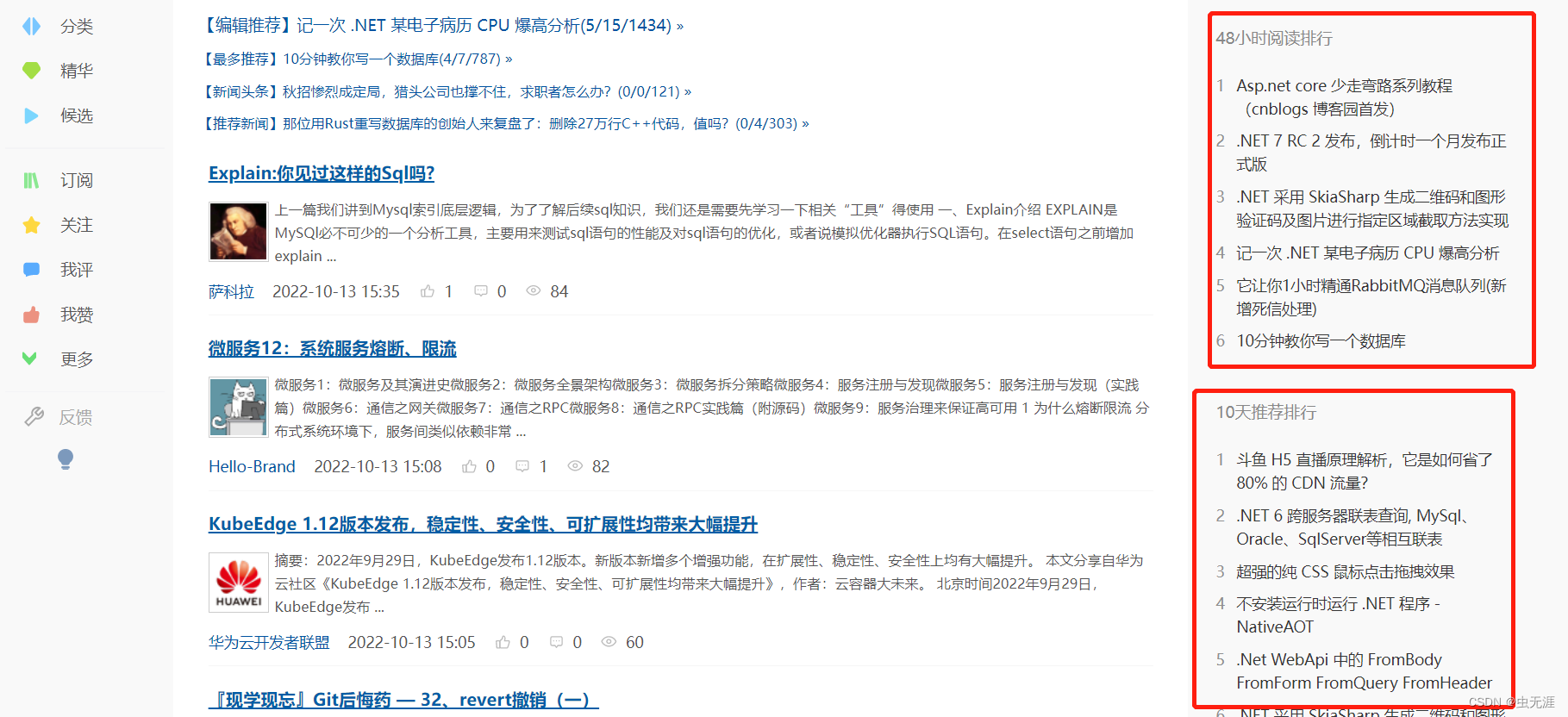
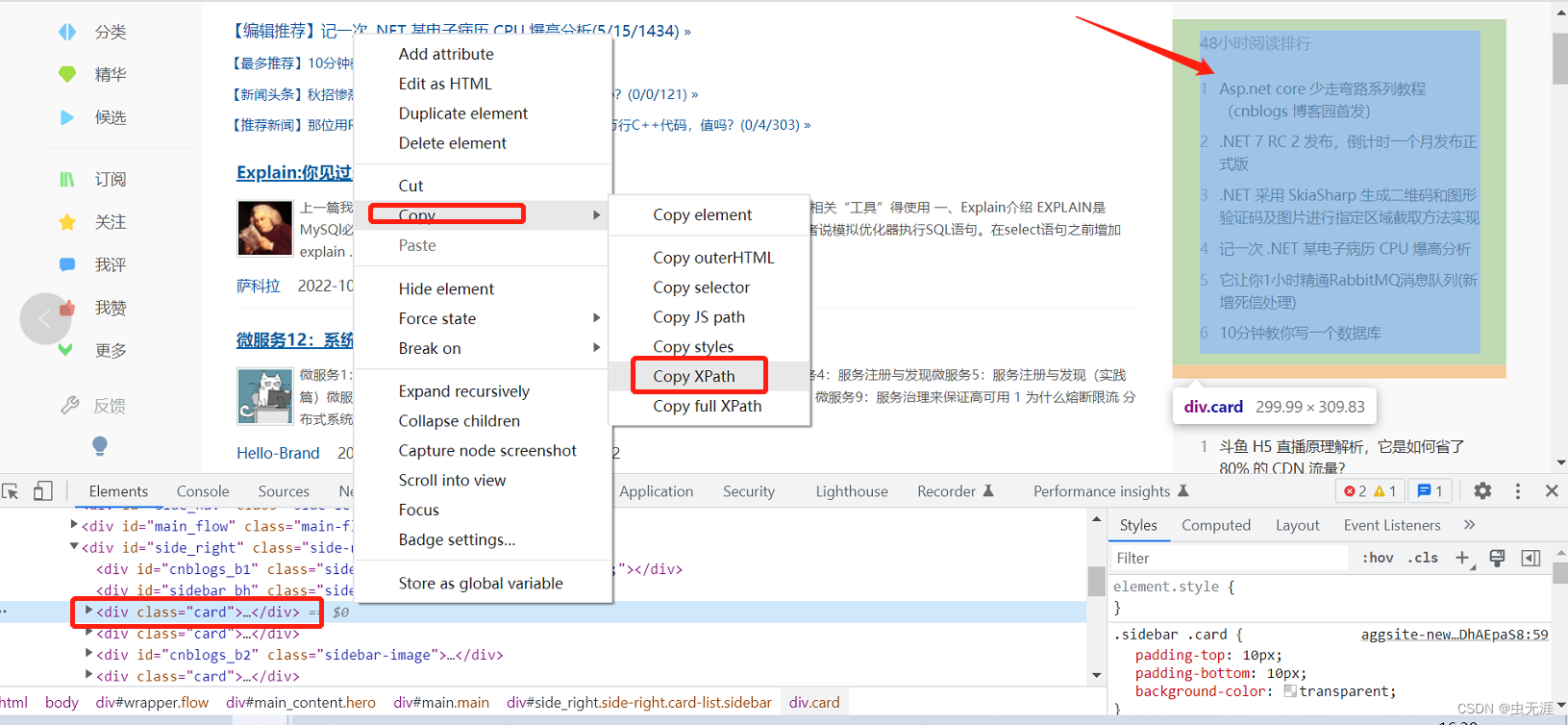
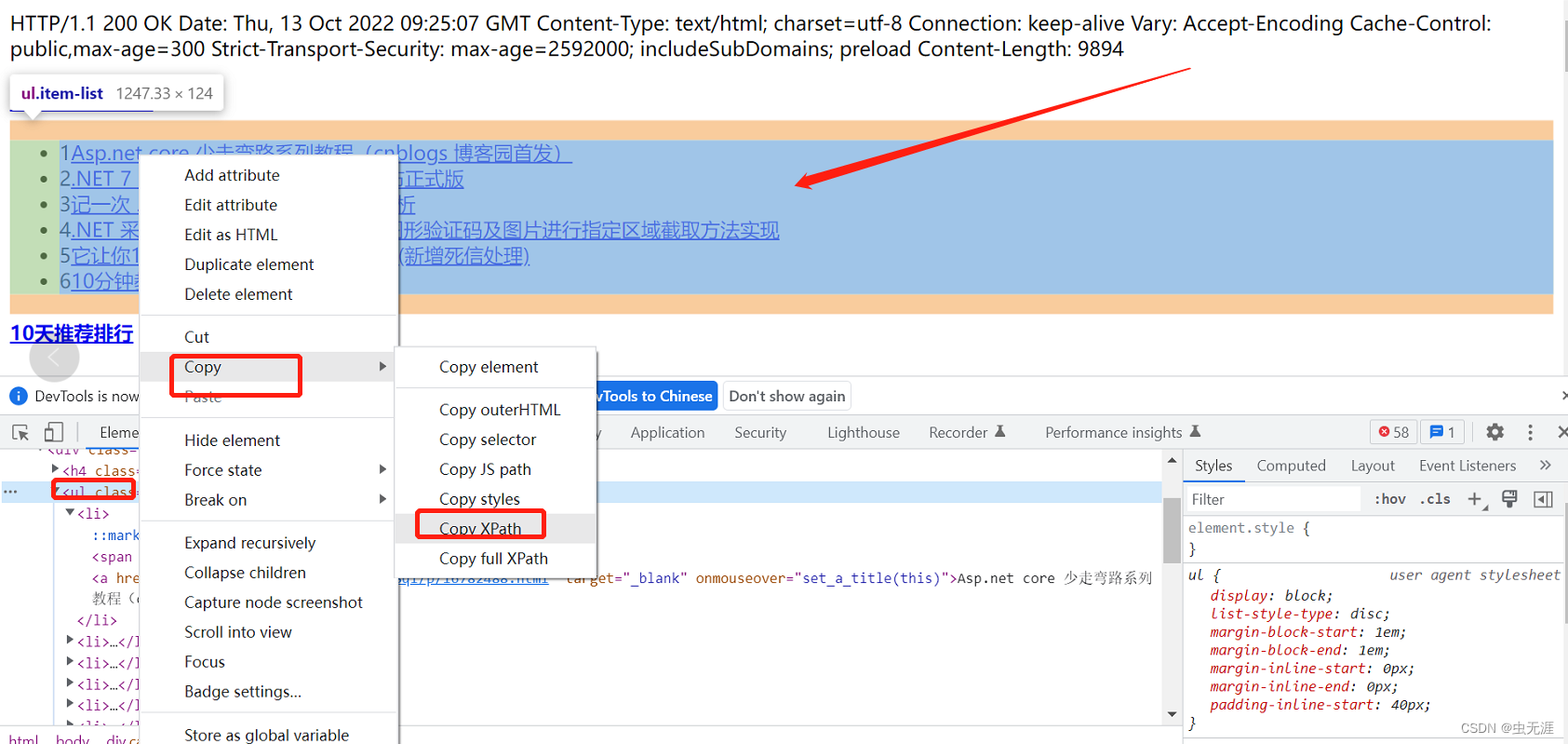
1 需求来源 自动化测试中,有时候需要获取某个元素所在区域的页面源码,用于后续的对比分析或者他用; 另外在pa chong中可能需要获取某个元素所在区域的页面源码,然后原格式保存下来,比如保存为html或者excel格式数据等。 2 测试对象 获取博客园首页右侧的【48小时阅读排行】词条; 获取博客园首页右侧的【10天推荐排行】词条。 在这里插入图片描述 3 需求实现 3.1 使用selenium实现 3.1.1 实现过程 查看博客园首页右侧的【48小时阅读排行】元素xpath属性; 在这里插入图片描述 复制其xpath:'//*[@id="side_right"]/div[3]'; 查看博客园首页右侧的【10天推荐排行】元素xpath属性:
在这里插入图片描述 复制其xpath:'//*[@id="side_right"]/div[4]'; 使用selenium的get_attribute('outerHTML')方法进行这两个元素的outerHTML获取: 3.1.2 源码 # -*- coding:utf-8 -*-
