

Metrics-server基于cAdvisor收集指标数据,获取、格式化后以metrics API的形式从apiserver对外暴露,核心作用是为kubectl top以及HPA等组件提供决策指标支持。
本文主要针对metrics-server展开指标收集链路的梳理,目的在于快速解决容器指标监控中的常见问题,比如:
为何kubectl top node 看到的资源使用率远高于top看到的?
为何kubectl top node看到资源百分比>100%?
为何HPA基于指标伸缩异常?
以下是metrics-server收集基础指标(CPU/Memory)的链路:从cgroup的数据源,到cadvisor负责数据收集,kubelet负责数据计算汇总,再到apiserver中以api方式暴露出去供客户端(HPA/kubectl top)访问。
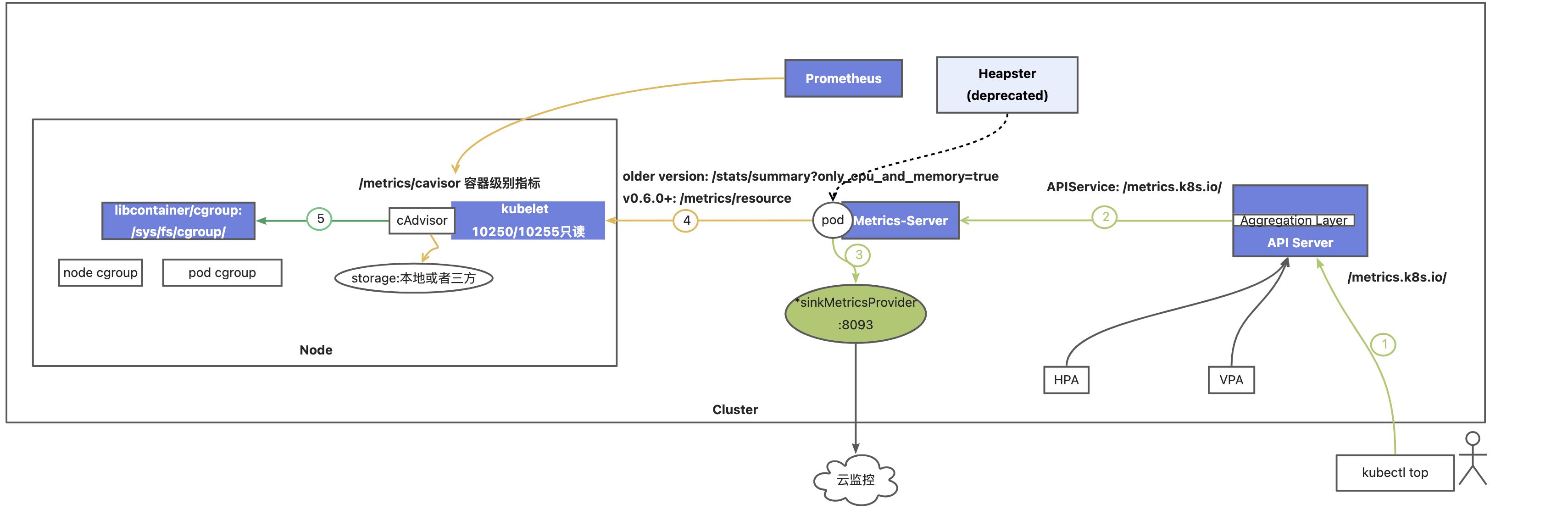
上图中数据请求流程(逆向路径):
Step1 . kubectl top向APIServer的Metrics API发起请求:
#kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes/xxxx
#kubectl get --raw /apis/metrics.k8s.io/v1beta1/namespaces/xxxx/pods/xxxx
Step2 . Aggregation 根据API service "metrics.k8s.io"的定义转发给后端svc:metrics-server
#kubectl get apiservices v1beta1.metrics.k8s.io
Step3 . Metrics-server pod获取最近一次的指标数据返回。
注:阿里云云监控容器监控控制台展示的指标基于metrics-server配置的sinkprovider 8093端口获取数据
# kubectl get svc -n kube-system heapster -oyaml 此处需要注意历史遗留的heapster svc是否也指向后端metrics-server pod
Step4. Metrics server定期向kubelet暴露的endpoint收集数据转换成k8s API格式,暴露给Metrics API.
Metrics-server本身不做数据采集,不做永久存储,相当于是将kubelet的数据做转换。
kubelet的在cadvisor采集数据的基础上做了计算汇总,提供container+pod+node级别的cgroup数据 older version:# curl 127.0.0.1:10255/stats/summary?only_cpu_and_memory=true v0.6.0+:#curl 127.0.0.1:10255/metrics/resource
Step5: cAdvisor定期向cgroup采集数据,container cgroup 级别。cadvisor的endpoint是 /metrics/cadvisor,仅提供contianer+machine数据,不做计算pod/node等指标。
#curl http://127.0.0.1:10255/metrics/cadvisor
Step6: 在Node/Pod对应的Cgroup目录查看指标文件中的数据。
#cd /sys/fs/cgroup/xxxx此处简单总结一下各种方式查看指标,后续会对每一步做详细分析
mount |grep cgroup
查看节点cgroup根目录:/sys/fs/cgroup
kubectl get pod -n xxxx xxxxx -oyaml |grep Uid -i -B10
获取containerid: kubectl describe pod -n xxxx xxxxx |grep id -i
比如可以根据以上得到的uid进入pod中container对应的cgroup目录:/sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod-<pod-uid>.slice/cri-containerd-<container-id>.scope
crictl pods |grep pod-name 可以拿到pod-id
crictl ps |grep container-name 或者crictl ps |grep pod-id 可以拿到 container-id
critl inspect <container-id> |grep -i pid
cat /proc/${CPID}/cgroup 或者 cat /proc/${CPID}/mountinfo |grep cgroup 比如cgroup文件可以看到具体的pod cgroup子目录:
"cpuacct": "/sys/fs/cgroup/cpu,cpuacct/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podxxxx.slice/cri-containerd-xxxx.scope",
"memory": "/sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podxxxx.slice/cri-containerd-xxxx.scope",# crictl pods |grep pod-name
