

背景:业务在使用ES过程中频繁遇到集群Yellow或Red的场景,若对于ES不是很了解,针对繁多的异常场景经常无从下手。本文重点列举了一下健康值异常时的排查方式以及从代码中梳理了常见的问题场景。
篇幅过长,后续问题出现可以获取Explain结果关键词(不带变量),直接来本文搜索。
在阅读本文前,需要对ES集群、索引、分片概念有一定的了解。
集群Yellow代表有副本分片没有分配到节点。副本没分配,读的性能就不如以往好,写基本不受影响。
集群Red代表有主分片没有分配到节点。主分片未分配,那Red索引的读写都会受影响。
集群:GET _cluster/health
索引:GET _cluster/health?pretty&level=indices 或 GET _cat/indices?v
分片:GET _cluster/health?pretty&level=shards 或 GET _cat/shards?v
恢复进展:GET _recovery?pretty 或 GET {索引名}/_recovery?pretty集群是否Green,是否有初始化中的分片,是否有未分配的分片。动态查看便于了解分片恢复的进展。
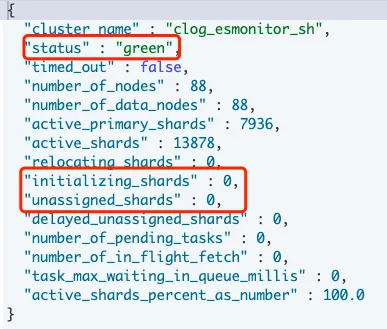
分片层面查看那些索引Or分片异常,确定当前影响情况。
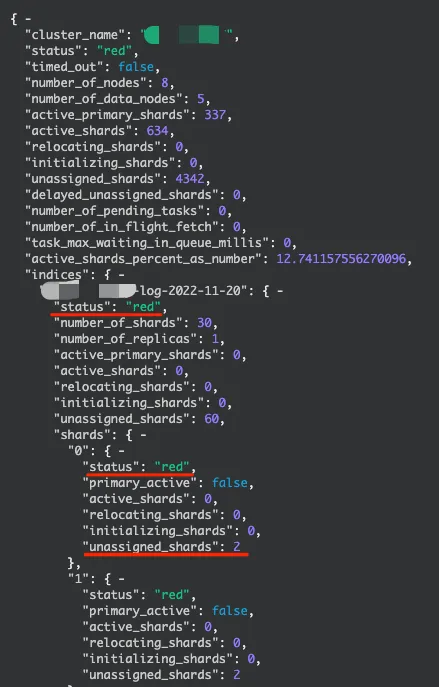
分片恢复或迁移过程中,可通过index.size 、translog等查看恢复进展,一些频繁写入的索引会记录较多translog。一般在索引文件恢复后,会将更新的translog数据写入索引。
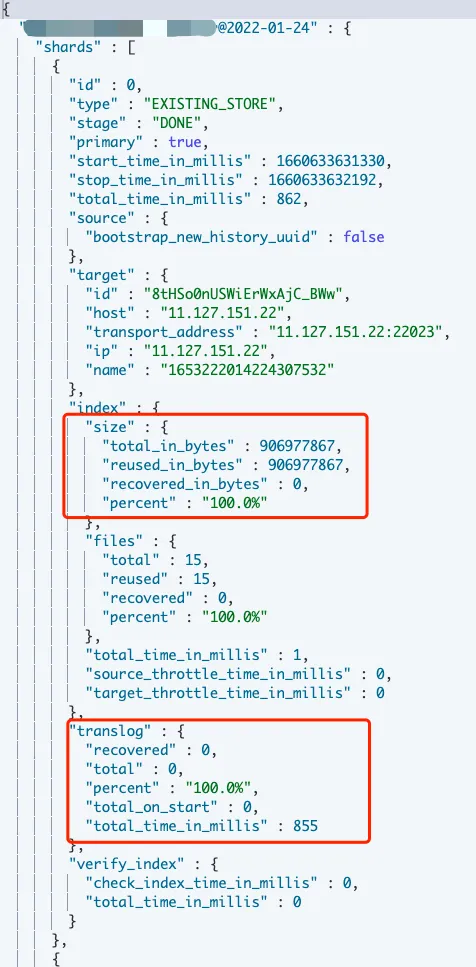
官网提供了解释分片未分配原因的API。官网:cluster-allocation-explain
随机查询分片未分配原因
GET _cluster/allocation/explain
指定分片查询未分配原因
GET _cluster/allocation/explain
{
"index": "my-index-000001",
"shard": 0,
"primary": false
}此处给出一个Demo,如"磁盘水位过高,导致分片无法分配"。下面会展开分析常见的异常场景。
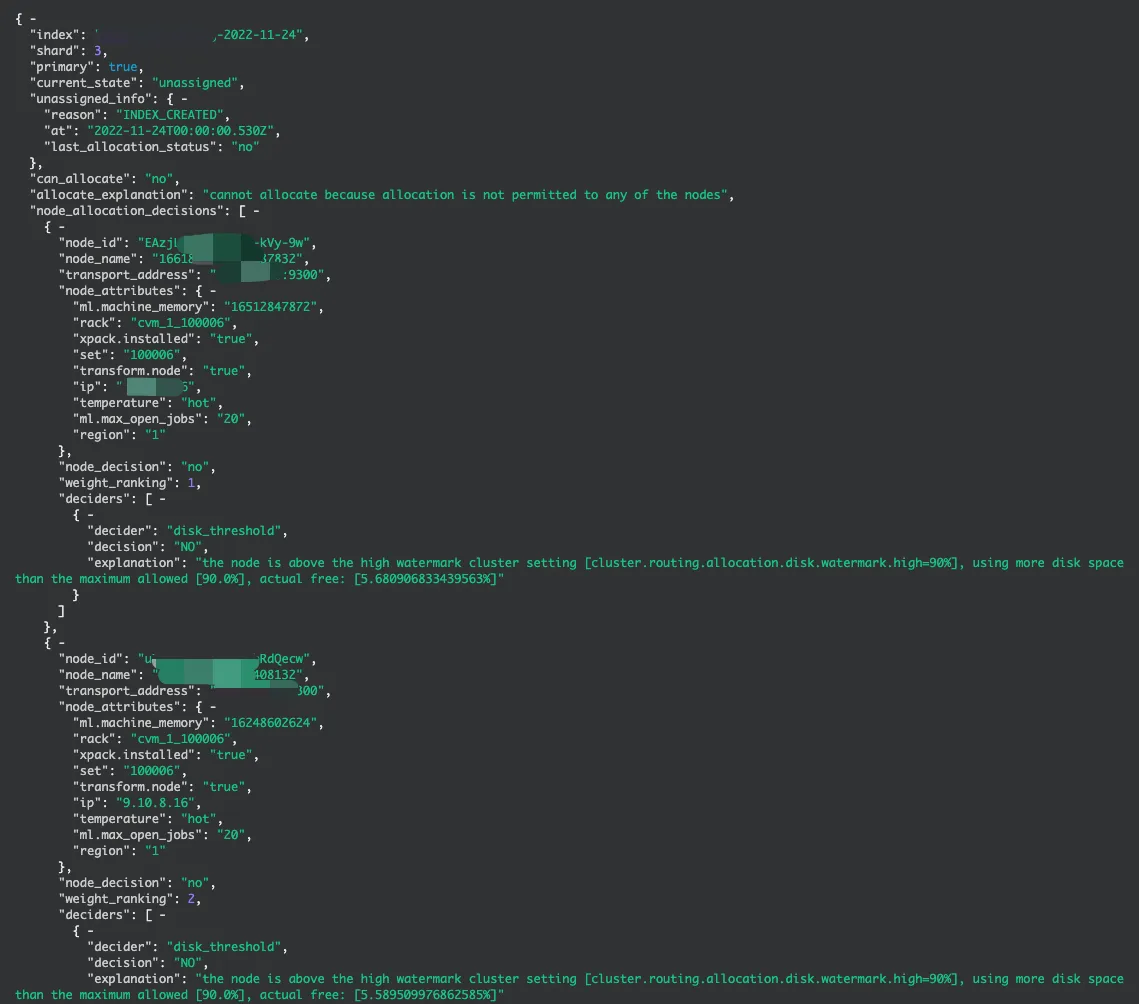
重点看这一段:
{
"deciders":[
{
"decider":"disk_threshold",
"decision":"NO",
"explanation":"the node is above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=90%], using more disk space than the maximum allowed [90.0%], actual free: [5.680906833439563%]"
}
]
}Desiders中会展示分片没有分配到节点的具体原因。
Desider可以理解为集中未分配原因的大类。下文会具体描述
Decision可以理解为此诊断项是否通过,No代表有问题,下文会具体描述
Explanation是此问题的具体解释。拿到此解释关键词后可以在本文直接搜索。
这个案例的问题在于,the node is above the high watermark cluster setting,节点磁盘利用率水位超过90%,主分片无法正常分配,引起索引Red。
本段我们从_cluster/allocation/explain返回结果结合ElasticSearch源码列举常见的分片未分配原因及解决方案
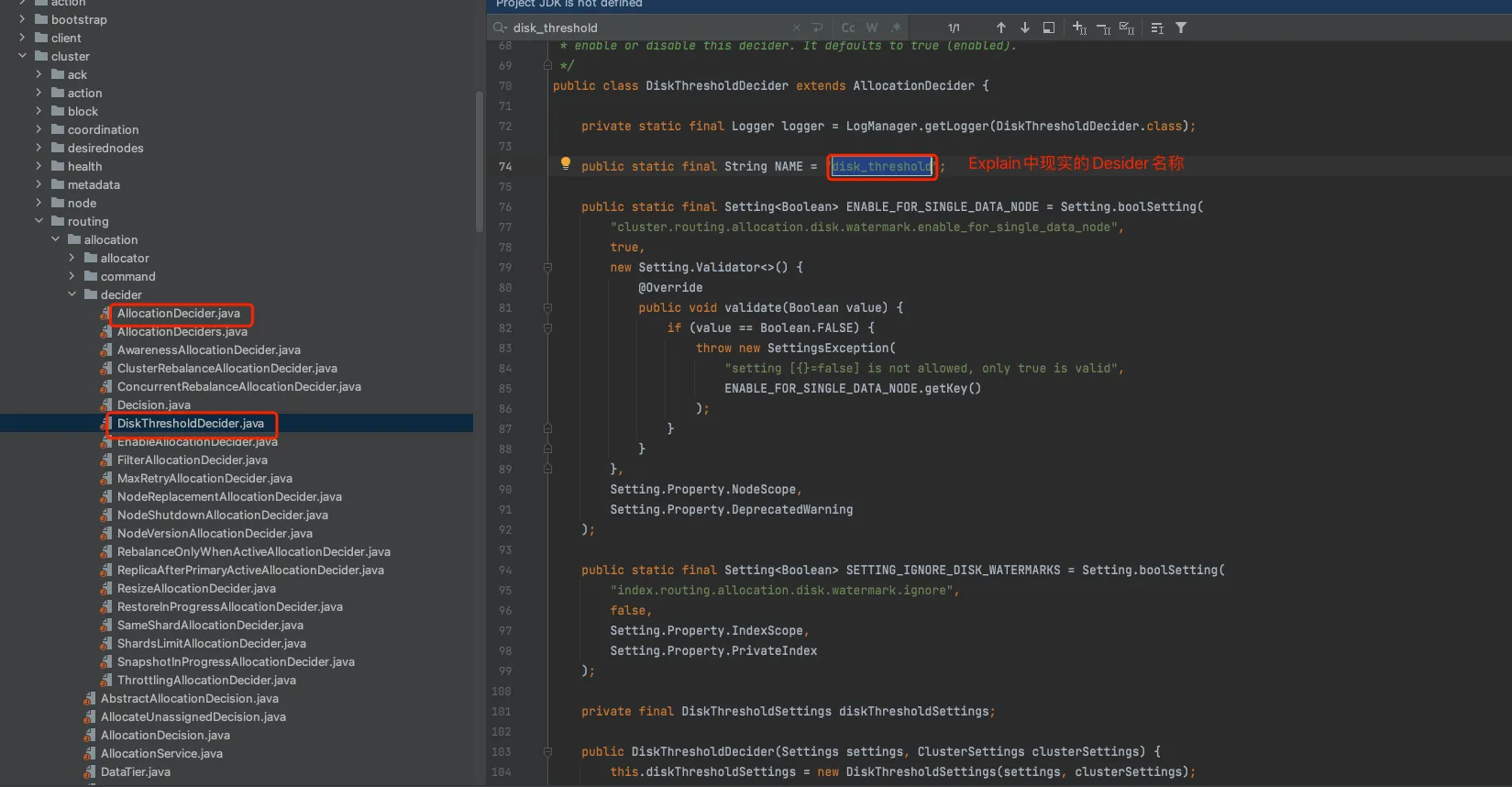
从第一段3.1的结果解析Demo中我们可以看到返回结果中会列举分片不能分配的Deciders,其中包含了desider、decision、explannation。
结合图五可以看到这些概念刚好对应了代码中的AllocationDecider及其子类。
结合图六可以看到decision对应了代码中的AllocationDecider及其子类。
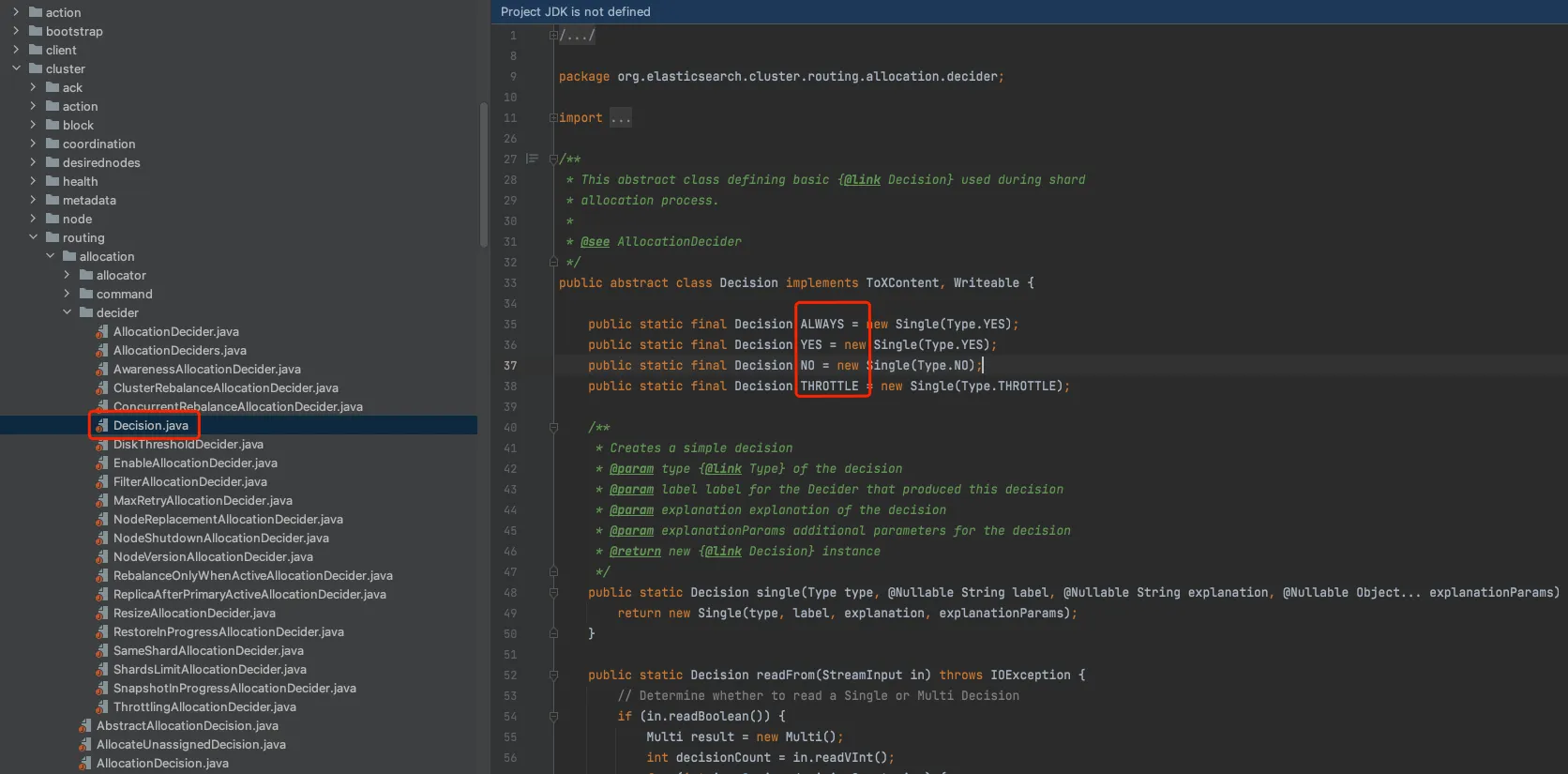
左面目录中的子类全部实现继承自”AllocationDecider”类,经过各种条件判断后,决策是否达到分配条件。
