

MAC是Message Authentication Code的缩写。
简单来说,MAC就是随消息一起传输的标签或数据,可以通过MAC对消息进行验证,已确定消息是否被篡改过。
在上一篇文章《MD5哈希碰撞之哈希长度拓展攻击》中,我们曾经聊到过Hash算法本身也可以对数据的唯一性做标识。
但是,HASH与MAC还是有一点区别。
最根本的区别就是,HASH只能保证消息的完整性,MAC不仅能够保证完整性,还能够保证真实性。
比如A想给B发送一条消息,A需要把消息内容和对应的消息摘要都发给B;B通过同样的摘要算法计算摘要,就可以知道消息是否被篡改。
此时如果攻击者C将A发送的原始消息和摘要都篡改成新的消息和摘要,那么这个消息对B来说也是完整的,只不过不是A发的。
而MAC含有密钥这个种子(只有A和B知道),如果A将消息内容和MAC发给B,虽然C是仍然可以修改消息内容和MAC,但是由于C不知道密钥,所以无法生成与篡改后内容匹配的MAC。
HAMC的官方定义在RFC2104中可以查询到,感兴趣的同学可以自行查阅。
每种HASH算法都有两个基础特性,分别是,针对输入数据的分组长度,以及输出数据的长度。
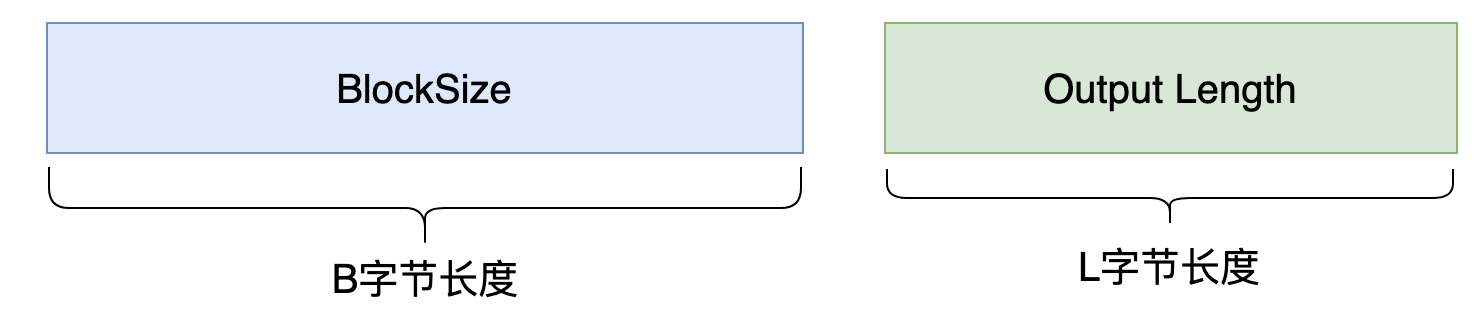
HMAC的输出与HASH算法本身的输出是等长的。
但是由于HMAC引入了密钥的概念,并且HAMC在计算时做了更复杂的比特扩散运算,因此同样的明文数据,HMAC与HASH输出肯定不一样。
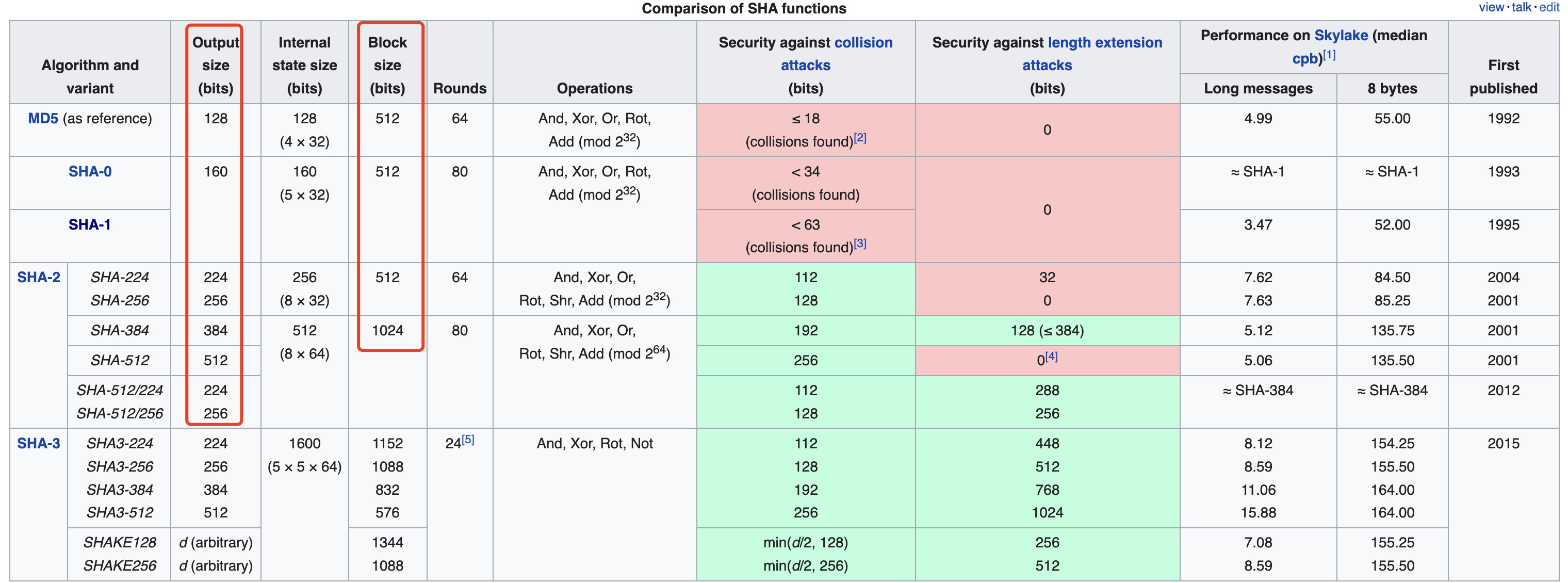
常见的HASH算法的分组长度与输出长度可以参考:
这里我们不讨论更底层的数学原理,仅仅根据RFC2104中的描述,讲解下其实现的流程。
总体来说,HMAC的计算流程可以概括为以下的步骤(箭头代表先后关系):
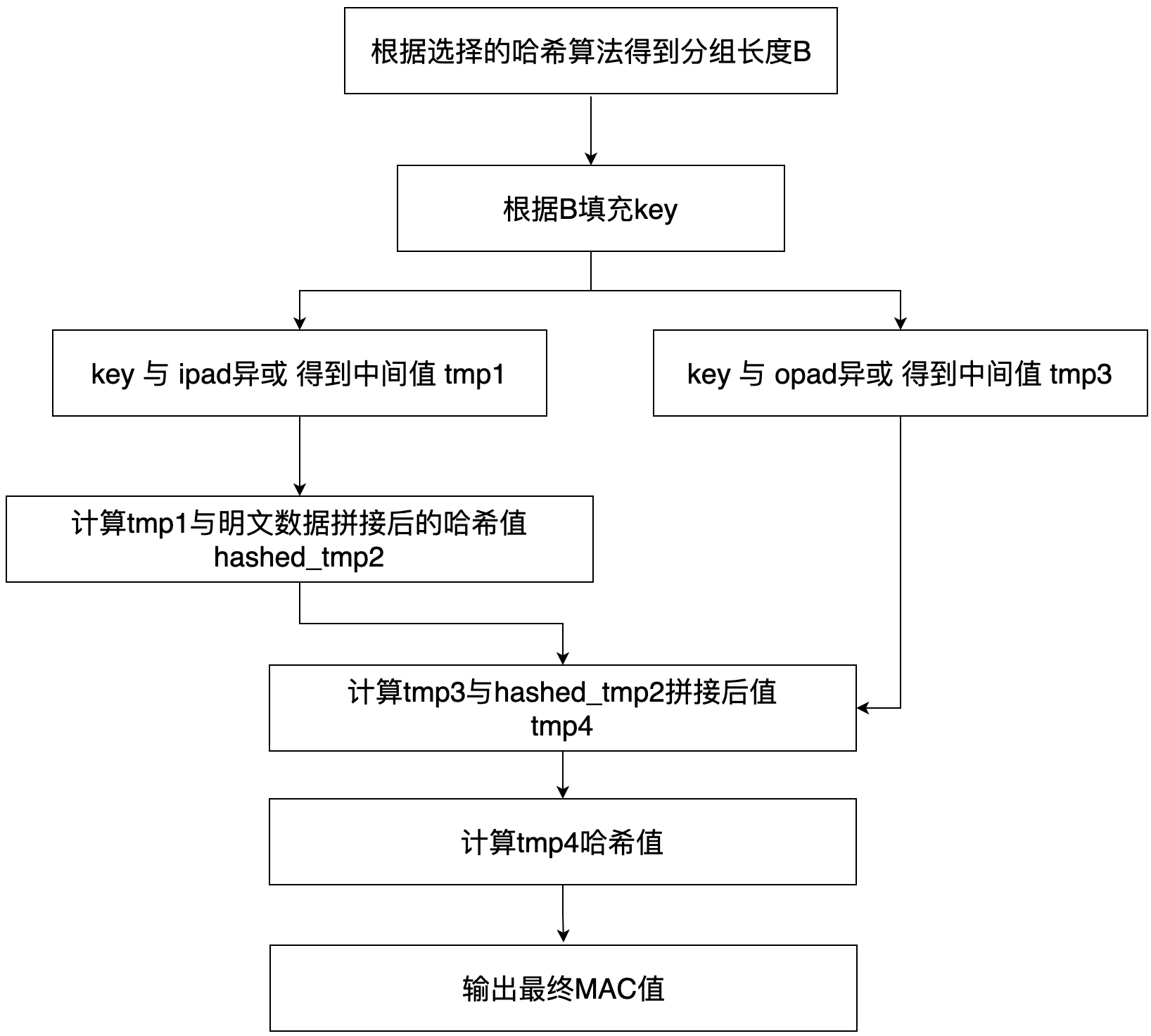
这个步骤对应的是RFC2104中的这段描述:

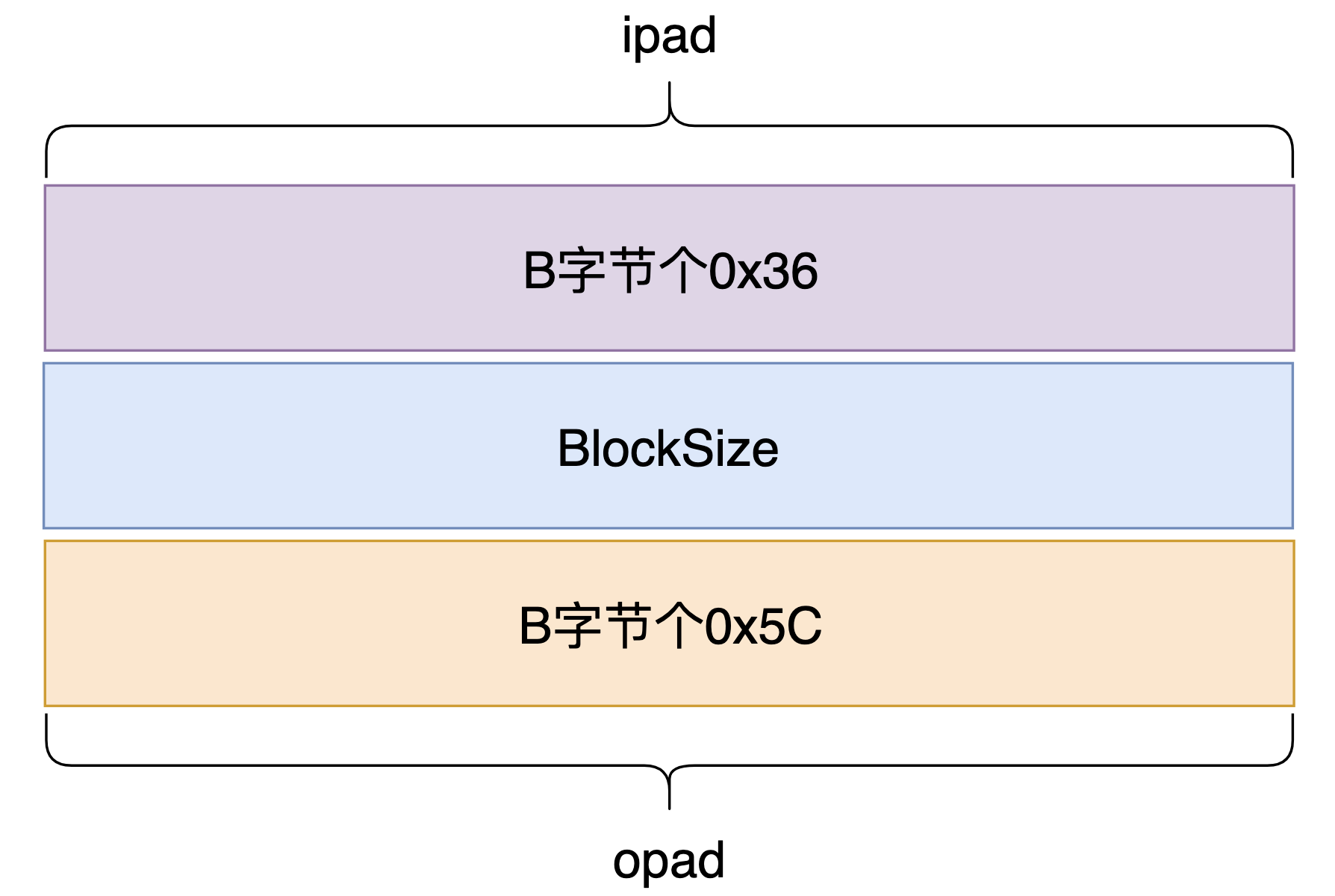
密钥填充分为两种情况:
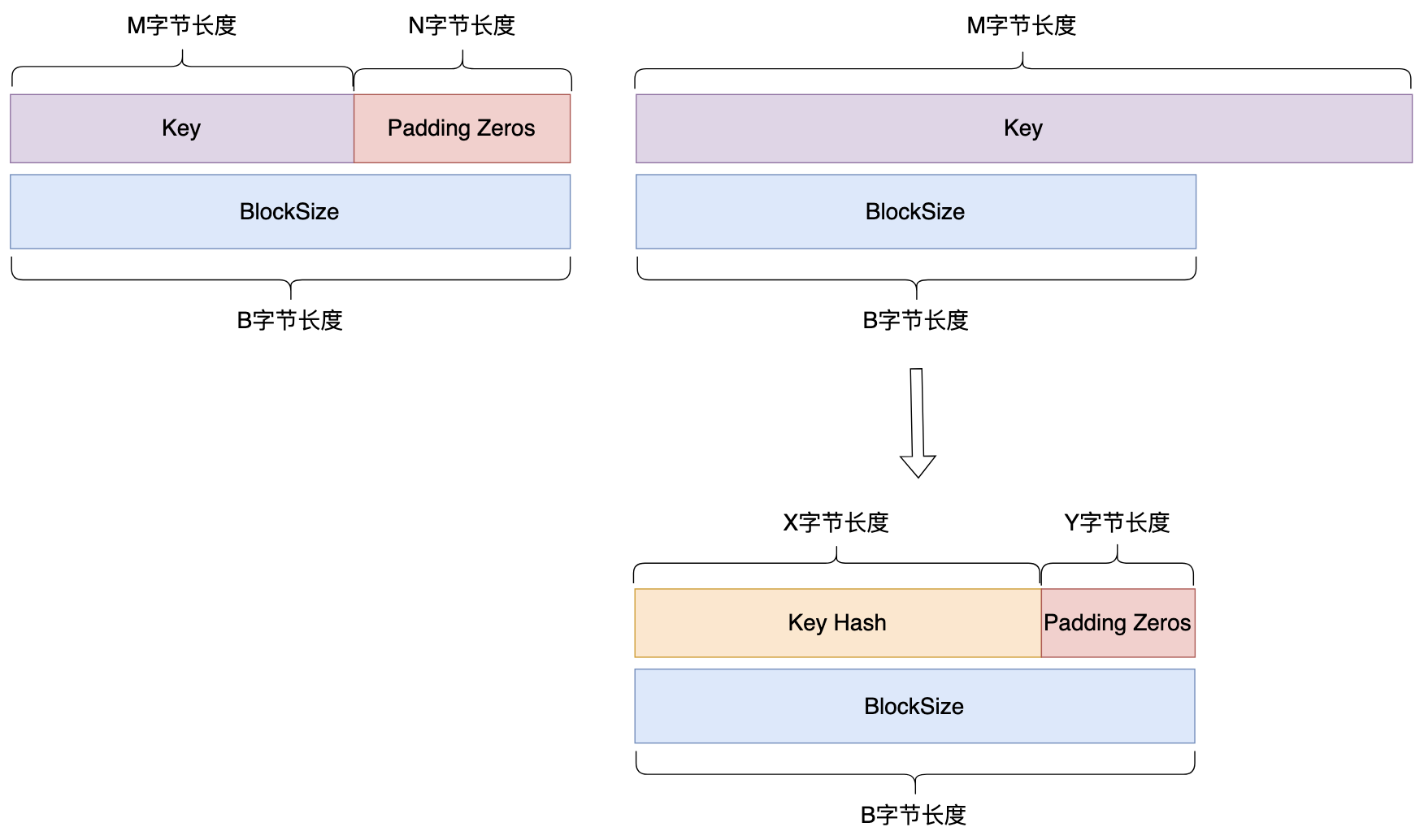
在选定了HAMC使用的HASH算法时,其实分组长度B就已经确定了,同时,HAMC运算时的两个常量ipad与opad也就确定了:
如果不使用标准的密码库,我们手动实现HMAC,其过程可以参考如下代码:
import hashlib
from typing import Dict, List
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives import hashes, hmac
def append_zero_to_key(key: bytes, zero_count: int) -> bytes:
if zero_count <= 0:
return key
return key + bytes([0x00 for _ in range(zero_count)])
class custom_hmac(object):
def __init__(self, alg: str):
"""
Args:
alg: 哈希算法,默认为sha256
"""
self.key_block_size: str = 'block_size'
self.key_output_len: str = 'output_length'
self.ipad_single_value: int = 0x36
self.opad_single_value: int = 0x5c
self.key_ipad: str = 'ipad'
self.key_opad: str = 'opad'
self.alg: str = 'sha256'
self.hash_list = [hashlib.md5(), hashlib.sha1(), hashlib.sha224(), hashlib.sha256(),
hashlib.sha384(), hashlib.sha512()]
"""
e.g :
{
'md5': {
'block_size': 64,
'output_length': 16
'ipad': 12345
'opad': 54321
}
}
"""
self.hash_attr: Dict[str, Dict[str, int]] = {}
for h in self.hash_list:
ipad_list = [self.ipad_single_value for _ in range(h.block_size)]
opad_list = [self.opad_single_value for _ in range(h.block_size)]
# print("{}, ipad:{}, len:{}\nopad:{}, len:{}".format(h.name, ipad_list, len(ipad_list),
# opad_list, len(opad_list)))
self.hash_attr[h.name] = {
self.key_block_size: h.block_size,
self.key_output_len: h.digest_size,
self.key_ipad: int.from_bytes(bytes(ipad_list),
byteorder = 'big'),
self.key_opad: int.from_bytes(bytes(opad_list),
byteorder = 'big')
}
# print(json.dumps(self.hash_attr, indent = ' ', ensure_ascii = True))
if alg not in self.hash_attr.keys():
raise ValueError("alg:{} not supported, valid alg:{}".format(alg, self.hash_attr.keys()))
else:
self.alg = alg
def get_short_data_hash(self, data: bytes) -> bytes:
hash_obj = hashlib.md5(data)
if self.alg == 'sha1':
hash_obj = hashlib.sha1(data)
elif self.alg == 'sha224':
hash_obj = hashlib.sha224(data)
elif self.alg == 'sha256':
hash_obj = hashlib.sha256(data)
elif self.alg == 'sha384':
hash_obj = hashlib.sha384(data)
elif self.alg == 'sha512':
hash_obj = hashlib.sha512(data)
return hash_obj.digest()