可以获取<pod-id>, 注意pod-id不是pod uid
# cat /run/containerd/runc/k8s.io/<pod-id>/state.json |jq .
"cgroup_paths": {
"cpu": "/sys/fs/cgroup/cpu,cpuacct/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod4f8616f847da6685139113f6df14b010.slice/cri-containerd-c2eade28d94676563342077bab6c95bf48add7b872d66f246846b83d0eec5c78.scope",
"cpuacct": "/sys/fs/cgroup/cpu,cpuacct/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod4f8616f847da6685139113f6df14b010.slice/cri-containerd-c2eade28d94676563342077bab6c95bf48add7b872d66f246846b83d0eec5c78.scope",
"cpuset": "/sys/fs/cgroup/cpuset/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod4f8616f847da6685139113f6df14b010.slice/cri-containerd-c2eade28d94676563342077bab6c95bf48add7b872d66f246846b83d0eec5c78.scope",
...
"memory": "/sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod4f8616f847da6685139113f6df14b010.slice/cri-containerd-c2eade28d94676563342077bab6c95bf48add7b872d66f246846b83d0eec5c78.scope",
...
},
"namespace_paths": {
"NEWCGROUP": "/proc/8443/ns/cgroup",
"NEWNET": "/proc/8443/ns/net",
"NEWNS": "/proc/8443/ns/mnt",
"NEWPID": "/proc/8443/ns/pid",
"NEWUTS": "/proc/8443/ns/uts"
...
},进入到node/pod/container对应的cgroup目录中,查看指标对应的文件,此处不过多解读每个指标文件的含义。
//pod cgroup for cpu
# cd /sys/fs/cgroup/cpu,cpuacct/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod4f8616f847da6685139113f6df14b010.slice/cri-containerd-c2eade28d94676563342077bab6c95bf48add7b872d66f246846b83d0eec5c78.scope
# ls
...
cpuacct.block_latency cpuacct.stat cpuacct.usage_percpu_sys cpuacct.wait_latency cpu.cfs_period_us cpu.stat
cpuacct.cgroup_wait_latency cpuacct.usage cpuacct.usage_percpu_user cpu.bvt_warp_ns cpu.cfs_quota_us notify_on_release
//注意: CPU的cgroup目录 其实都是指向了cpu,cpuacct
lrwxrwxrwx 1 root root 11 3月 5 05:10 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 3月 5 05:10 cpuacct -> cpu,cpuacct
dr-xr-xr-x 7 root root 0 4月 28 15:41 cpu,cpuacct
dr-xr-xr-x 3 root root 0 4月 3 17:33 cpuset
//pod cgroup for memory
# cd /sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod4f8616f847da6685139113f6df14b010.slice/cri-containerd-c2eade28d94676563342077bab6c95bf48add7b872d66f246846b83d0eec5c78.scope
# ls
memory.direct_swapout_global_latency memory.kmem.tcp.failcnt memory.min memory.thp_reclaim tasks
memory.direct_swapout_memcg_latency memory.kmem.tcp.limit_in_bytes memory.move_charge_at_immigrate memory.thp_reclaim_ctrl
memory.events memory.kmem.tcp.max_usage_in_bytes memory.numa_stat memory.thp_reclaim_stat
memory.events.local memory.kmem.tcp.usage_in_bytes memory.oom_control memory.usage_in_bytes
...container_memory_working_set_bytes = container_memory_usage_bytes - total_inactive_file比如:
cat memory.usage_in_bytes
cat memory.stat |grep total_inactive_file
workingset=expr $[$usage_in_bytes-$total_inactive_file]
转换为兆为单位: echo [workingset/1024/1024]公式:
cpuUsage := float64(last.CumulativeCpuUsed-prev.CumulativeCpuUsed) / window.Seconds()
//其中,cgroup文件 cpuacct.usage 显示的为cpu累计值usagenamocoreseconds,需要按照以上公式做计算方可得到cpu使用量
//对一段时间 从 startTime ~ endTime间的瞬时的CPU Core的计算公式是:
(endTime的usagenamocoreseconds - startTime的usagenamocoreseconds) / (endTime - startTime)比如计算过去十秒的平均使用量(不是百分比,是cpu core的使用量):
tstart=$(date +%s%N);cstart=$(cat /sys/fs/cgroup/cpu/cpuacct.usage);sleep 10;tstop=$(date +%s%N);cstop=$(cat /sys/fs/cgroup/cpu/cpuacct.usage);result=`awk 'BEGIN{printf "%.2f\n",'$(($cstop - $cstart))'/'$(($tstop - $tstart))'}'`;echo $result;以上手动计算cpu的脚本引自: 《记一次pod oom的异常shmem输出》
kubectl get --raw=/api/v1/nodes/nodename/proxy/metrics/cadvisorcurl http://127.0.0.1:10255/metrics/cadvisor5. 如何通过kubelet接口获取指标
curl 127.0.0.1:10255/metrics/resource
curl 127.0.0.1:10255/stats/summary?only_cpu_and_memory=true |jq '.node’
6. 如何通过metrics-server API获取数据 (kubectl top或者HPA的调用方式)
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes/xxxx |jq .
kubectl get --raw /apis/metrics.k8s.io/v1beta1/namespaces/xxxx/pods/xxxx |jq .