YES : 满足条件
NO : 不满足条件(重点关注这个)
THROTTLE: 限流 此表可作为工具表,当Explain出现如下desider时可以搜索排查。
Desider | 类名 | 解释 |
|---|---|---|
awareness | AwarenessAllocationDecider | Awareness 主要用来控制副本的分配,用户做一些跨机架、机房、可用区的高可用。 站长素材网的多可用区便由Awareness进行划Zone控制。 |
cluster_rebalance | ClusterRebalanceAllocationDecider | cluster_rebalance主要用来判断集群在什么场景下可以进行分片均衡。 由配置项进行决定:cluster.routing.allocation.allow_rebalance indices_primaries_active 所有索引主分片active时可均衡分片 indices_all_active 所有索引所有分片active时可均衡(green时) always 一个分片的副本集active时即可均衡。 |
concurrent_rebalance | ConcurrentRebalanceAllocationDecider | 用来控制集群正在进行的relocating分片数量,控制并发。防止集群高负载。 cluster.routing.allocation.cluster_concurrent_rebalance 通过此参数控制,如果感觉集群恢复太慢,且集群各项指标负载不高,可以适当调大并发,加快恢复速度。 |
disk_threshold | DiskThresholdDecider | 此场景高频出现 检查节点是否有足够剩余磁盘分配分片(很多客户不清楚ES的磁盘控制逻辑,导致集群写入受到影响) cluster.routing.allocation.disk.watermark.low/high/flood来进行磁盘控制,防止写入突增导致磁盘写满 当集群磁盘使用率超过85%:会导致新的分片无法分配。 当集群磁盘使用率超过90%:Elasticsearch 会尝试将对应节点中的分片迁移到其他磁盘使用率比较低的数据节点中。 当集群磁盘使用率超过95%:系统会对 Elasticsearch 集群中对应节点里每个索引强制设置 read_only_allow_delete 属性,此时该节点上的所有索引将无法写入数据,只能读取和删除对应索引。 |
enable | EnableAllocationDecider | 用于控制集群是否可以进行分片迁移,当集群维护或者节点维护不希望分片自动迁移到其他节点导致集群高负载时可以通过此参数进行控制。此参数索引级别优先级高于集群级别。 CLUSTER_ROUTING_ALLOCATION_ENABLE_SETTING CLUSTER_ROUTING_REBALANCE_ENABLE_SETTING INDEX_ROUTING_ALLOCATION_ENABLE_SETTING INDEX_ROUTING_REBALANCE_ENABLE_SETTING 配置值: NONE - no shard allocation is allowed.(禁止分片分配)NEW_PRIMARIES - only primary shards of new indices are allowed to be allocated(只有新建索引主分片可以分配)PRIMARIES - only primary shards are allowed to be allocated(只有主分片可以分配)ALL- all shards are allowed to be allocated(所有分片可以分配) |
filter | FilterAllocationDecider | 此场景高频出现 用来控制索引设置的节点条件: cluster.routing.allocation.include.{attribute}:将分片分配给其节点{attribute}至少具有一个逗号分隔值的节点。cluster.routing.allocation.require.{attribute}:仅将分片分配给{attribute}具有所有逗号分隔值的节点。cluster.routing.allocation.exclude.{attribute}:请勿将分片分配给{attribute}具有任何逗号分隔值的节点 举例: PUT _cluster / settings { “ transient” :{ “ cluster.routing.allocation.exclude._ip” :“ 10.0.0.1” } } |
