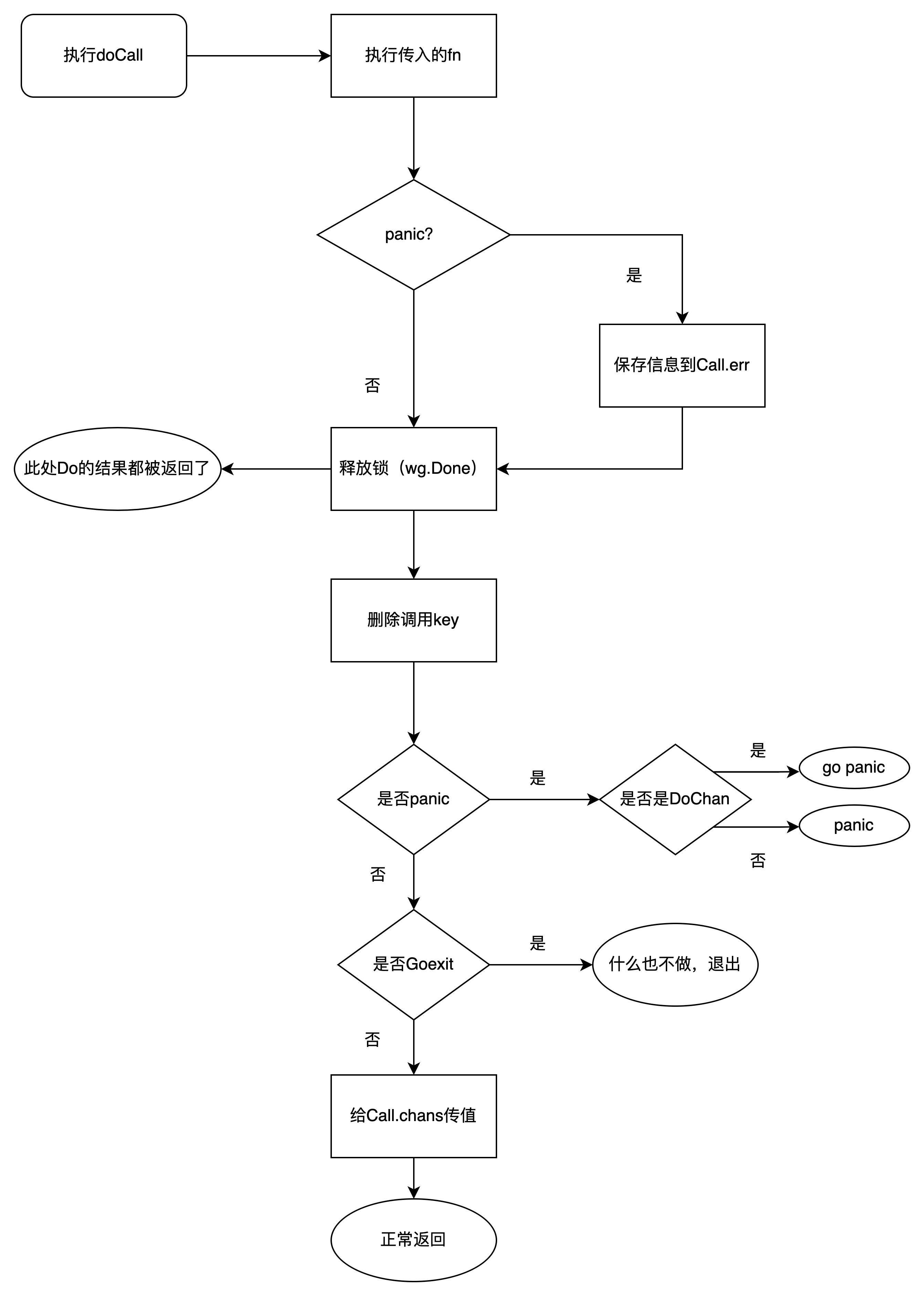
// doCall handles the single call for a key.