如果客户端获取指标数据失败,可以在指标获取流程中(cgoup- > cadvisor-> kubelet-> MetrcisServer Pod -> apiserver/Metrics Api)通过各自暴露的接口获取数据,定位问题发生点。
最外层是node cgoup =》 qos级别cgroup =》 pod级别cgroup -》container级别cgroup
其中 node cgoup包含 kubepods +user+system部分
下图可直观显示cgroup层级包含关系:
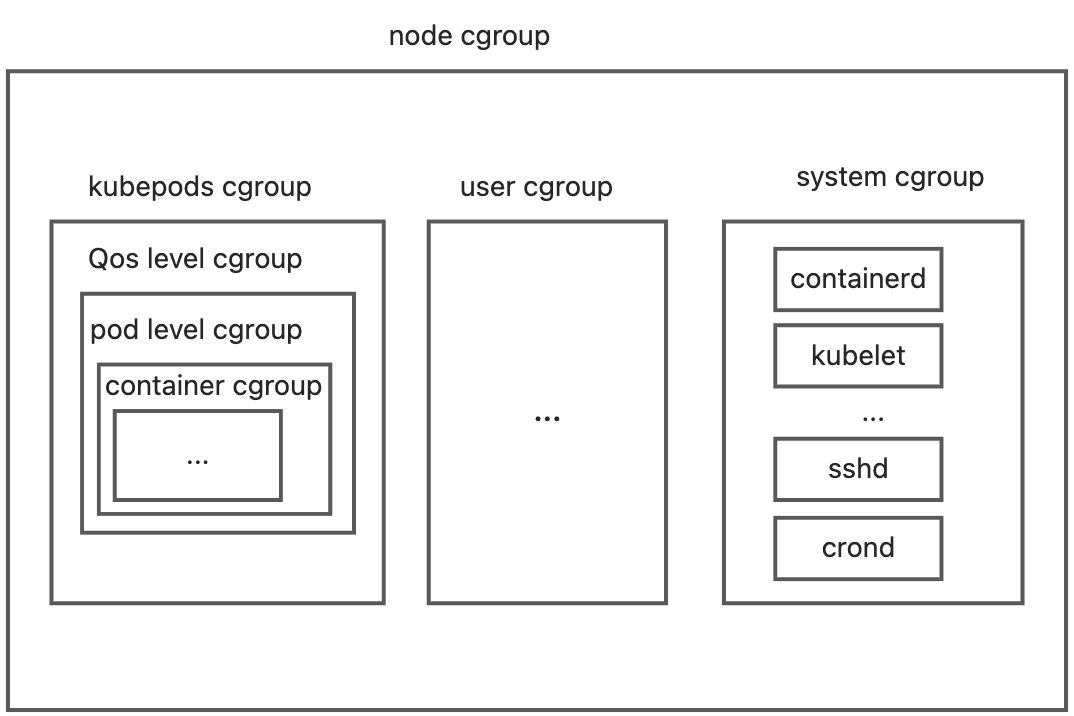
也可以使用systemd-cgls看层级结构,以下在node级别根目录 : /sys/fs/cgroup



注意:cadvsior 也只是个指标收集者,它的数据来自于cgroup 文件。
inactiveFileKeyName := "total_inactive_file"
if cgroups.IsCgroup2UnifiedMode() {
inactiveFileKeyName = "inactive_file"
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
ret.Memory.WorkingSet = workingSet
}kubectl get --raw=/api/v1/nodes/nodename/proxy/metrics/cadvisor
或者 curl http://127.0.0.1:10255/metrics/cadvisor
注意:/metrics/cadvisor 也是prometheus的其中一个数据源。
https://github.com/google/cadvisor/blob/master/info/v1/container.go#L320
该接口返回以下指标:
# curl http://127.0.0.1:10255/metrics/cadvisor |awk -F "\{" '{print $1}' |sort |uniq |grep "#" |grep -v TYPE
1 # HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.
1 # HELP container_blkio_device_usage_total Blkio Device bytes usage
1 # HELP container_cpu_cfs_periods_total Number of elapsed enforcement period intervals.
1 # HELP container_cpu_cfs_throttled_periods_total Number of throttled period intervals.
1 # HELP container_cpu_cfs_throttled_seconds_total Total time duration the container has been throttled.
1 # HELP container_cpu_load_average_10s Value of container cpu load average over the last 10 seconds.
1 # HELP container_cpu_system_seconds_total Cumulative system cpu time consumed in seconds.
1 # HELP container_cpu_usage_seconds_total Cumulative cpu time consumed in seconds.
1 # HELP container_cpu_user_seconds_total Cumulative user cpu time consumed in seconds.
1 # HELP container_file_descriptors Number of open file descriptors for the container.
1 # HELP container_fs_inodes_free Number of available Inodes
1 # HELP container_fs_inodes_total Number of Inodes
1 # HELP container_fs_io_current Number of I/Os currently in progress
1 # HELP container_fs_io_time_seconds_total Cumulative count of seconds spent doing I/Os
1 # HELP container_fs_io_time_weighted_seconds_total Cumulative weighted I/O time in seconds
1 # HELP container_fs_limit_bytes Number of bytes that can be consumed by the container on this filesystem.
1 # HELP container_fs_reads_bytes_total Cumulative count of bytes read
1 # HELP container_fs_read_seconds_total Cumulative count of seconds spent reading
1 # HELP container_fs_reads_merged_total Cumulative count of reads merged
1 # HELP container_fs_reads_total Cumulative count of reads completed
1 # HELP container_fs_sector_reads_total Cumulative count of sector reads completed
1 # HELP container_fs_sector_writes_total Cumulative count of sector writes completed
1 # HELP container_fs_usage_bytes Number of bytes that are consumed by the container on this filesystem.