max_retry | MaxRetryAllocationDecider | 防止分片不断重试分配,在重试达到一定次数后,集群会停止此分片的分配。在Explain当中记录达到最大重试次数。 参数为:index.allocation.max_retry 出现此类场景我们可以尝试让集群重新发起分配: PUT _cluster/reroute?retry_failed=true |
node_shutdown | NodeShutdownAllocationDecider | 这个出现不多,自行看原文^_^ An allocation decider that prevents shards from being allocated to anode that is in the process of shutting down.In short: No shards can be allocated to, or remain on, a node which isshutting down for removal. Primary shards cannot be allocated to, or remainon, a node which is shutting down for restart. |
node_version | NodeVersionAllocationDecider | 这个出现不多,自行看原文^_^ An allocation decider that prevents relocation or allocation from nodes that might not be version compatible. If we relocate from a node that runs a newer version than the node we relocate to this might cause {@link org.apache.lucene.index.IndexFormatTooNewException} on the lowest level since it might have already written segments that use a new postings format or codec that is not available on the target node. |
rebalance_only_when_active | RebalanceOnlyWhenActiveAllocationDecider | Only allow rebalancing when all shards are active within the shard replication group |
replica_after_primary_active | ReplicaAfterPrimaryActiveAllocationDecider | 只有主分片Active时才允许副本分片进行分配 |
resize | ResizeAllocationDecider | resize的索引主分片必须和目标索引主分片在同一节点。 |
restore_in_progress | RestoreInProgressAllocationDecider | 防止分片从快照恢复失败,若恢复失败禁止分配 |
same_shard | SameShardAllocationDecider | 此场景高频出现: 防止同一个副本集的分片分布在同一个节点 举例:如集群有3个节点。索引设置了1主3副。以0号分片为例,有1个主分片和3个副本分片。共4个0号分片,一个节点一个分片,势必会有一个分片无法分配,因为单节点不允许有两个同号分片。如果分布在同一个节点,就失去了副本分片的容错意义。 |
shards_limit | ShardsLimitAllocationDecider | ES中为了防止单个索引在某些节点上分片数过多,引起负载不均。默认增加了单节点分片上限。 cluster.routing.allocation.total_shards_per_node |