def calculate_key(self, key: bytes) -> bytes:
if len(key) < self.hash_attr[self.alg][self.key_block_size]:
return append_zero_to_key(key, self.hash_attr[self.alg][self.key_block_size] - len(key))
elif len(key) > self.hash_attr[self.alg][self.key_block_size]:
tmp: bytes = self.get_short_data_hash(key)
return append_zero_to_key(tmp, self.hash_attr[self.alg][self.key_block_size] - len(tmp))
return key
def key_xor_pad(self, key: bytes, xor_ipad: bool) -> bytes:
ret: List[int] = [0x00 for _ in range(self.hash_attr[self.alg][self.key_block_size])]
if xor_ipad:
ipad_bytes = self.hash_attr[self.alg][self.key_ipad].to_bytes(self.hash_attr[self.alg][self.key_block_size],
byteorder = 'big')
# print("key_xor_pad, alg:{}, ipad_list:{}, len:{}".format(self.alg, list(ipad_bytes), len(ipad_bytes)))
for k, v in enumerate(key):
ret[k] = v ^ ipad_bytes[k]
else:
opad_bytes = self.hash_attr[self.alg][self.key_opad].to_bytes(self.hash_attr[self.alg][self.key_block_size],
byteorder = 'big')
# print("key_xor_pad, alg:{}, opad_list:{}, len:{}".format(self.alg, list(opad_bytes), len(opad_bytes)))
for k, v in enumerate(key):
ret[k] = v ^ opad_bytes[k]
return bytes(ret)
def get_hmac(self, key: bytes, text: bytes) -> bytes:
key = self.calculate_key(key)
# key xor ipad
tmp1: bytes = self.key_xor_pad(key, True)
# append text to tmp1
tmp2: bytes = tmp1 + text
# hash tmp2
hashed_tmp2 = self.get_short_data_hash(tmp2)
# key xor opad
tmp3: bytes = self.key_xor_pad(key, False)
# append hashed_tmp2 to tmp3
tmp4: bytes = tmp3 + hashed_tmp2
# hash tmp4
ret: bytes = self.get_short_data_hash(tmp4)
return ret这里需要再次强调,我们不讨论过多数学层面的算法推导。
但是,有一点需要我们记住:
HMAC相较于HASH的复杂填充,使得,即使在证明了MD5存在被碰撞的情况下,HMAC-MD5的安全系数也比纯MD5哈希算法要高。
当然,除非出于兼容性的考虑,否则我们的程序中不应该主动使用HMAC-MD5,而是应该更倾向于使用HMAC-SHA256。
首先回顾一下,AES算法中,其分组长度始终都是128bit,也就是16字节,这一点无论强调多少遍都不为过。
由于CBC模式是一种链式的加密模式,上一个密文块总是作为下一个密文块的IV进行异或。
因此,每次当原始的输入数据有哪怕一个比特的变化时,总是能使得最后一个密文块受到影响。
就这个特性,似乎我们可以每次使用CBC对明文进行填充后加密,取最后一个密文块的数据作为哈希:
import os
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives import padding