1 # HELP container_fs_writes_bytes_total Cumulative count of bytes written
1 # HELP container_fs_write_seconds_total Cumulative count of seconds spent writing
1 # HELP container_fs_writes_merged_total Cumulative count of writes merged
1 # HELP container_fs_writes_total Cumulative count of writes completed
1 # HELP container_last_seen Last time a container was seen by the exporter
1 # HELP container_memory_cache Number of bytes of page cache memory.
1 # HELP container_memory_failcnt Number of memory usage hits limits
1 # HELP container_memory_failures_total Cumulative count of memory allocation failures.
1 # HELP container_memory_mapped_file Size of memory mapped files in bytes.
1 # HELP container_memory_max_usage_bytes Maximum memory usage recorded in bytes
1 # HELP container_memory_rss Size of RSS in bytes.
1 # HELP container_memory_swap Container swap usage in bytes.
1 # HELP container_memory_usage_bytes Current memory usage in bytes, including all memory regardless of when it was accessed
1 # HELP container_memory_working_set_bytes Current working set in bytes.
1 # HELP container_network_receive_bytes_total Cumulative count of bytes received
1 # HELP container_network_receive_errors_total Cumulative count of errors encountered while receiving
1 # HELP container_network_receive_packets_dropped_total Cumulative count of packets dropped while receiving
1 # HELP container_network_receive_packets_total Cumulative count of packets received
1 # HELP container_network_transmit_bytes_total Cumulative count of bytes transmitted
1 # HELP container_network_transmit_errors_total Cumulative count of errors encountered while transmitting
1 # HELP container_network_transmit_packets_dropped_total Cumulative count of packets dropped while transmitting
1 # HELP container_network_transmit_packets_total Cumulative count of packets transmitted
1 # HELP container_processes Number of processes running inside the container.
1 # HELP container_scrape_error 1 if there was an error while getting container metrics, 0 otherwise
1 # HELP container_sockets Number of open sockets for the container.
1 # HELP container_spec_cpu_period CPU period of the container.
1 # HELP container_spec_cpu_quota CPU quota of the container.
1 # HELP container_spec_cpu_shares CPU share of the container.
1 # HELP container_spec_memory_limit_bytes Memory limit for the container.
1 # HELP container_spec_memory_reservation_limit_bytes Memory reservation limit for the container.
1 # HELP container_spec_memory_swap_limit_bytes Memory swap limit for the container.
1 # HELP container_start_time_seconds Start time of the container since unix epoch in seconds.
1 # HELP container_tasks_state Number of tasks in given state
1 # HELP container_threads_max Maximum number of threads allowed inside the container, infinity if value is zero
1 # HELP container_threads Number of threads running inside the container
1 # HELP container_ulimits_soft Soft ulimit values for the container root process. Unlimited if -1, except priority and nice
1 # HELP machine_cpu_cores Number of logical CPU cores.
1 # HELP machine_cpu_physical_cores Number of physical CPU cores.
1 # HELP machine_cpu_sockets Number of CPU sockets.
1 # HELP machine_memory_bytes Amount of memory installed on the machine.
1 # HELP machine_nvm_avg_power_budget_watts NVM power budget.
1 # HELP machine_nvm_capacity NVM capacity value labeled by NVM mode (memory mode or app direct mod实验发现cadvisor接口返回了pause container的数据,跟网络上很多帖子的结论不同,这里待确认。
# curl http://127.0.0.1:10255/metrics/cadvisor |grep csi-plugin |grep container_cpu_usage_seconds_total
container_cpu_usage_seconds_total{container="",cpu="total",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod9bfea2a2_75a9_4c41_8225_77f9053ee153.slice",image="",name="",namespace="kube-system",pod="csi-plugin-tfrc6"} 675.44788393 1665548285204
container_cpu_usage_seconds_total{container="",cpu="total",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod9bfea2a2_75a9_4c41_8225_77f9053ee153.slice/cri-containerd-9f878a414fa02a1009e84dc7cea417084e9f856e8ae811112d841b9b1b86713f.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/pause:3.5",name="9f878a414fa02a1009e84dc7cea417084e9f856e8ae811112d841b9b1b86713f",namespace="kube-system",pod="csi-plugin-tfrc6"} 0.019981257 1665548276989
container_cpu_usage_seconds_total{container="csi-plugin",cpu="total",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod9bfea2a2_75a9_4c41_8225_77f9053ee153.slice/cri-containerd-eab2bc5aba47420c5dcfee0cdc63e9327f6154e95a64da2a10eb5c4b9bc9b8d0.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/csi-plugin:v1.22.11-abbb810e-aliyun",name="eab2bc5aba47420c5dcfee0cdc63e9327f6154e95a64da2a10eb5c4b9bc9b8d0",namespace="kube-system",pod="csi-plugin-tfrc6"} 452.018439495 1665548286584
container_cpu_usage_seconds_total{container="csi-provisioner",cpu="total",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod3ef3dfea_a052_4ed5_8b21_647e0ac42817.slice/cri-containerd-9b2a563af4409e0f19260af23f46c3f10102f5089ad97c696dbb77be20d95a82.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/csi-plugin:v1.20.7-aafce42-aliyun",name="9b2a563af4409e0f19260af23f46c3f10102f5089ad97c696dbb77be20d95a82",namespace="kube-system",pod="csi-provisioner-66d47b7f64-88lzs"} 533.027518847 1665548276678