snapshot_in_progress | SnapshotInProgressAllocationDecider | 防止正在从快照恢复中的分片被迁移 |
throttling | ThrottlingAllocationDecider | 控制分片迁移或者初始化的并发及速度 cluster.routing.allocation.node_initial_primaries_recoveries 控制集群初始化的并发,默认为4 cluster.routing.allocation.node_concurrent_recoveries控制单个节点初始化并发,默认为2 一般集群恢复过程中,为了限制恢复速度,此时去explain查看未分配原因,可以看到此条提示。 只要现在集群正在进行分片恢复和分配过程中,可以耐心等待,或者调整并发速度。 |
enable EnableAllocationDecider 用于控制集群是否可以进行分片迁移,当集群维护或者节点维护不希望分片自动迁移到其他节点导致集群高负载时可以通过此参数进行控制。此参数索引级别优先级高于集群级别。 CLUSTER_ROUTING_ALLOCATION_ENABLE_SETTING CLUSTER_ROUTING_REBALANCE_ENABLE_SETTING INDEX_ROUTING_ALLOCATION_ENABLE_SETTING INDEX_ROUTING_REBALANCE_ENABLE_SETTING 配置值: NONE - no shard allocation is allowed.(禁止分片分配) NEW_PRIMARIES - only primary shards of new indices are allowed to be allocated(只有新建索引主分片可以分配) PRIMARIES - only primary shards are allowed to be allocated(只有主分片可以分配) ALL- all shards are allowed to be allocated(所有分片可以分配) filter FilterAllocationDecider 此场景高频出现 用来控制索引设置的节点条件: cluster.routing.allocation.include.{attribute}:将分片分配给其节点{attribute}至少具有一个逗号分隔值的节点。 cluster.routing.allocation.require.{attribute}:仅将分片分配给{attribute}具有所有逗号分隔值的节点。 cluster.routing.allocation.exclude.{attribute}:请勿将分片分配给{attribute}具有任何逗号分隔值的节点 举例: PUT _cluster / settings { “ transient” :{ “ cluster.routing.allocation.exclude._ip” :“ 10.0.0.1” } } max_retry MaxRetryAllocationDecider 防止分片不断重试分配,在重试达到一定次数后,集群会停止此分片的分配。在Explain当中记录达到最大重试次数。 参数为:index.allocation.max_retry 出现此类场景我们可以尝试让集群重新发起分配: PUT _cluster/reroute?retry_failed=true node_shutdown NodeShutdownAllocationDecider 这个出现不多,自行看原文^_^ An allocation decider that prevents shards from being allocated to a node that is in the process of shutting down. In short: No shards can be allocated to, or remain on, a node which is shutting down for removal. Primary shards cannot be allocated to, or remain on, a node which is shutting down for