# 作者:NoamaNelson
# 日期:2022/10/13
# 文件名称:test_selenium_otherHTML.py
# 作用:xxx
# 联系:VX(NoamaNelson)
# 博客:https://blog.csdn.net/NoamaNelson
from selenium import webdriver
import time
content_list = ["content_48_h", "content_10_d"]
el_xpath = ['//*[@id="side_right"]/div[3]',
'//*[@id="side_right"]/div[4]']
content = []
driver = webdriver.Chrome()
driver.get("https://www.cnblogs.com/")
time.sleep(2)
for i in range(0, 2):
content_list[i] = driver.find_element_by_xpath(el_xpath[i])
content.append(content_list[i].get_attribute('outerHTML'))
print(f"48小时阅读排行为:{content[0]}",
f"10天推荐排行为:{content[1]}")
time.sleep(2)
driver.quit()复制 3.2 使用requests + lxml.etree实现 3.2.1 实现过程 # 48小时阅读排行
'//*[@id="side_right"]/div[3]'
# 10天推荐排行
'//*[@id="side_right"]/div[4]'复制 res = requests.get('https://www.cnblogs.com/',
verify=False,
headers=headers)复制 tree = etree.HTML(res.content)复制 tree.xpath('//*[@id="side_right"]/div[3]')
tree.xpath('//*[@id="side_right"]/div[4]')复制 3.2.2 源码 from lxml import etree
import requests
content_list = ["content_48_h", "content_10_d"]
el_xpath = ['//*[@id="side_right"]/div[3]',
'//*[@id="side_right"]/div[4]']
content = []
headers = {'Connection': 'close'}
res = requests.get('https://www.cnblogs.com/', verify=False, headers=headers)
tree = etree.HTML(res.content)
for i in range(0, 2):
content_list[i] = tree.xpath(el_xpath[i])