from cryptography.hazmat.primitives.ciphers import algorithms, Cipher, modes
def fill_zero_or_truncated(data: bytes, expected_len: int) -> bytes:
if len(data) >= expected_len:
return data[:expected_len]
else:
return data + bytes([0x00 for _ in range(expected_len - len(data))])
def padding_msg(origin_msg: bytes) -> bytes:
# 填充数据
padder = padding.PKCS7(128).padder()
data = padder.update(origin_msg)
data += padder.finalize()
return data
def fake_cmac(origin_msg: bytes, cbc_key: bytes, cbc_iv: bytes, need_padding: bool = True) -> bytes:
cbc_key = fill_zero_or_truncated(cbc_key, 32)
cbc_iv = fill_zero_or_truncated(cbc_iv, 16)
aes_cipher = Cipher(algorithms.AES(cbc_key), modes.CBC(cbc_iv), backend = default_backend())
encryptor = aes_cipher.encryptor()
padded_msg = origin_msg
if need_padding:
padded_msg = padding_msg(origin_msg)
elif len(origin_msg) % 16 != 0:
raise ValueError("padded msg not a multiple of 16")
# print("padded msg:{}".format(list(padded_msg)))
cipher = encryptor.update(padded_msg) + encryptor.finalize()
return cipher[-16:]这里的潜在风险主要针对fake_cmac的实现而言,并非对现有的标准CBC-MAC算法库。
接下来的所有分析仅仅是为了加强对于CBC模式工作原理的理解进而加强对于CBC-MAC的认识。
正常情况下,AES-CBC的工作流程基本可以概括为下图:
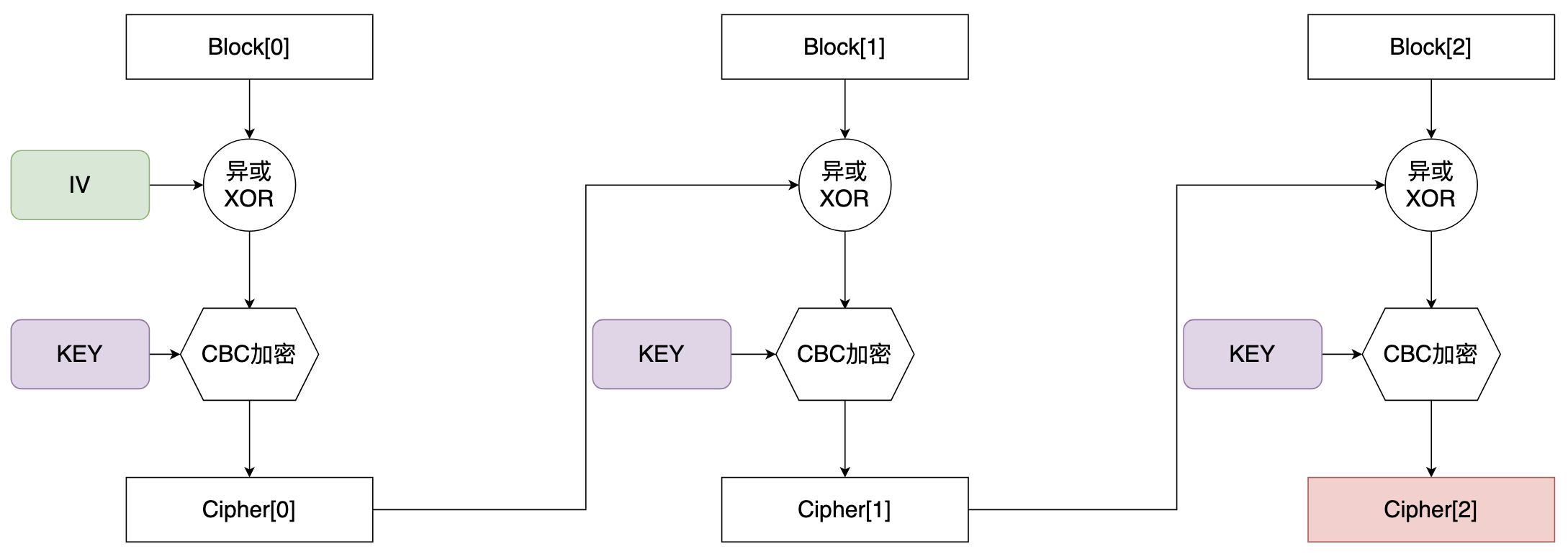
假设明文在被填充后一共有3个分组,则最后的Cipher2分组就是最后输出的哈希值。
在对第一个分组进行异或处理时:
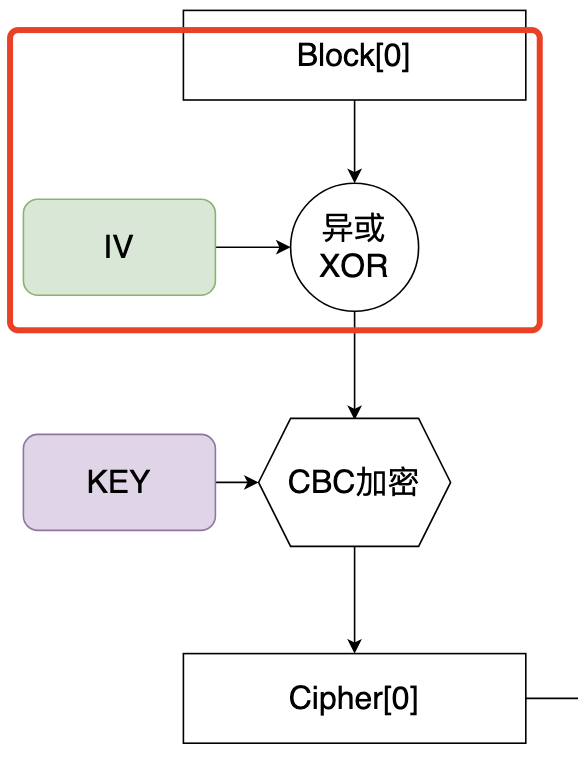
如果IV ^ Block0的值,假设为X,可以被外部指定,也就是说,在原始数据Block0前面,经过一种特殊的填充,是的那一部分数据的CBC运算后得到的值,刚好与IV相同,这个时候,就可能存在:
输入数据不一致,但是得到的fake_cmac值却相同的情况
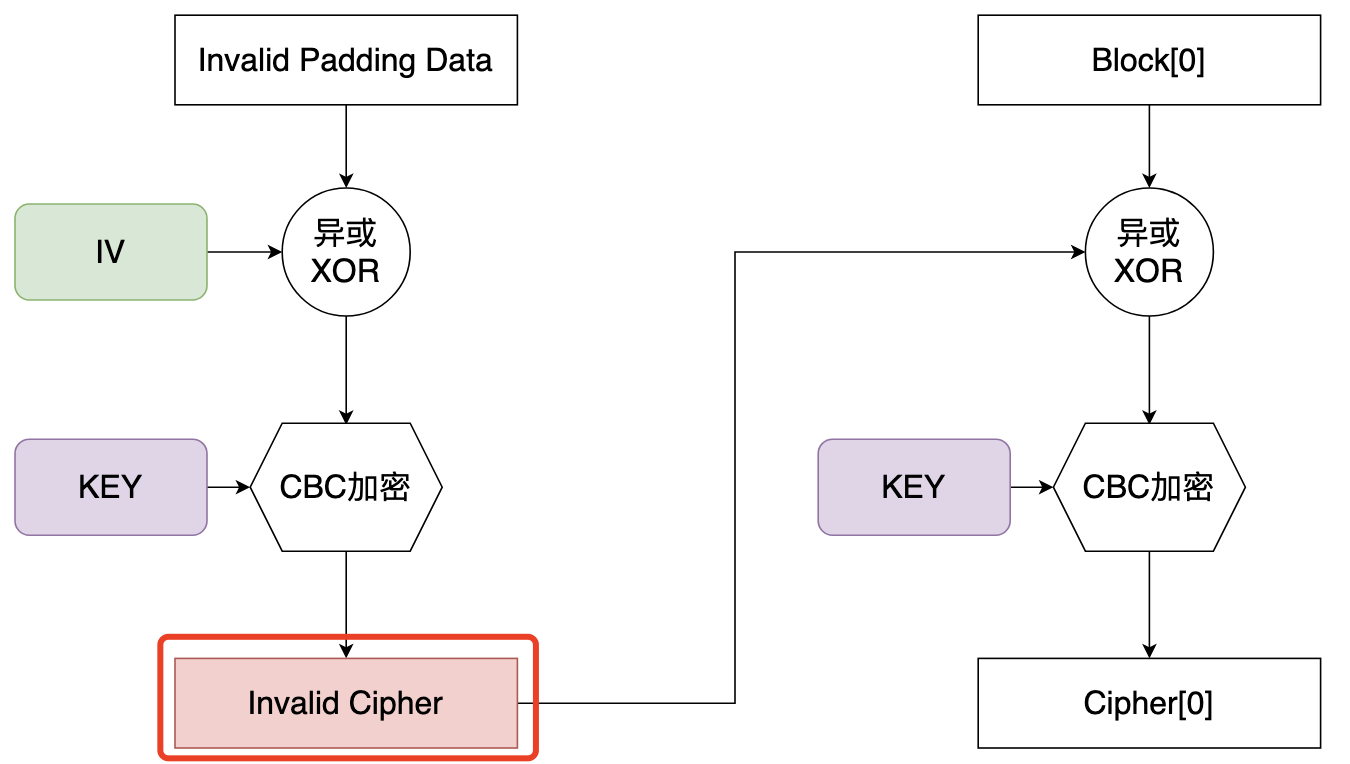
此时有必要回顾一下异或运算的一个性质:
A ^ B == C,则 B == C ^ A
此时,相当于我们如果计算出:
InvalidCipher ^ ? == IV ^ Block0,那么就可以反推出我们的Invalid Padding Data需要怎么设计。
我们希望在加入了attack_msg的信息后,得到的fake_cmac值仍然与计算origin_msg消息一致,
从CBC加密的过程来看,将会是这样子:
IV ^ 攻击数据第一个数据块 ==得到==> 中间值1,然后 Encrypt(key, 中间值1)==得到==> 密attack_msg文块1
密文块1 ^ 攻击数据第二个数据块 ==得到==> 中间值2,然后 Encrypt(key, 中间值2)==得到==> 密文块2
......
密文块n-1 ^ 攻击数据第n个数据块 ==得到==> 中间值n,然后 Encrypt(key, 中间值n)==得到==> 密文块n(attack_block)
attack_block ^ 原始数据第一个密文块 ==得到==> 中间值n+1,然后 Encrypt(key, 中间值n+1)==得到==> 密文块n+1
......