restart. node_version NodeVersionAllocationDecider 这个出现不多,自行看原文^_^ An allocation decider that prevents relocation or allocation from nodes that might not be version compatible. If we relocate from a node that runs a newer version than the node we relocate to this might cause {@link org.apache.lucene.index.IndexFormatTooNewException} on the lowest level since it might have already written segments that use a new postings format or codec that is not available on the target node. rebalance_only_when_active RebalanceOnlyWhenActiveAllocationDecider Only allow rebalancing when all shards are active within the shard replication group replica_after_primary_active ReplicaAfterPrimaryActiveAllocationDecider 只有主分片Active时才允许副本分片进行分配 resize ResizeAllocationDecider resize的索引主分片必须和目标索引主分片在同一节点。 restore_in_progress RestoreInProgressAllocationDecider 防止分片从快照恢复失败,若恢复失败禁止分配 same_shard SameShardAllocationDecider 此场景高频出现: 防止同一个副本集的分片分布在同一个节点 举例:如集群有3个节点。索引设置了1主3副。以0号分片为例,有1个主分片和3个副本分片。共4个0号分片,一个节点一个分片,势必会有一个分片无法分配,因为单节点不允许有两个同号分片。如果分布在同一个节点,就失去了副本分片的容错意义。 shards_limit ShardsLimitAllocationDecider ES中为了防止单个索引在某些节点上分片数过多,引起负载不均。默认增加了单节点分片上限。 cluster.routing.allocation.total_shards_per_node snapshot_in_progress SnapshotInProgressAllocationDecider 防止正在从快照恢复中的分片被迁移 throttling ThrottlingAllocationDecider 控制分片迁移或者初始化的并发及速度 cluster.routing.allocation.node_initial_primaries_recoveries 控制集群初始化的并发,默认为4 cluster.routing.allocation.node_concurrent_recoveries控制单个节点初始化并发,默认为2 一般集群恢复过程中,为了限制恢复速度,此时去explain查看未分配原因,可以看到此条提示。 只要现在集群正在进行分片恢复和分配过程中,可以耐心等待,或者调整并发速度。
开始之前介绍一下AllocationDecider的几种方法
canRebalance 控制是否可以做均衡
canAllocate 控制分片是否可以分配到节点
canRemain 控制分片是否可以留在节点
健康值问题大多数与canAllocate相关,我们下面重点介绍canAllocate涉及的相关案例。
public abstract class AllocationDecider {
/**
* Returns a {@link Decision} whether the given shard routing can be
* re-balanced to the given allocation. The default is
* {@link Decision#ALWAYS}.