container_cpu_usage_seconds_total{container="disk-driver-registrar",cpu="total",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod9bfea2a2_75a9_4c41_8225_77f9053ee153.slice/cri-containerd-b565d92528539b319d929935e20316c3cd121ab816f00ec5e09f2b1d7ec57eec.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/csi-node-driver-registrar:v2.3.0-038aeb6-aliyun",name="b565d92528539b319d929935e20316c3cd121ab816f00ec5e09f2b1d7ec57eec",namespace="kube-system",pod="csi-plugin-tfrc6"} 79.695711837 1665548287771
container_cpu_usage_seconds_total{container="nas-driver-registrar",cpu="total",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod9bfea2a2_75a9_4c41_8225_77f9053ee153.slice/cri-containerd-addd318c7faf17a566d11b9916452df298eb1c4f96214d8ca572920d53a05e06.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/csi-node-driver-registrar:v2.3.0-038aeb6-aliyun",name="addd318c7faf17a566d11b9916452df298eb1c4f96214d8ca572920d53a05e06",namespace="kube-system",pod="csi-plugin-tfrc6"} 71.727112206 1665548288055
container_cpu_usage_seconds_total{container="oss-driver-registrar",cpu="total",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod9bfea2a2_75a9_4c41_8225_77f9053ee153.slice/cri-containerd-7742122f2aca67336939e9c4f24696df5dc2d400e3674c4008c5e8202bf5ed7a.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/csi-node-driver-registrar:v2.3.0-038aeb6-aliyun",name="7742122f2aca67336939e9c4f24696df5dc2d400e3674c4008c5e8202bf5ed7a",namespace="kube-system",pod="csi-plugin-tfrc6"} 71.986891847 1665548274774
# curl http://127.0.0.1:10255/metrics/cadvisor |grep csi-plugin-cvjwm |grep container_memory_working_set_bytes
container_memory_working_set_bytes{container="",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podefa8311a_ec9b_4a18_a3ce_4bf39149a314.slice",image="",name="",namespace="kube-system",pod="csi-plugin-cvjwm"} 5.6066048e+07 1651810984383
container_memory_working_set_bytes{container="",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podefa8311a_ec9b_4a18_a3ce_4bf39149a314.slice/cri-containerd-2b08fab496e500709102969ed459f5150e7db008194fb3e71f1f7b0ad48f7e8e.scope",image="sha256:ed210e3e4a5bae1237f1bb44d72a05a2f1e5c6bfe7a7e73da179e2534269c459",name="2b08fab496e500709102969ed459f5150e7db008194fb3e71f1f7b0ad48f7e8e",namespace="kube-system",pod="csi-plugin-cvjwm"} 40960 1651810984964
container_memory_working_set_bytes{container="csi-plugin",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podefa8311a_ec9b_4a18_a3ce_4bf39149a314.slice/cri-containerd-5c79494498d7905db8ffda91f0037dc7208fcf75b67a2c85932065e95640bd77.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/csi-plugin:v1.20.7-aafce42-aliyun",name="5c79494498d7905db8ffda91f0037dc7208fcf75b67a2c85932065e95640bd77",namespace="kube-system",pod="csi-plugin-cvjwm"} 2.316288e+07 1651810988657
container_memory_working_set_bytes{container="disk-driver-registrar",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podefa8311a_ec9b_4a18_a3ce_4bf39149a314.slice/cri-containerd-c9b1bac3ca7539b317047188f233c3396be3df0796bc90b408caf98a4f51a70b.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/csi-node-driver-registrar:v1.3.0-6e9fff3-aliyun",name="c9b1bac3ca7539b317047188f233c3396be3df0796bc90b408caf98a4f51a70b",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.1063296e+07 1651810991117
container_memory_working_set_bytes{container="nas-driver-registrar",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podefa8311a_ec9b_4a18_a3ce_4bf39149a314.slice/cri-containerd-6e4c525abb2337ae7eb6f884dc9fc7a2605699581e450d4586173f8b7a4187cd.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/csi-node-driver-registrar:v1.3.0-6e9fff3-aliyun",name="6e4c525abb2337ae7eb6f884dc9fc7a2605699581e450d4586173f8b7a4187cd",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.0940416e+07 1651810981728
container_memory_working_set_bytes{container="oss-driver-registrar",id="/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podefa8311a_ec9b_4a18_a3ce_4bf39149a314.slice/cri-containerd-34f5248e3a3f812480a42b16e3c8514b41f8da8e5ae1c84684dd2525f583da79.scope",image="registry-vpc.cn-beijing.aliyuncs.com/acs/csi-node-driver-registrar:v1.3.0-6e9fff3-aliyun",name="34f5248e3a3f812480a42b16e3c8514b41f8da8e5ae1c84684dd2525f583da79",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.0846208e+07 1651810991024kubelet提供两个endpoint,是kubelet计算后的数据值。因为cAdvisor采集的是container级别的原始数据,不包含pod以及node的计算加和值。
不同版本的metrics-server请求的endpoint如下:
older version: /stats/summary?only_cpu_and_memory=true
v0.6.0+: /metrics/resource
Metrics-server v0.6.0跟kubelet的/metrics/resource获取数据:
// GetMetrics implements client.KubeletMetricsGetter
func (kc *kubeletClient) GetMetrics(ctx context.Context, node *corev1.Node) (*storage.MetricsBatch, error) {
port := kc.defaultPort
nodeStatusPort := int(node.Status.DaemonEndpoints.KubeletEndpoint.Port)
if kc.useNodeStatusPort && nodeStatusPort != 0 {
port = nodeStatusPort
}
addr, err := kc.addrResolver.NodeAddress(node)
if err != nil {
return nil, err
}
url := url.URL{