此时,如果我们计算一个值,这个值刚好是一个block size大小,同时满足:
attack_block ^ 原始数据第一个密文块 ^ ? == IV ^ 原始数据第一个密文块
毫无疑问,这里的?就是 attack_block ^ IV
所以对于原始消息,其前面16个字节需要更新为: attack_block ^ IV ^ 原始数据第一个密文块
这样才可以实现:
attack_block ^ attack_block ^ IV ^ 原始数据第一个密文块 == IV ^ 原始数据第一个密文块
def fake_cmac_attack(origin_msg: bytes, cbc_key: bytes, cbc_iv: bytes, try_attack_msg: bytes) -> bytes:
"""
Args:
origin_msg: 正常需要计算fake_cmac的消息
cbc_key: cbc加密的密钥
cbc_iv: cbc加密的iv
try_attack_msg: 想填充的消息,填充后的目的是使得:
fake_cmac(origin_msg, key, iv) == fake_cmac(fake_cmac_attack(xxx), key, iv)
Returns: 返回最终生成的攻击消息
"""
padded_origin_msg = padding_msg(origin_msg)
first_block_origin_msg = padded_origin_msg[:16]
padded_attack_msg = padding_msg(try_attack_msg)
tmp_value = fake_cmac(try_attack_msg, cbc_key, cbc_iv)
modify_block = [0x00 for _ in range(16)]
for i in range(16):
modify_block[i] = tmp_value[i] ^ first_block_origin_msg[i] ^ cbc_iv[i]
# print("modify_block:{}".format(list(modify_block)))
if len(origin_msg) < 16:
return padded_attack_msg + bytes(modify_block)
return padded_attack_msg + bytes(modify_block) + origin_msg[16:len(origin_msg)]攻击数据的性质验证:
def test_fake_cmac_attack(self):
key = os.urandom(32)
# print("key:", list(key))
iv = os.urandom(16)
# print("iv:", list(iv))
origin_msg = os.urandom(64)
# print("msg:", list(origin_msg))
first_block_origin_msg = origin_msg[:16]
# print("first_block_origin_msg:", list(first_block_origin_msg))
try_attack_msg = os.urandom(64)
# print("try_attack_msg:", list(try_attack_msg))
padded_attack_msg = cmac_study.padding_msg(try_attack_msg)
# print("padded_attack_msg:", list(padded_attack_msg))
prepend_msg = cmac_study.fake_cmac_attack(origin_msg, key, iv, try_attack_msg)
# print("prepend_msg:", list(prepend_msg))
'''验证预填充消息的前面部分,应该是攻击数据被pkcs7填充后的值'''
self.assertEqual(prepend_msg[:len(padded_attack_msg)], padded_attack_msg)
attack_msg_hash_value = cmac_study.fake_cmac(try_attack_msg, key, iv)
# print("attack_msg_hash_value:", list(attack_msg_hash_value))
modify_block = [0x00 for _ in range(16)]
for i in range(16):
modify_block[i] = attack_msg_hash_value[i] ^ first_block_origin_msg[i] ^ iv[i]
# print("modify_block:", list(modify_block))
'''验证原始消息的前16个字节的替换值'''
self.assertEqual(bytes(modify_block), prepend_msg[len(padded_attack_msg): len(padded_attack_msg) + 16])
'''原始消息应该只有前16字节被替换'''
self.assertEqual(origin_msg[16:], prepend_msg[len(padded_attack_msg) + 16:])
origin_block = [0x00 for _ in range(16)]
for i in range(16):
origin_block[i] = attack_msg_hash_value[i] ^ modify_block[i] ^ iv[i]
'''验证原始异或值是否符合预期'''
self.assertEqual(bytes(origin_block), first_block_origin_msg)
hash_1 = cmac_study.fake_cmac(prepend_msg, key, iv)
hash_2 = cmac_study.fake_cmac(prepend_msg[len(padded_attack_msg):], key, attack_msg_hash_value)
'''验证对prepend_msg的分块处理是否符合预期'''
self.assertEqual(hash_1, hash_2)
'''验证使用计算后的预处理数据与原始数据,得到相同的cbc哈希值'''
hash_3 = cmac_study.fake_cmac(origin_msg, key, iv)
self.assertEqual(hash_1, hash_3)fake_cmac之所以可以被攻击,其实是因为他完全依赖的分组特性并且没有任何防范措施。
改良方法有一个很简单的方式可以参考,那就是在消息中加上真实的长度数据。
感兴趣的同学可以自己手动试验下。
如果在使用CBC-MAC时,也同时会使用AES-CBC做加密运算,那么这里建议两种的密钥不要复用。
使用CBC-MAC时,IV应该尽量固定为0x00。
任何情况下,在生产环境中,都要使用标准密码库中的CBC-MAC接口,而非自己手动实现的接口。