*/
public Decision canRebalance(ShardRouting shardRouting, RoutingAllocation allocation) {
return Decision.ALWAYS;
}
/**
* Returns a {@link Decision} whether the given shard routing can be
* allocated on the given node. The default is {@link Decision#ALWAYS}.
*/
public Decision canAllocate(ShardRouting shardRouting, RoutingNode node, RoutingAllocation allocation) {
return Decision.ALWAYS;
}
/**
* Returns a {@link Decision} whether the given shard routing can be remain
* on the given node. The default is {@link Decision#ALWAYS}.
*/
public Decision canRemain(IndexMetadata indexMetadata, ShardRouting shardRouting, RoutingNode node, RoutingAllocation allocation) {
return Decision.ALWAYS;
}以下案例中均以Explain API的explanation关键词为例。
简介:Awareness 主要用来控制副本的分配,用户做一些跨机架、机房、可用区的高可用。站长素材网的多可用区便由Awareness进行划Zone控制。官网传送门
场景案例:
场景1:
there are [%d] copies of this shard and [%d] values for attribute [%s] (%s from nodes in the cluster and %s) so there may be at most [%d] copies of this shard allocated to nodes with each value, but (including this copy) there
would be [%d] copies allocated to nodes with [node.attr.%s: %s]
场景2:
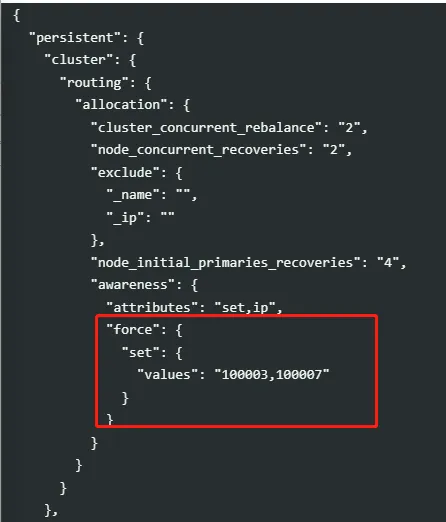
node does not contain the awareness attribute [%s]; required attributes cluster setting [%s=%s]实际案例:
there are [2] copies of this shard and [2] values for attribute [set] ([100003] from nodes in the cluster and [100003, 100007] from forced awareness) so there may be at most [1] copies of this shard allocated to nodes with each value, but (including this copy) there would be [2] copies allocated to nodes with [node.attr.set: 100003]解析:某集群在进行可用区迁移过程中出现报错,同一个Set(100003 北京3区)不允许有两个同样分片。导致有一个分片为Uassign状态,集群yellow。迁移终止。
此场景出现主要是因为100007的节点已经下线,但是集群中的配置未下掉。
方案:将集群配置中的awareness属性设置为null,即可解决。(PS这里具体设置为什么值需要根据实际的业务场景进行设置。)
简介:cluster_rebalance主要用来判断集群在什么场景下可以进行分片均衡。由配置项进行决定:cluster.routing.allocation.allow_rebalance
此Desider主要实现了canRebalance方法,重点侧重于均衡控制。一般不是健康值异常的直接原因。
场景案例:
场景1
the cluster has unassigned primary shards and cluster setting [cluster.routing.allocation.allow_rebalance] is set to [indices_primaries_active]
场景2
the cluster has inactive primary shards and cluster setting [cluster.routing.allocation.allow_rebalance] is set to [indices_primaries_active]
场景3
the cluster has unassigned shards and cluster setting and cluster setting [cluster.routing.allocation.allow_rebalance] is set to [indices_all_active]
场景4
the cluster has inactive shards and cluster setting [cluster.routing.allocation.allow_rebalance] is set to [indices_all_active]解析:
因为集群设置为不同的rebalance参数,导致当有未分配分片时或inactive分片时,集群无法进行Rebalance。
此时需要先解决未分配的分片问题或者修改集群配置才能集群均衡迁移。
简介:用来控制集群正在进行的relocating分片数量,控制并发。防止集群高负载。
通过参数cluster.routing.allocation.cluster_concurrent_rebalance控制,如果感觉集群恢复太慢,且集群各项指标负载不高,可以适当调大并发,加快恢复速度。
此Desider主要实现了canRebalance方法,重点侧重于均衡控制。一般不是健康值异常的直接原因。
案例:
reached the limit of concurrently rebalancing shards [%d], cluster setting [%s=%d]解析:
当前relocating的并发分片数量达到了集群限制值,可以根据磁盘IO、CPU、内存等负载信息判断是否可以加快速度
如:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.node_concurrent_incoming_recoveries": "4",
"cluster.routing.allocation.node_concurrent_outgoing_recoveries": "4",
"cluster.routing.allocation.node_concurrent_recoveries": "20",
"cluster.routing.allocation.cluster_concurrent_rebalance": "20",
"cluster.routing.allocation.node_initial_primaries_recoveries": "20",
"indices.recovery.max_bytes_per_sec": "200mb"
},
"transient": {
"cluster.routing.allocation.node_concurrent_incoming_recoveries": "4",
"cluster.routing.allocation.node_concurrent_outgoing_recoveries": "4",
"cluster.routing.allocation.node_concurrent_recoveries": "20",
"cluster.routing.allocation.cluster_concurrent_rebalance": "20",
"indices.recovery.max_bytes_per_sec": "200mb"
}
}简介:
此Desider是运营过程中发现的出现频率最高的。ES在集群配置中给了三个水位的设置。