Scheme: kc.scheme,
Host: net.JoinHostPort(addr, strconv.Itoa(port)),
Path: "/metrics/resource",
}
return kc.getMetrics(ctx, url.String(), node.Name)
}该接口可以提供以下指标返回:
$ curl 127.0.0.1:10255/metrics/resource |awk -F "{" '{print $1}' | grep "#" |grep HELP
# HELP container_cpu_usage_seconds_total [ALPHA] Cumulative cpu time consumed by the container in core-seconds
# HELP container_memory_working_set_bytes [ALPHA] Current working set of the container in bytes
# HELP container_start_time_seconds [ALPHA] Start time of the container since unix epoch in seconds
# HELP node_cpu_usage_seconds_total [ALPHA] Cumulative cpu time consumed by the node in core-seconds
# HELP node_memory_working_set_bytes [ALPHA] Current working set of the node in bytes
# HELP pod_cpu_usage_seconds_total [ALPHA] Cumulative cpu time consumed by the pod in core-seconds
# HELP pod_memory_working_set_bytes [ALPHA] Current working set of the pod in bytes
# HELP scrape_error [ALPHA] 1 if there was an error while getting container metrics, 0 otherwise比如,查询特定pod的metrics,也会包含container metrcis :
#curl 127.0.0.1:10255/metrics/resource |grep csi-plugin-cvjwm
container_cpu_usage_seconds_total{container="csi-plugin",namespace="kube-system",pod="csi-plugin-cvjwm"} 787.211455926 1651651825597
container_cpu_usage_seconds_total{container="disk-driver-registrar",namespace="kube-system",pod="csi-plugin-cvjwm"} 16.58508124 1651651825600
container_cpu_usage_seconds_total{container="nas-driver-registrar",namespace="kube-system",pod="csi-plugin-cvjwm"} 16.820329754 1651651825602
container_cpu_usage_seconds_total{container="oss-driver-registrar",namespace="kube-system",pod="csi-plugin-cvjwm"} 16.016630434 1651651825605
container_memory_working_set_bytes{container="csi-plugin",namespace="kube-system",pod="csi-plugin-cvjwm"} 2.312192e+07 1651651825597
container_memory_working_set_bytes{container="disk-driver-registrar",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.1071488e+07 1651651825600
container_memory_working_set_bytes{container="nas-driver-registrar",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.0940416e+07 1651651825602
container_memory_working_set_bytes{container="oss-driver-registrar",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.0846208e+07 1651651825605
container_start_time_seconds{container="csi-plugin",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.64639996363012e+09 1646399963630
container_start_time_seconds{container="disk-driver-registrar",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.646399924462264e+09 1646399924462
container_start_time_seconds{container="nas-driver-registrar",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.646399937591126e+09 1646399937591
container_start_time_seconds{container="oss-driver-registrar",namespace="kube-system",pod="csi-plugin-cvjwm"} 1.6463999541537158e+09 1646399954153
pod_cpu_usage_seconds_total{namespace="kube-system",pod="csi-plugin-cvjwm"} 836.633497354 1651651825616
pod_memory_working_set_bytes{namespace="kube-system",pod="csi-plugin-cvjwm"} 5.5980032e+07 1651651825643接口返回指标如下,包含node/pod/container:
# curl 127.0.0.1:10255/stats/summary?only_cpu_and_memory=true |jq '.node'
{
"nodeName": "ack.dedicated00009yibei",
"systemContainers": [
{
"name": "pods",
"startTime": "2022-03-04T13:17:01Z",
"cpu": {
...
},
"memory": {
...
}
},
{
"name": "kubelet",
"startTime": "2022-03-04T13:17:22Z",
"cpu": {
...
},
"memory": {
...
}
}
],
"startTime": "2022-03-04T13:11:06Z",
"cpu": {
"time": "2022-05-05T13:54:02Z",
"usageNanoCores": 182358783, =======> HPA/kubectl top的取值来源,也是也是基于下面的累计值的计算值。
"usageCoreNanoSeconds": 979924257151862====>累计值,使用时间窗口window做后续计算。
},
"memory": {
"time": "2022-05-05T13:54:02Z",
"availableBytes": 1296015360,
"usageBytes": 3079581696,
"workingSetBytes": 2592722944, =======>kubectl top node 大体一致
"rssBytes": 1459187712,
"pageFaults": 9776943,
"majorPageFaults": 1782
}
}
###########################
#curl 127.0.0.1:10255/stats/summary?only_cpu_and_memory=true |jq '.pods[1]'
{
"podRef": {
"name": "kube-flannel-ds-s6mrk",
"namespace": "kube-system",
"uid": "5b328994-c4a1-421d-9ab0-68992ca79807"
},
"startTime": "2022-03-04T13:18:41Z",
"containers": [
{
...
}
],
"cpu": {
"time": "2022-05-05T13:53:03Z",
"usageNanoCores": 2817176,
"usageCoreNanoSeconds": 11613876607138
},
"memory": {
"time": "2022-05-05T13:53:03Z",
"availableBytes": 237830144,
"usageBytes": 30605312,
"workingSetBytes": 29876224,
"rssBytes": 26116096,
"pageFaults": 501002073,
"majorPageFaults": 1716
}
}
###########################
# curl 127.0.0.1:10255/stats/summary?only_cpu_and_memory=true |jq '.pods[1].containers[0]'
{
"name": "kube-scheduler",
"startTime": "2022-05-05T08:27:55Z",
"cpu": {
"time": "2022-05-05T13:56:16Z",
"usageNanoCores": 1169892,
"usageCoreNanoSeconds": 29353035680
},
"memory": {
"time": "2022-05-05T13:56:16Z",
"availableBytes": 9223372036817981000,
"usageBytes": 36790272,
"workingSetBytes": 32735232,
"rssBytes": 24481792,
"pageFaults": 5511,
"majorPageFaults": 165
}
}CPU重点指标解析:
usageCoreNanoSeconds: //累计值,单位是nano core * seconds . 根据时间窗口window跟总核数计算出cpu usage.
usageNanoCores://计算值,利用某个默认时间段的两个累计值usageCoreNanoSeconds做计算的结果.