print(content_list[i])
content.append(etree.tostring(content_list[i][0], encoding='utf-8'))
print(f"48小时阅读排行为:{content[0]},",
f"10天推荐排行为:{content[1]}")复制 File "F:\python_study\test_selenium_otherHTML.py", line 24, in <module>
content.append(etree.tostring(content_list[i][0], encoding='utf-8'))
IndexError: list index out of range
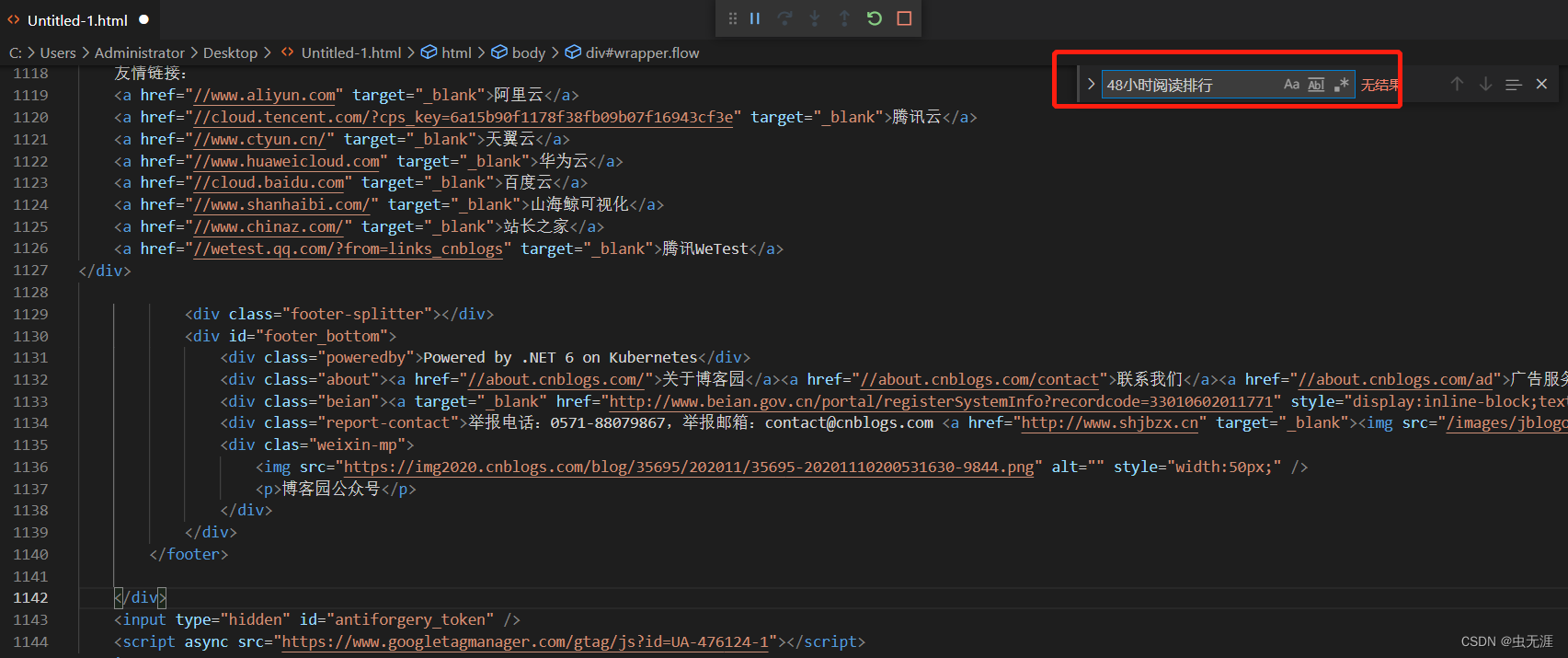
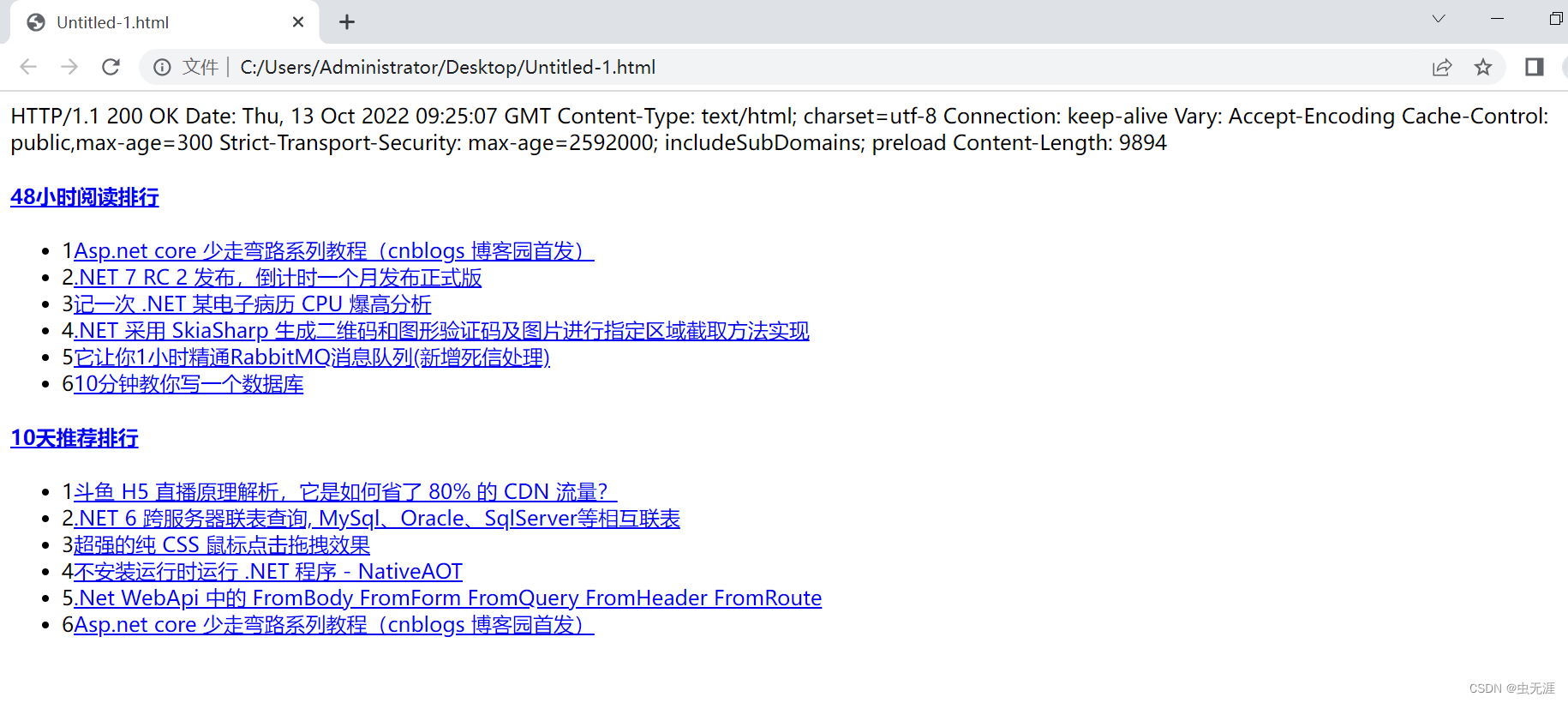
[]复制 从结果看,发现找到的对应xpath页面的内容为空,那么可以猜测是因为这个https://www.cnblogs.com/下没有对应的'//*[@id="side_right"]/div[3]'或'//*[@id="side_right"]/div[4]' 3.2.3 问题排查 3.2.3.1 获取该网址下的源码 使用fiddler抓包https://www.cnblogs.com/下的源码,进行查找我们的关键字【48小时阅读排行】和【10天推荐排行】: 