cluster.routing.allocation.disk.watermark.low 默认85%
cluster.routing.allocation.disk.watermark.high 默认90%
cluster.routing.allocation.disk.watermark.flood 默认95%
场景案例:
canAllocate:
场景1:
the node is above the low watermark cluster setting [%s], having less than the minimum required [%s] free space, actual free: [%s], actual used: [%s]
解析:节点磁盘利用率超过集群low水位的设置值,会导致索引的副本分片无法分配,集群yellow
场景2:
the node is above the high watermark cluster setting [%s], having less than the minimum required [%s] free space, actual free: [%s], actual used: [%s]
解析:节点磁盘利用率超过集群high水位的设置值,会导致索引主分片无法分配,集群Red
场景3:
allocating the shard to this node will bring the node above the high watermark cluster setting [%s] and cause it to have less than the minimum required [%s] of free space (free: [%s], used: [%s], estimated shard size: [%s])
解析:分片分配到目标节点会导致及诶单磁盘利用率超过高水位。禁止分配。
canRemain(非allocation,此处只列举,不分析):
例4:
the shard cannot remain on this node because the node has fewer free bytes remaining than the total size of all incoming shards: free space [%s], relocating shards [%s]
例5:
the shard cannot remain on this node because it is above the high watermark cluster setting [%s] and there is less than the required [%s] free space on node, actual free: [%s], actual used: [%s]
例6:
the node has fewer free bytes remaining than the total size of all incoming shards: free space [%sB], relocating shards [%sB]方案:
1-删除部分历史数据降低磁盘占用。
2-去掉不分非重要索引的副本。
3-如是冷热集群,可以考虑提前降冷
4-控制台扩容磁盘(需要集群为Green状态, 可以临时调大水位让分片可以分配)。
5-增加节点数(涉及分片迁移,可能会比较慢)
简介:
用于控制集群是否可以进行分片迁移,当集群维护或者节点维护不希望分片自动迁移到其他节点导致集群高负载时可以通过此参数进行控制。此参数索引级别优先级高于集群级别。
cluster.routing.allocation.enable cluster.routing.rebalance.enable index.routing.allocation.enable index.routing.rebalance.enable
配置值:
NONE - no shard allocation is allowed.(禁止分片分配) NEW_PRIMARIES - only primary shards of new indices are allowed to be allocated(只有新建索引主分片可以分配) PRIMARIES - only primary shards are allowed to be allocated(只有主分片可以分配) ALL- all shards are allowed to be allocated(所有分片可以分配)
场景案例1:
no allocations are allowed due to cluster setting [cluster.routing.allocation.enable=none]用户之前设置了禁止集群分片分配,No shard allocation is allowed,忘记打开。
当节点离线、索引创建等需要重新分配分片的场景出现时,便会导致索引分片无法分配。集群出现Yellow或者Red。
方案:
可以通过修改参数来解决:
PUT _cluster/settings
{
"transient":{
"cluster.routing.allocation.enable":"all"
}
}场景案例2:
canAllocate:
non-new primary allocations are forbidden due to %s
replica allocations are forbidden due to %s
no rebalancing is allowed due to %s
以上三种场景也是因为不同配置导致的不同报错内容,会导致uassgin分片无法正常分配,影响集群健康值。
canRebalance:
no rebalancing is allowed due to %s
replica rebalancing is forbidden due to %s
primary rebalancing is forbidden due to %s
以上三种场景影响集群重新均衡。简介:
此Desider用来控制索引设置的节点条件:
cluster.routing.allocation.include.{attribute}:将分片分配给其节点{attribute}至少具有一个逗号分隔值的节点。 cluster.routing.allocation.require.{attribute}:仅将分片分配给{attribute}具有所有逗号分隔值的节点。 cluster.routing.allocation.exclude.{attribute}:请勿将分片分配给{attribute}具有任何逗号分隔值的节点
场景案例:
索引3种场景
node does not match index setting [%s] filters [%s]
node does not match index setting [%s] filters [%s]
node matches index setting [%s] filters [%s]
集群3种场景
node does not match cluster setting [%s] filters [%s]
node does not cluster setting [%s] filters [%s]
node matches cluster setting [%s] filters [%s]实际案例:
node does not match index setting [index.routing.allocation.require] filters [temperature:\"warm\",_id:\"xxxxxxxxxxxx\"]"解析:
如实际案例中展示,索引设置了temperature为warm的settings。表示这个这个索引希望落到冷节点上。但是当前集群并无warm节点。所以分片无法分配,导致集群Yellow或Red。
方案:
合理调整索引或集群的设置,使节点属性满足集群或索引的设置要求。此案例需要去掉索引的warm配置,或者增加冷节点。
简介:
防止分片不断重试分配,在重试达到一定次数后,集群会停止此分片的分配。在Explain当中记录达到最大重试次数。
参数为:index.allocation.max_retry 。出现此类场景我们可以尝试让集群重新发起分配:PUT _cluster/reroute?retry_failed=true
场景案例:
场景1:
shard has exceeded the maximum number of retries [%d] on failed allocation attempts - manually call [/_cluster/reroute?retry_failed=true] to retry, [%s]