CPU使用量usageNanoCores= (endTime的usagenamocoreseconds - startTime的usagenamocoreseconds) / (endTime - startTime)计算方式:
Metrcis API返回的window是用来计算CPU使用率的时间窗口,关于此处cpu使用率的计算:
https://github.com/google/cadvisor/issues/2126
https://github.com/google/cadvisor/issues/2032
https://github.com/google/cadvisor/issues/2198#issuecomment-584230223
比如计算过去十秒的平均使用量(不是百分比,是cpu core的使用量):
tstart=$(date +%s%N);cstart=$(cat /sys/fs/cgroup/cpu/cpuacct.usage);sleep 10;tstop=$(date +%s%N);cstop=$(cat /sys/fs/cgroup/cpu/cpuacct.usage);result=`awk 'BEGIN{printf "%.2f\n",'$(($cstop - $cstart))'/'$(($tstop - $tstart))'}'`;echo $result;// MetricsPoint represents the a set of specific metrics at some point in time.
type MetricsPoint struct {
// StartTime is the start time of container/node. Cumulative CPU usage at that moment should be equal zero.
StartTime time.Time
// Timestamp is the time when metric point was measured. If CPU and Memory was measured at different time it should equal CPU time to allow accurate CPU calculation.
Timestamp time.Time
// CumulativeCpuUsed is the cumulative cpu used at Timestamp from the StartTime of container/node. Unit: nano core * seconds.
CumulativeCpuUsed uint64
// MemoryUsage is the working set size. Unit: bytes.
MemoryUsage uint64
}
func resourceUsage(last, prev MetricsPoint) (corev1.ResourceList, api.TimeInfo, error) {
if last.CumulativeCpuUsed < prev.CumulativeCpuUsed {
return corev1.ResourceList{}, api.TimeInfo{}, fmt.Errorf("unexpected decrease in cumulative CPU usage value")
}
window := last.Timestamp.Sub(prev.Timestamp)
cpuUsage := float64(last.CumulativeCpuUsed-prev.CumulativeCpuUsed) / window.Seconds()
return corev1.ResourceList{
corev1.ResourceCPU: uint64Quantity(uint64(cpuUsage), resource.DecimalSI, -9),
corev1.ResourceMemory: uint64Quantity(last.MemoryUsage, resource.BinarySI, 0),
}, api.TimeInfo{
Timestamp: last.Timestamp,
Window: window,
}, nil
}#!/bin/bash
#!/usr/bin/env bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to root cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes)
memory_total_inactive_file=$(cat /sys/fs/cgroup/memory/memory.stat | grep total_inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"部署apiservice的时候向apiserver的aggregation layer注册Metrcis API。这样apiserver收到特定metrics api (/metrics.k8s.io/)的请求后,会转发给后端定义的metrics-server做处理。

kubectl get apiservices v1beta1.metrics.k8s.io 后端指向的svc是metrics-service.
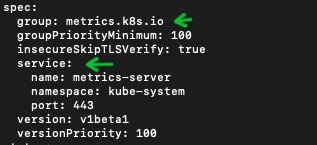
如果此处apiservice指向有问题导致指标获取异常,可清理资源重装metrics-server:
1,删除 v1beta1.metrics.k8s.io ApiServices
kubectl delete apiservice v1beta1.metrics.k8s.io
2,卸载metrics-server
kubectl delete deployment metrics-server -nkube-system
3,重新安装 metrics-server组件Heapster是老版本集群中用来收集指标的,后续基础CPU/Memory由metrics-server负责,自定义指标可以prometheus负责。ACK集群中Heapster跟metrics-server两个svc共同指向metrics-server pod。

阿里云ACK集群中官方metrics-server组件的启动参数如下:
containers:
command:
/metrics-server
--source=kubernetes.hybrid:''
--sink=socket:tcp://monitor.csk.cn-beijing.aliyuncs.com:8093?clusterId=xxx&public=true
image: registry-vpc.cn-beijing.aliyuncs.com/acs/metrics-server:v0.3.8.5-307cf45-aliyun
注意,sink中定义的8093端口,用于metrics-server pod向阿里云云监控提供指标数据。
另外,启动参数中没指定的,采用默认值,比如:
--metric-resolution duration
The resolution at which metrics-server will retain metrics. (default 30s)
指标缓存sink的定义:
https://github.com/kubernetes-sigs/metrics-server/blob/v0.3.5/pkg/provider/sink/sinkprov.go#L134
// sinkMetricsProvider is a provider.MetricsProvider that also acts as a sink.MetricSink
type sinkMetricsProvider struct {
mu sync.RWMutex
nodes map[string]sources.NodeMetricsPoint
pods map[apitypes.NamespacedName]sources.PodMetricsPoint
}Metrcis-server相当于对kubelet endpoint的数据做了一次转换:
# kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes/ack.dedicated00009yibei |jq .
{
"kind": "NodeMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "ack.dedicated00009yibei",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/ack.dedicated00009yibei",
"creationTimestamp": "2022-05-05T14:28:27Z"