在这里插入图片描述 复制返回的数据用vscode打开后查找以上关键字: 在这里插入图片描述 发现没有查找到结果,那么可以证实我们说的https://www.cnblogs.com/下没有对应的'//*[@id="side_right"]/div[3]'或'//*[@id="side_right"]/div[4]',换言之,我们需要的元素不在这个页面,虽然我们但从网页看是在同一页面,但可能是其他页面加载出来的。所以我们得找到这个原色所在的页面,重新进行定位。 3.2.3.2 使用fiddler找该元素所在网页和属性 打开fiddler后,我们继续访问https://www.cnblogs.com/; 往下看,找到接口https://www.cnblogs.com/aggsite/SideRight后,发现返回值里边有我们需要的关键字,那么这个接口地址才是我们需要的,而不是https://www.cnblogs.com/; 在这里插入图片描述 我们复制接口https://www.cnblogs.com/aggsite/SideRight的返回值到vscode中,并进行运行: 在这里插入图片描述 在这里插入图片描述 可以看到我们需要的关键字就在以上接口中,所以先确定好我们所需要的关键字的请求接口为:https://www.cnblogs.com/aggsite/SideRight; 然后我们从以上运行的页面中,获取真正的【48小时阅读排行】和【10天推荐排行】的元素的属性(xpath)。如下: 在这里插入图片描述 # 48小时阅读排行
'/html/body/div[1]/ul',
# 10天推荐排行
'/html/body/div[2]/ul'复制 3.2.4 修正后的源码 from lxml import etree
import requests
content_list = ["content_48_h", "content_10_d"]
el_xpath = ['/html/body/div[1]/ul',
'/html/body/div[2]/ul']
content = []
headers = {'Connection': 'close'}
res = requests.get('https://www.cnblogs.com/aggsite/SideRight', verify=False, headers=headers)
tree = etree.HTML(res.content)
for i in range(0, 2):
content_list[i] = tree.xpath(el_xpath[i])
print(content_list[i])
content.append(etree.tostring(content_list[i][0], encoding='utf-8'))
print(f"48小时阅读排行为:{content[0]},",
f"10天推荐排行为:{content[1]}")复制