场景2:
shard has exceeded the maximum number of retries [%d] on failed relocation attempts - manually call [/_cluster/reroute?retry_failed=true] to retry, [%s]实际案例:
shard has exceeded the maximum number of retries [5] on failed allocation attempts - manually call [/_cluster/reroute?retry_failed=true] to retry, [unassigned_info[[reason=ALLOCATION_FAILED], at[2022-09-20T17:54:21.337Z], failed_attempts[5], failed_nodes[[xxxxxxx]], delayed=false, details[failed shard on node [xxxxxx]: failed to create shard, failure IOException[failed to obtain in-memory shard lock]; nested: ShardLockObtainFailedException[[xxxxxxxxx][2]: obtaining shard lock timed out after 5000ms, previous lock details: [shard creation] trying to lock for [shard creation]]; ], allocation_status[deciders_no]]]解析:
分片分配由于各种原因导致达到最大重试次数。需要手工发起重新分配。
方案:
PUT _cluster/reroute?retry_failed=true简介:
防止同一个副本集的分片分布在同一个节点,举例:如集群有3个节点。索引设置了1主3副。以0号分片为例,有1个主分片和3个副本分片。共4个0号分片,一个节点一个分片,势必会有一个分片无法分配,因为单节点不允许有两个同号分片。如果分布在同一个节点,就失去了副本分片的容错意义。
场景案例:
场景1:
cannot allocate to node [%s] because a copy of this shard is already allocated to node [%s] with the same host address [%s] and [%s] is [true] which forbids more than one node on each host from holding a copy of this shard
场景2:
this shard is already allocated to this node []
场景3:
a copy of this shard is already allocated to this node []解析:
如场景3,一个同样的分片已经存在于此节点。
方案:
需要扩容节点数量,或者减少副本数量。
例:调整成0副本
PUT mytest
{
"settings":{
"number_of_replicas":0
}
}简介:
ES中为了防止单个索引在某些节点上分片数过多,引起负载不均,默认增加了单节点分片上限。
参数:
cluster.routing.allocation.total_shards_per_node 每个索引平均节点最大分片数量
index.routing.allocation.total_shards_per_node 某索引平均节点最大分片数量
场景案例:
场景1:
too many shards [%d] allocated to this node, cluster setting [%s=%d]
场景2:
too many shards [%d] allocated to this node for index [%s], index setting [%s=%d]解析:
场景1,集群可以设置cluster.routing.allocation.total_shards_per_node配置,控制集群每个索引在节点上平均最大可分配分片,
场景2,索引可以设置index.routing.allocation.total_shards_per_node配置,控制每个节点此索引最大可分配的分片数。如果索引有11个分片,集群有5个节点,设置索引每个节点最大2个分片。就会导致有1个分片无法分配。
方案:
索引级别优先级高于集群级别:
PUT {索引名}/_settings
{
"settings":{
"index":{
"routing":{
"allocation":{
"total_shards_per_node":"2"
}
}
}
}
}简介:
控制分片迁移或者初始化的并发及速度
参数:cluster.routing.allocation.node_initial_primaries_recoveries 控制集群初始化的并发,默认为4
参数:cluster.routing.allocation.node_concurrent_recoveries控制单个节点初始化并发,默认为2
一般集群恢复过程中,为了限制恢复速度,此时去explain查看未分配原因,可以看到此条提示。
只要现在集群正在进行分片恢复和分配过程中,可以耐心等待,或者调整并发速度。
案例:
场景1:
reached the limit of ongoing initial primary recoveries [%d], cluster setting [%s=%d]
场景2:
reached the limit of incoming shard recoveries [%d], cluster setting [%s=%d] (can also be set via [%s])
场景3:
primary shard for this replica is not yet active
场景4:
reached the limit of outgoing shard recoveries [%d] on the node [%s] which holds the primary,cluster setting [%s=%d] (can also be set via [%s])解析:
并发达到了集群限制,可以通过速度控制参数调整恢复或迁移并发。
方案:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.node_concurrent_incoming_recoveries": "4",
"cluster.routing.allocation.node_concurrent_outgoing_recoveries": "4",
"cluster.routing.allocation.node_concurrent_recoveries": "20",
"cluster.routing.allocation.cluster_concurrent_rebalance": "20",
"cluster.routing.allocation.node_initial_primaries_recoveries": "20",
"indices.recovery.max_bytes_per_sec": "200mb"
},
"transient": {
"cluster.routing.allocation.node_concurrent_incoming_recoveries": "4",
"cluster.routing.allocation.node_concurrent_outgoing_recoveries": "4",
"cluster.routing.allocation.node_concurrent_recoveries": "20",
"cluster.routing.allocation.cluster_concurrent_rebalance": "20",
"indices.recovery.max_bytes_per_sec": "200mb"
}
}ES已经把分片未分配的原因都以Explain的方式准备好,遇到健康值问题不要担心,一条GET /_cluster/allocation/explain可以帮助我们获取到具体原因。