func (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) {
normalReturn := false
recovered := false
// 3. 执行第二个defer,对panic或Goexit统一处理
defer func() {
// 既不是普通返回,也不是recover,排除法得到Goexit
if !normalReturn && !recovered {
c.err = errGoexit
}
// 3.1 执行完成,返阻塞在调用Group.Do调用
// Group.Do的部分到这里就返回结果了
c.wg.Done()
// 3.2 加锁删除key
g.mu.Lock()
defer g.mu.Unlock()
if !c.forgotten {
delete(g.m, key)
}
// 3.3 处理panic
if e, ok := c.err.(*panicError); ok {
// DoChan调用
// 由于ch发生了panic,ch不会被写入,goroutine会一直阻塞,导致死锁
// 这里通过go panic的方式保证必定panic,
// 预防调用Group.DoChan后,外部recover导致死锁的问题
if len(c.chans) > 0 {
go panic(e)
select {} // 保留这个goroutine到核心存储
} else { // Do 调用,直接panic
panic(e)
}
// 3.4 处理Goexit
} else if c.err == errGoexit {
// 已经准备退出了,没有啥要处理的,资源在之前就已经释放完成了
// 3.5 处理正常情况下的DoChan结果
} else {
for _, ch := range c.chans {
ch <- Result{c.val, c.err, c.dups > 0}
}
}
}()
// 1. 首次执行此函数
func() {
defer func() {
// 1.3 判断是否为正常返回
if !normalReturn {
// 非正常返回则recover,保留堆栈信息
// 在下一个defer里统一处理 panic or Goexit
if r := recover(); r != nil {
c.err = newPanicError(r)
}
}
}()
// 1.1 执行fn
c.val, c.err = fn()
// 1.2 执行成功则设置正常返回
normalReturn = true // 如果fn() panic 或者 Goexit则不会执行此步骤
}()
// 2. 由于panic被第一个defer recover了,可以执行到此
// Goexit会直接执行下一个defer
if !normalReturn {
recovered = true
}
}// 模拟并发请求
go func(wg *sync.WaitGroup) {
// 3. 某个并发调用,释放锁
defer wg.Done()
// 4. 处理panic
// Do内部没有另外执行的goroutine,所以可以被捕获
defer func() {
if r := recover(); r != nil {
// 此处可以捕获到panic. 由 doCall 方法中捕获后再次抛出的异常
fmt.Println("[[[", r, "]]]")
}
}()
// 1. 执行Do,返回结果
val, err, _ = g.Do("getdata", func() (interface{}, error) {
panic("panic")
return "hello", nil
})
// 2. 处理结果
handle(val)
.....
}(wg)而DoChan的场景比较特殊,其panic无法被处理
// 模拟并发请求
go func(wg *sync.WaitGroup) {
// 4. 处理panic
// doCall内部对于DoChan使用了go panic,此时无法被recover
defer func() {
if r := recover(); r != nil {
fmt.Println("[[[", r, "]]]")
}
}()
// 1. 执行Do,返回结果
ch := g.DoChan("getdata", func() (interface{}, error) {
panic("panic")
return "hello", nil
})
// 2. 处理结果
go func(){
// 3. 此结果完成,执行done
defer wg.Done()
str <- ch
}
.....
}(wg)使用ch一般是异步使用,开一个goroutine去监听ch并执行。如果发生panic被recover,这ch永远不会被写入值,此goroutine就会僵死在这里。如果持有了锁,则会造成死锁。
故doCall内部对DoChan场景下的panic直接另外其一个goroutine去panic,保证无法被recover。
singleflight为了解决请求去重的问题,使用了map[key]call 结构体,并且通过锁解决call访问的并发问题。每次请求到来,都会去根据key获取call的信息。
call内部使用了WaitGroup来管理各个并发请求,首次请求执行add和done操作,其他请求wait首次请求完成(Do接口)。
对于异步控制,其对chan的使用非常经典。将chan的写接口传入goroutine进行写操作,读接口交由用户自己控制。
作为涉及到并发的框架,sf给了我们处理用户自定义函数fn 的启示。在go里面,影响函数正常执行流程主要有3种场景:
err一般作为正常执行逻辑的一部分,框架透传给业务方。而对于panic和Goexit则属于程序异常,需要并发框架格外关心,核心涉及到2个维度:
defer wg.Done() 防止阻塞 > 当业务函数fn发生panic或者goexit时,可能**影响框架对chan传值,
从而导致有其他协程阻塞等待chan,进而死锁** > 以上2个维度是并发框架需要额外关注的地方。
sf还有一个亮点就是对panic和Goexit的区分,巧妙的使用了双defer的方式区分2种调用函数异常终止的情况。
func example(fn func()) {
normalReturn := false
recovered := false
defer func() {
if !normalReturn && !recovered {
log.Info("get go exit")
}
}()
func() {
defer func() {
if !normalReturn { // 减少recover调用次数
if r := recover(); r != nil {
recovered = true
log.Info("get panic")
}
}
}()
fn()
normalReturn = true
}()
}此处也给我们提示,并发场景经常涉及到全局资源管理,在go语言下场景的有锁和chan,对资源的释放优先放在defer里,防止panic或Goexit导致的资源没有释放的问题。
使用chan时,需要留意,数据能否被即时的写入,会不会因为什么原因(主要是panic或Goexit)导致无法被写入,从而监听chan时被一直阻塞导致死锁。
Goexit无法被恢复,而panic有可能被恢复,被恢复后,chan可能不会再被写入,从而导致死锁,所以需要go panic保证无法被恢复,或者做额外一些逻辑。