},
"timestamp": "2022-05-05T14:27:32Z",
"window": "30s", ===》计算cpu累计值差值的时间窗口
"usage": {
"cpu": "157916713n", ====》 nanocore,基于CPU累计值的计算结果值
"memory": "2536012Ki" ====》cgroup.working_set
}
}
# kubectl get --raw /apis/metrics.k8s.io/v1beta1/namespaces/default/pods/centos7-74cd758d98-wcwnj |jq .
{
"kind": "PodMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "centos7-74cd758d98-wcwnj",
"namespace": "default",
"selfLink": "/apis/metrics.k8s.io/v1beta1/namespaces/default/pods/centos7-74cd758d98-wcwnj",
"creationTimestamp": "2022-05-05T14:32:39Z"
},
"timestamp": "2022-05-05T14:32:04Z",
"window": "30s",
"containers": [
{
"name": "centos7",
"usage": {
"cpu": "0",
"memory": "224Ki"
}
}
]
}// -v=6看API请求
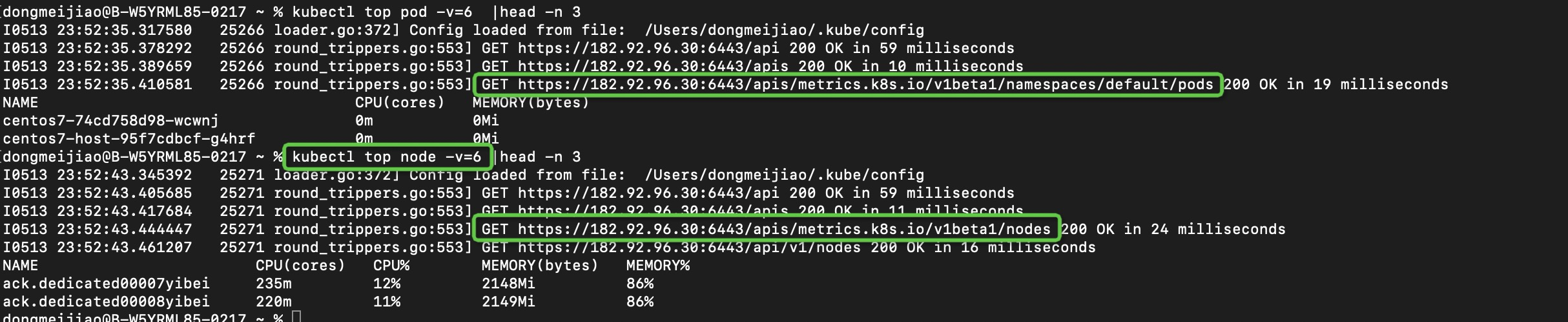
向metrics API请求数据拿到CPU/Memory值后做计算与展示:
https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale/#kubectl-%E5%AF%B9-horizontal-pod-autoscaler-%E7%9A%84%E6%94%AF%E6%8C%81
计算逻辑:
DesiredReplicas=ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
CurrentUtilization=int32((metricsTotal*100) /requestsTotal)
其中,计算requestsTotal时,是将pod.Spec.Containers loop相加,一旦某一个container没有request就return报错,不累计init container.***衍生出一个知识点***
开启HPA的deployment必须给每个container定义request值,不过initcontainer不做要求。
https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/podautoscaler/replica_calculator.go#L433
func calculatePodRequests(pods []*v1.Pod, container string, resource v1.ResourceName) (map[string]int64, error) {
requests := make(map[string]int64, len(pods))
for _, pod := range pods {
podSum := int64(0)
for _, c := range pod.Spec.Containers {
if container == "" || container == c.Name {
if containerRequest, ok := c.Resources.Requests[resource]; ok {
podSum += containerRequest.MilliValue()
} else {
return nil, fmt.Errorf("missing request for %s", resource)
}
}
}
requests[pod.Name] = podSum
}
return requests, nil
}// GetResourceUtilizationRatio takes in a set of metrics, a set of matching requests,
// and a target utilization percentage, and calculates the ratio of
// desired to actual utilization (returning that, the actual utilization, and the raw average value)
func GetResourceUtilizationRatio(metrics PodMetricsInfo, requests map[string]int64, targetUtilization int32) (utilizationRatio float64, currentUtilization int32, rawAverageValue int64, err error) {
metricsTotal := int64(0)
requestsTotal := int64(0)
numEntries := 0
for podName, metric := range metrics {
request, hasRequest := requests[podName]
if !hasRequest {
// we check for missing requests elsewhere, so assuming missing requests == extraneous metrics
continue
}
metricsTotal += metric.Value
requestsTotal += request
numEntries++
}
// if the set of requests is completely disjoint from the set of metrics,
// then we could have an issue where the requests total is zero
if requestsTotal == 0 {
return 0, 0, 0, fmt.Errorf("no metrics returned matched known pods")
}
额
currentUtilization = int32((metricsTotal * 100) / requestsTotal)
return float64(currentUtilization) / float64(targetUtilization), currentUtilization, metricsTotal / int64(numEntries), nil
}参考:
《记一次pod oom的异常shmem输出》 https://developer.aliyun.com/article/1040230?spm=a2c6h.13262185.profile.46.994e2382PrPuO5
https://kubernetes.io/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
https://github.com/kubernetes/community/blob/master/contributors/devel/sig-node/cri-container-stats.md
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
https://github.com/kubernetes/kubernetes/blob/65178fec72df6275ed0aa3ede12c785ac79ab97a/pkg/controller/podautoscaler/replica_calculator.go#L424
https://github.com/kubernetes-sigs/metrics-server
https://github.com/kubernetes-sigs/metrics-server/blob/master/FAQ.md#how-cpu-usage-is-calculated
cAdvisor源码分析 : https://cloud.tencent.com/developer/article/1096375
https://github.com/google/cadvisor/blob/d6b0ddb07477b17b2f3ef62b032d815b1cb6884e/machine/machine.go
https://github.com/google/cadvisor/tree/3beb265804ea4b00dc8ed9125f1f71d3328a7a94/container/libcontainer
https://www.jianshu.com/p/7c18075aa735
https://www.cnblogs.com/gaorong/p/11716907.html
https://www.cnblogs.com/vinsent/p/15830271.html